DuckDB -- table的存储格式
本文将介绍DuckDB是如何存储它的表结构,本文仅涉及表结构,其他对于理解表结构无关的内容会进行忽略或者一笔带过。
前置知识
Block Type
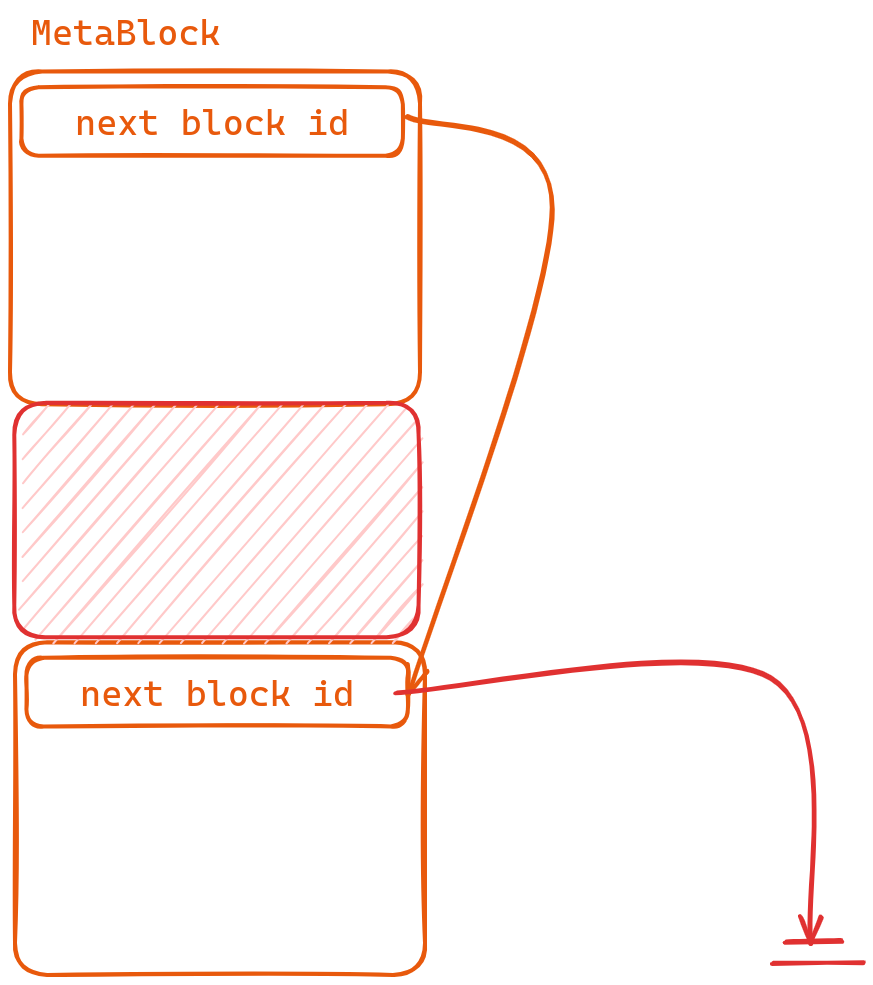
DuckDB与其他数据库不同,它将所有的信息都存储在了同一个文件中。文件之中使用Block进行管理,Block分为MetaBlock以及DataBlock
DataBlock即为单纯的一个BlockMetaBlock是一个Block List,它的头8个字节表示next_block_id。因此如果内容过多,我们可以使用这样一个Block list来存储。
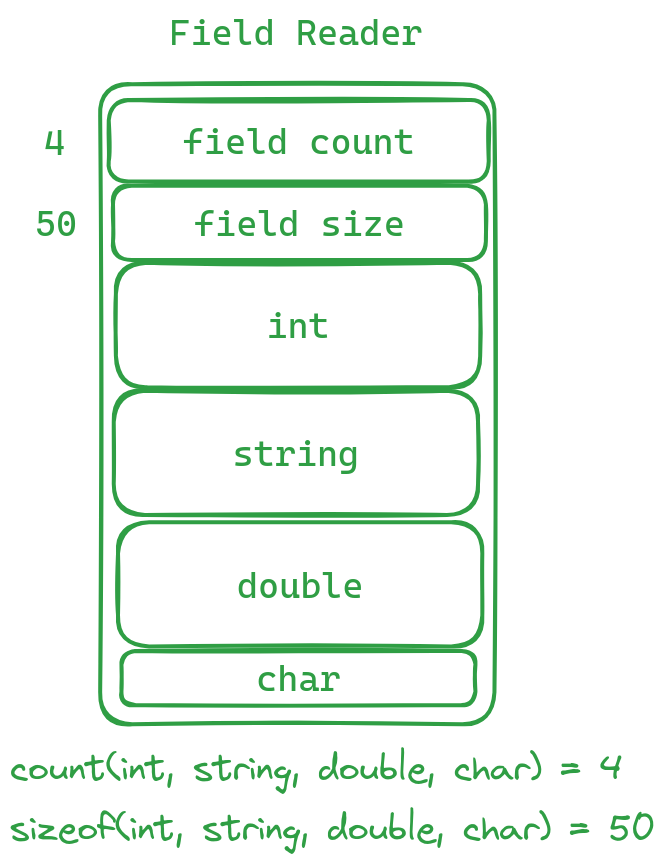
Field Reader
我们有时在一个Block中读取数据时,会采用Field Reader的方式来进行读取。该Field Reader与表的字段无关,仅仅是在你读取一些数据前,会先读取max_field_count和total_size
max_field_count后续要读取的字段个数total_size后续要读取的总字节数。
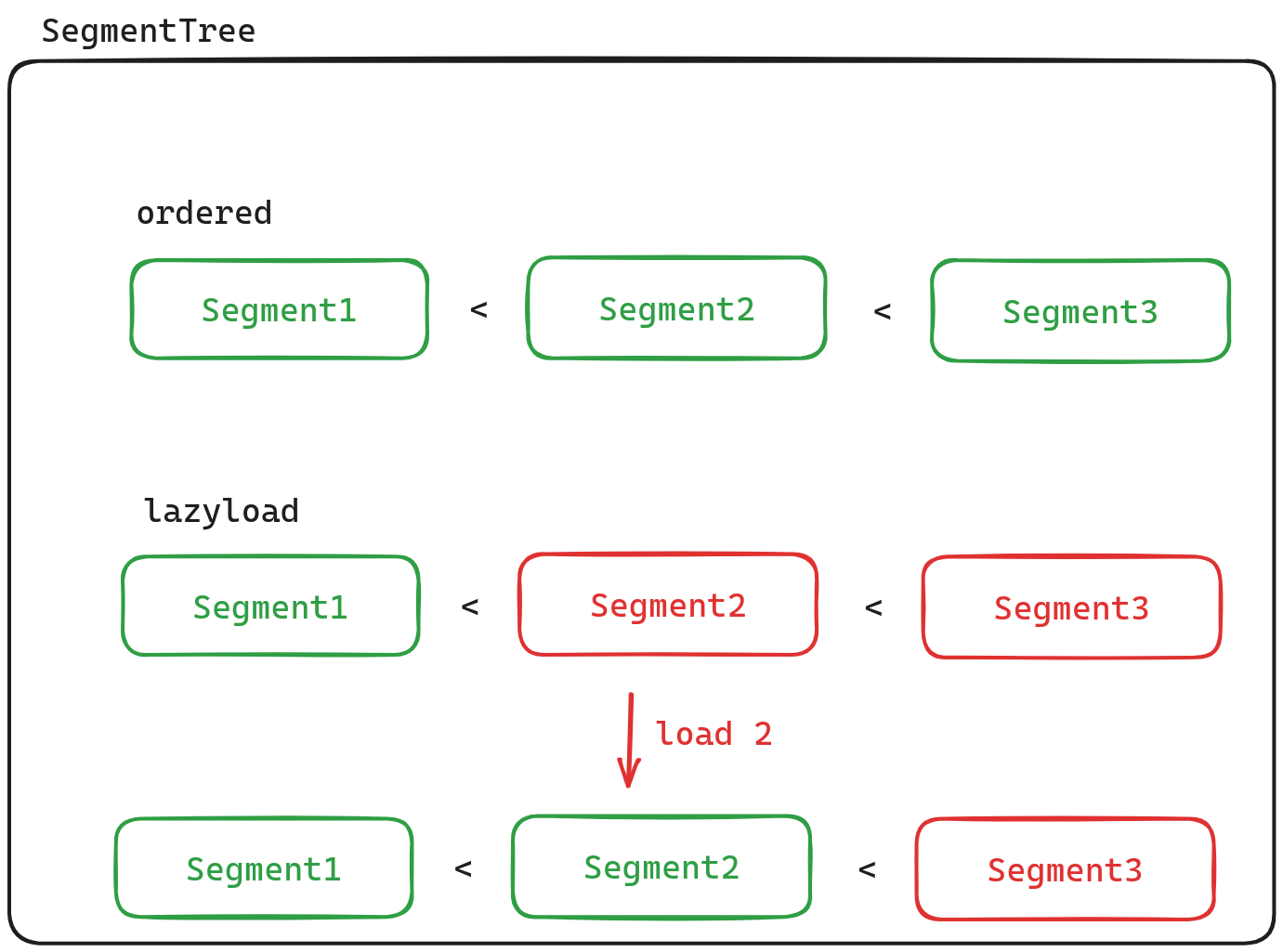
Segment Tree
Segment可以认为是一块数据,我们使用SegmentTree来对Segment进行管理,虽然它的名字叫做SegmentTree,但实际上它内部是使用vector来保存Segment的。并且会使用二分查找来寻找指定的Segment,因此这要求Segment是按序存储的。SegmentTree的另一个特点就是支持懒加载。它并不会一次性将要管理的Segment全部读取进来,相反,它会在需要时,才从磁盘中读取Segment.
文件结构
这一节我们开始介绍DuckDB的文件结构。
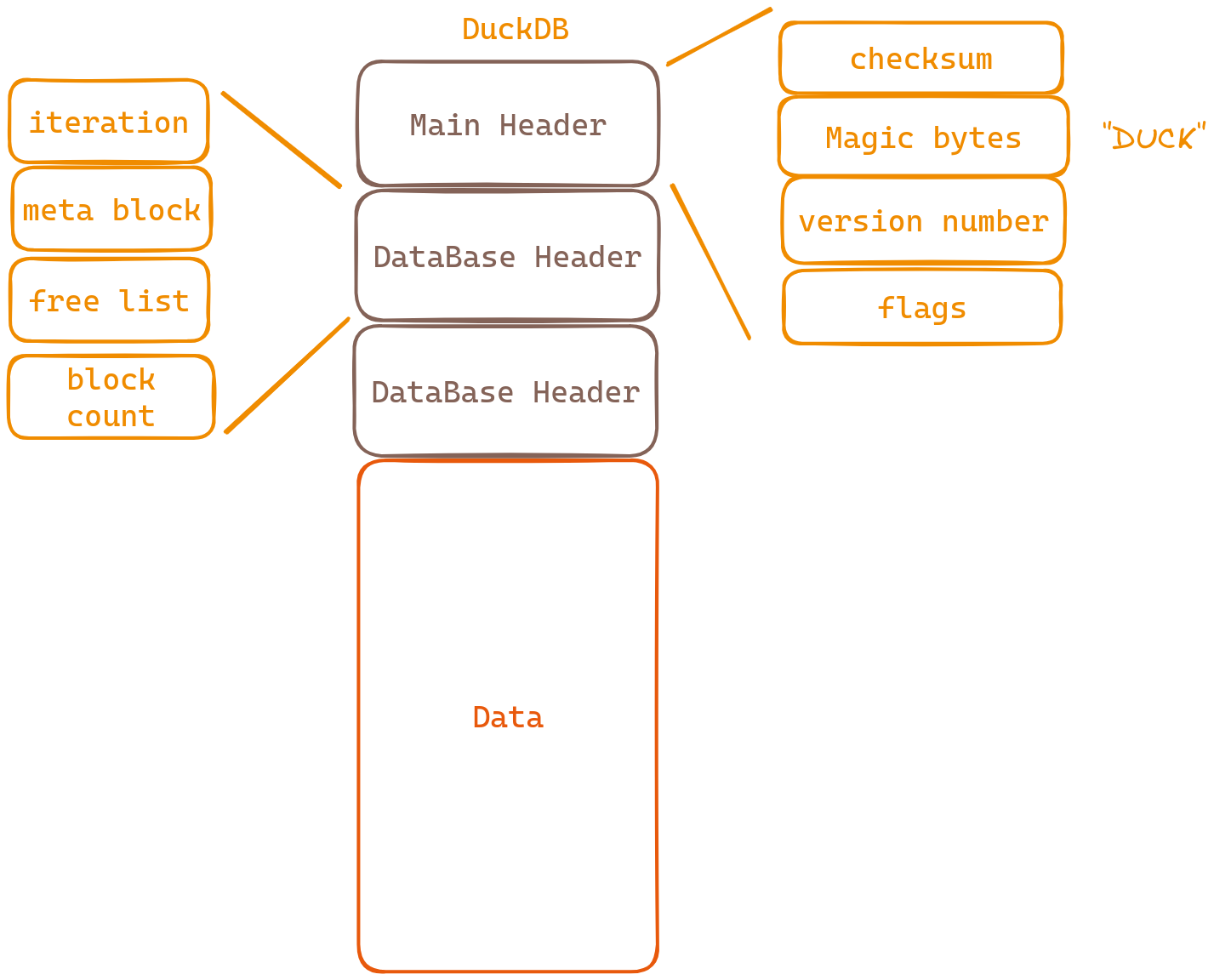
我们从图中可以看到DuckDB有三个Header,因为这三个Header并不影响我们理解表的存储,因此这里只是简单的介绍一下。
-
MainHeader
- checksum 校验和
- Magic bytes 确定这是duckDB的文件
- version numbers 版本号
- flags 表明该数据库是否可读,可写
-
DataBaseHeader
- iteration 迭代次数
- meta block 存放data的第一个block的block-id
- free list 可被复用的block
- block count 总block数
下面我们可以看到Data的存储,它由一个schema count和 ${schema_count} 个schema组成,我们的表就存储在schema中。(schema在DuckDB中可以认为就是一个database)
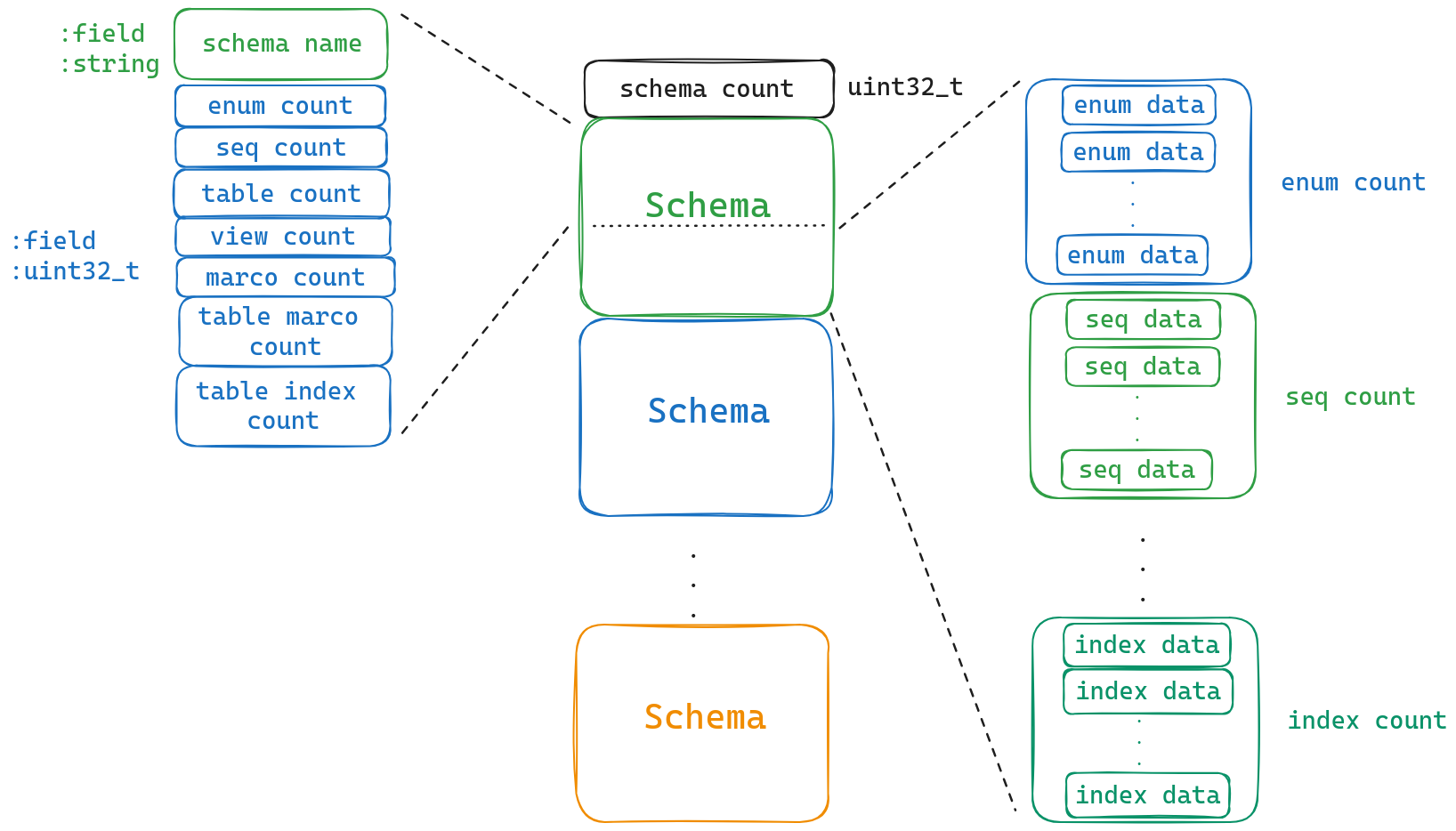
我们继续看schema的存储结构,第一个字段就是schema的名称,随后跟着的就是该schema所拥有的各种类型的个数。下面我们简单介绍各种类型。有兴趣的可以自己看一下官网的定义。这里我们只关注table的数据.
我们继续查看table的结构
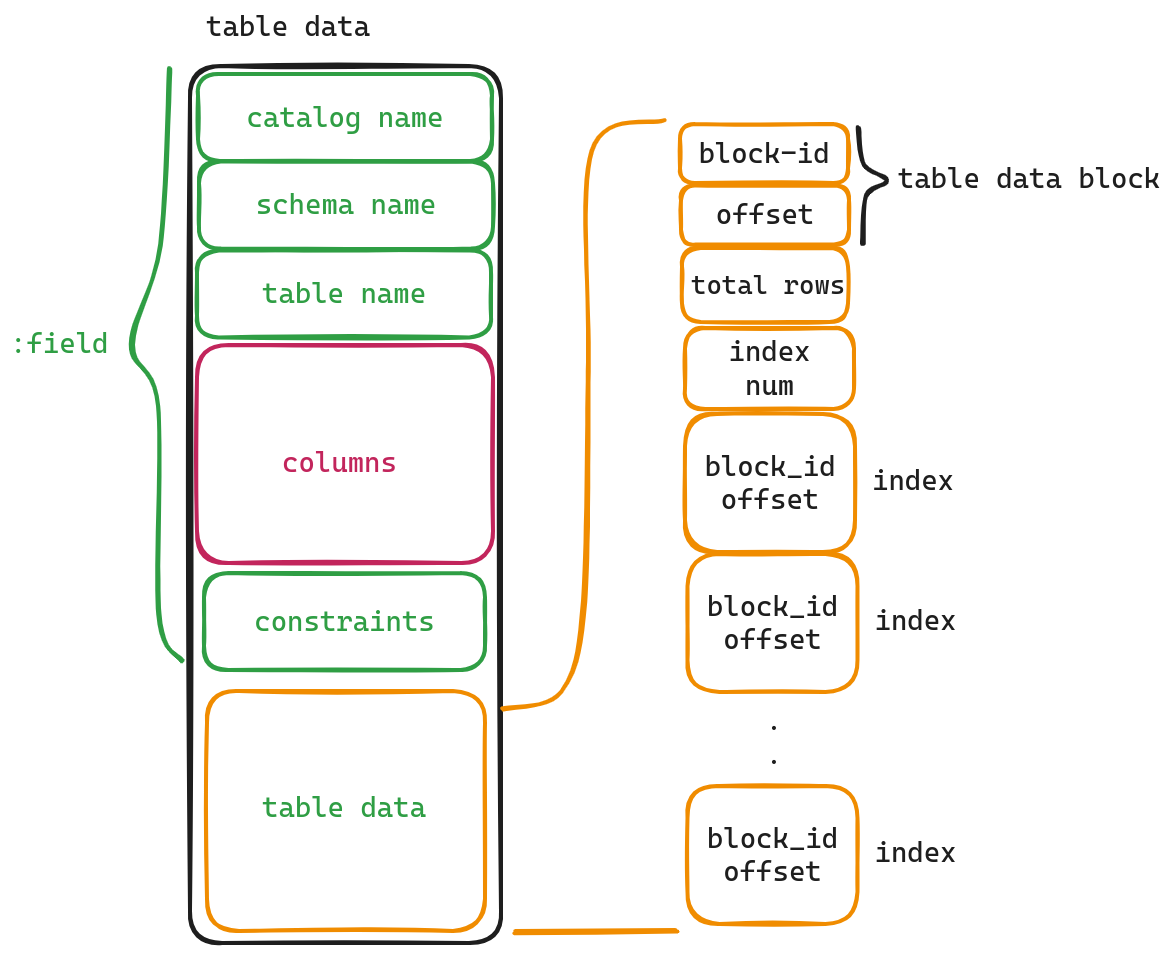
我们从图中可以看到table中前三个字段分别是catalog name, schema name, table name. 我们通过这三个字段可以确定这个表属于哪一个文件(catalog)的哪一个数据库(schema)的哪一个表.
costraints这一字段来表明该表的一些约束,比如Not Null, Unique等.我们这篇文章不会深究这部分,我们主要研究Columns以及table data字段.
Columns
该字段保存的是table各个列的定义.
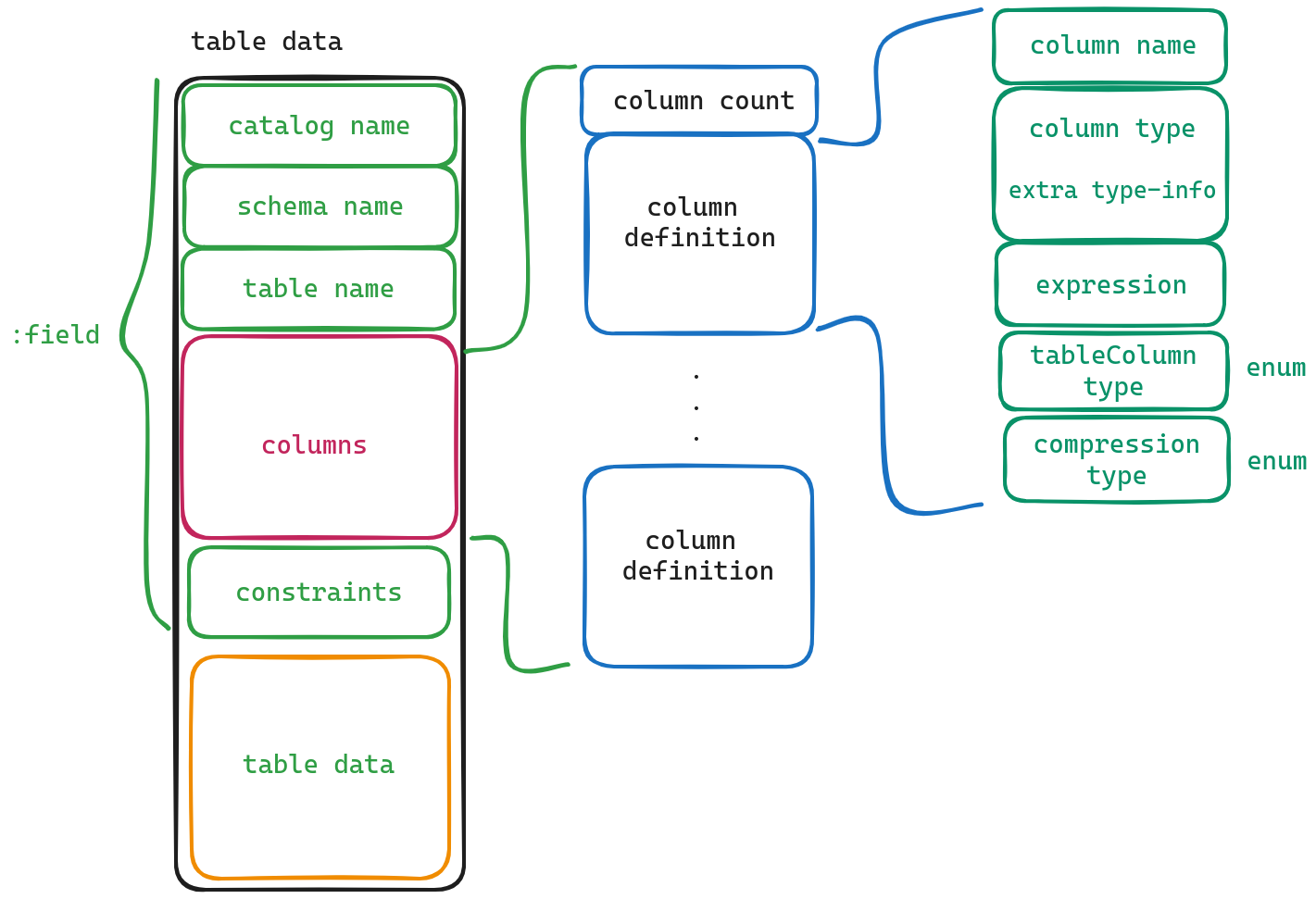
我们可以看到,第一个字段保存的是column的数量,该字段后面紧跟着每个column的定义.我们下面来看一下各个字段的意义
- column name 字段名
- column type 字段类型
- expression 表达式, 有些字段是通过表达式生成的.
- table Column type 这个不同于column type, 并不表示字段类型,他只有两个取值,一个是STANDARD, 另一个则是GENERATED . (其实我也不是太明白这个字段的意思,大概是用来判断这个字段是不是生成的)
- compression type 表明这个字段所采用的压缩方法.
在获得了column的类型以后,其实我们已经完全知晓了table的整个结构,剩下的就是实际数据以及索引的数据了.而这些数据则需要通过table data这个字段获得.
table data
因为索引以及表的实际数据一般都比较大,因此我们并没有在这里直接存储,而是存储了指向实际数据的指针(block-id, offset).
我们配合这张图来对各个字段进行解释
- table data block 指向实际表数据的指针.
- total rows 该表的行数.
- index num 该表的所有索引数量.
- index 指向索引的指针.
下面我们看一下table data block的实际数据存储的结构
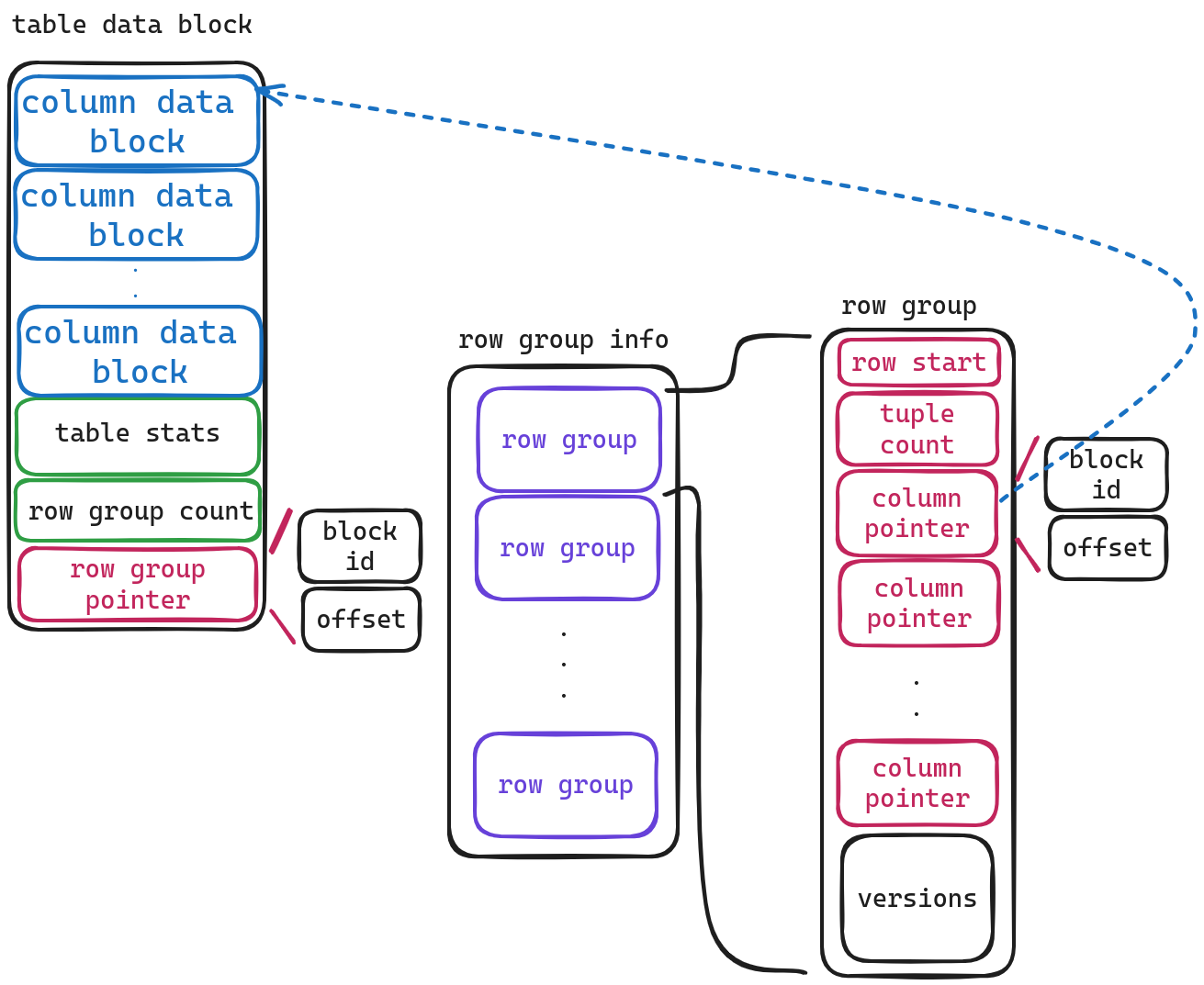
最开始存储的是一系列column数据的元信息(后面会介绍column data block的结构),后两个个字段十分好理解,第一个存储着表的统计信息,另一个存储着 row group 数量。
这里引出两个问题,什么是row group ,为什么存储格式不和前面一样即<data-count, data, data, ... data>.而是只存储了一个row group pointer,如果row group count 大于1怎么办?
row group
我们都知道OLAP一般采取列式存储,而OLTP则采取行式存储。尽管在读取,计算方面列式存储优于行式存储,但如果是频繁的增删改查,行式存储则优于列式存储。因此DuckDB在这里做了一个折衷方案,即将tuple进行分组,组内进行列式存储。目前是每122880分为一组。
为什么只有一个row group pointer
因为row group一定是按照行号按序存储的,同时它存储的block为meta block,所以它可以通过SegmentTree进行管理,从而可以对后续的row group进行懒加载, 当需要时再直接向后读取即可,因此在这里只需要存储第一块的block-id了。
下面我们再看一下row group的存储结构
- row start 该row group的起始行号
- tuple count 该row group的行数
- column pointers 因为row group中是按列存储,因此该pointer指向column的实际存储地址
- versions 这个字段没太细看,应该是mvcc相关的内容。
我们继续看column data block的存储结构
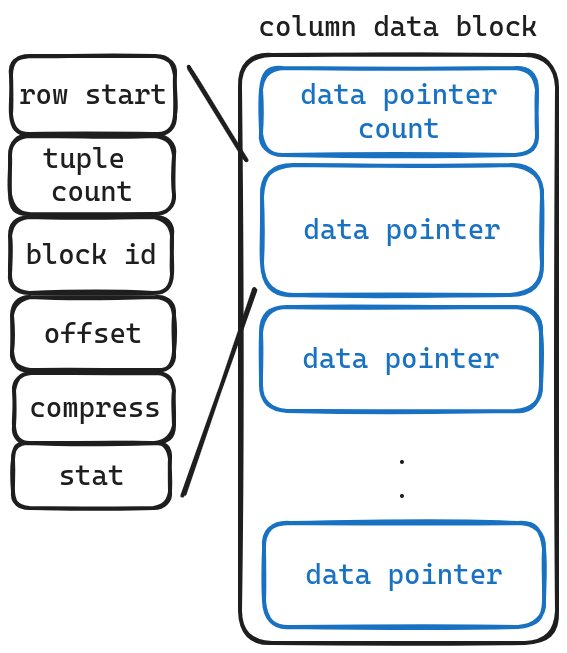
我们惊讶的发现这里仍旧不是实际存储数据的地方,存放的还是指针,这是为什么?原因在于实际的column数据是存放在pure block中的,即它没法像meta block那样有一个 block list,而每个block的大小是定死的,因此我们需要一个个block存储,这里的data pointer就充当了block list的链接作用。
按照惯例,依旧解释一下各字段的含义
- row start 这片数据的开始行号
- tuple count 存储的总行数
- block id 实际数据所在的block id
- offset 实际数据所在的block id 的offset
- compress 数据所采用的压缩方式
- stat 该部分数据的统计信息
现在我们来到了column数据所在的block。存储的格式会因为压缩方式不同而不同,我这里简单介绍几种,有兴趣的可以自己看一下其他几种。
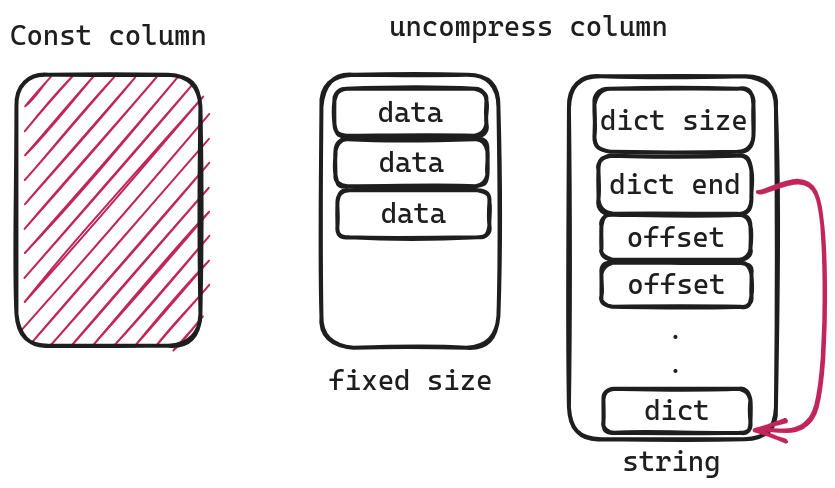
Const Column
const column,即所有的值都一样,所以我们可以完全不存储任何数据。只需从统计信息中得到min value即可
uncompress column
uncompress column,即不压缩。对于像uint32, uint8这样的数据类型,因为是固定大小,因此我们只要一个个读取即可。但是对于像string 这样非定长的数据类型,我们就会采用另一种方式来存储,即 Dictionary Compress(说好的不压缩呢!)
对于string首先前两个字段就可以得到dict的位置
dict_start = dict_end - dict_sizedict_end = dict_enddict_size = dict_size
我们在这里将dict可以看作string pool,而offset则是对应的起始位置,而offsets[i] - offsets[i-1]即为长度。这么说有点抽象,我们举一个例子。
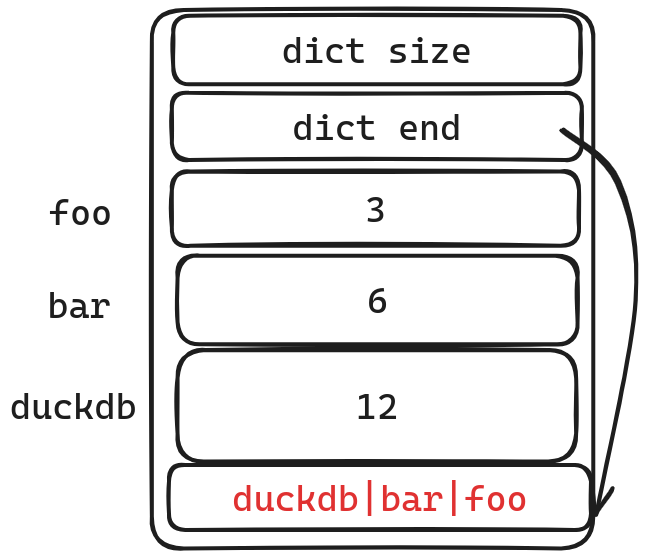
这个例子里面我们一共有三个字符串 foo ,bar , duckdb
我们将这三个字符串逆序存放在dict中。offset则是相对于dict end的offset.通过这种方式我们可以定位到相应的string的首地址。
-
foo
head = dict - offset = dict - 3length = 3 - 0 = 3
-
bar
head = dict - offset = dict - 6length = 6 - 3 = 3
-
foo
head = dict - offset = dict - 12length = 12 - 6 = 6
还记得我们说过column data所在的block都是pure block, 如果string的长度超长怎么办?
我们会通过将offset取负数,表明该string较长,同时在dict中对应位置存储(block id, offset),然后去另一个block中读取该string。
RLE column and bitpacking
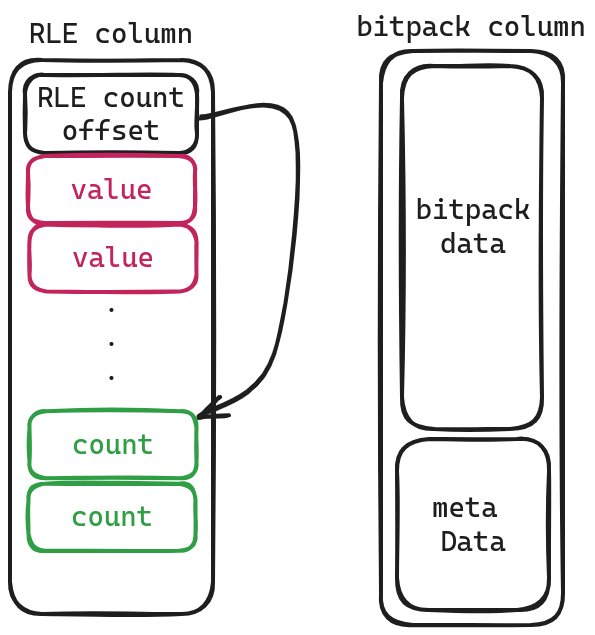
RLE column相对简单,前面存储的是值,后面存储该值出现的次数。通过 RLE count offset将两者进行分隔。
bitpack column留给有兴趣的读者自己研究。
Dictionary column
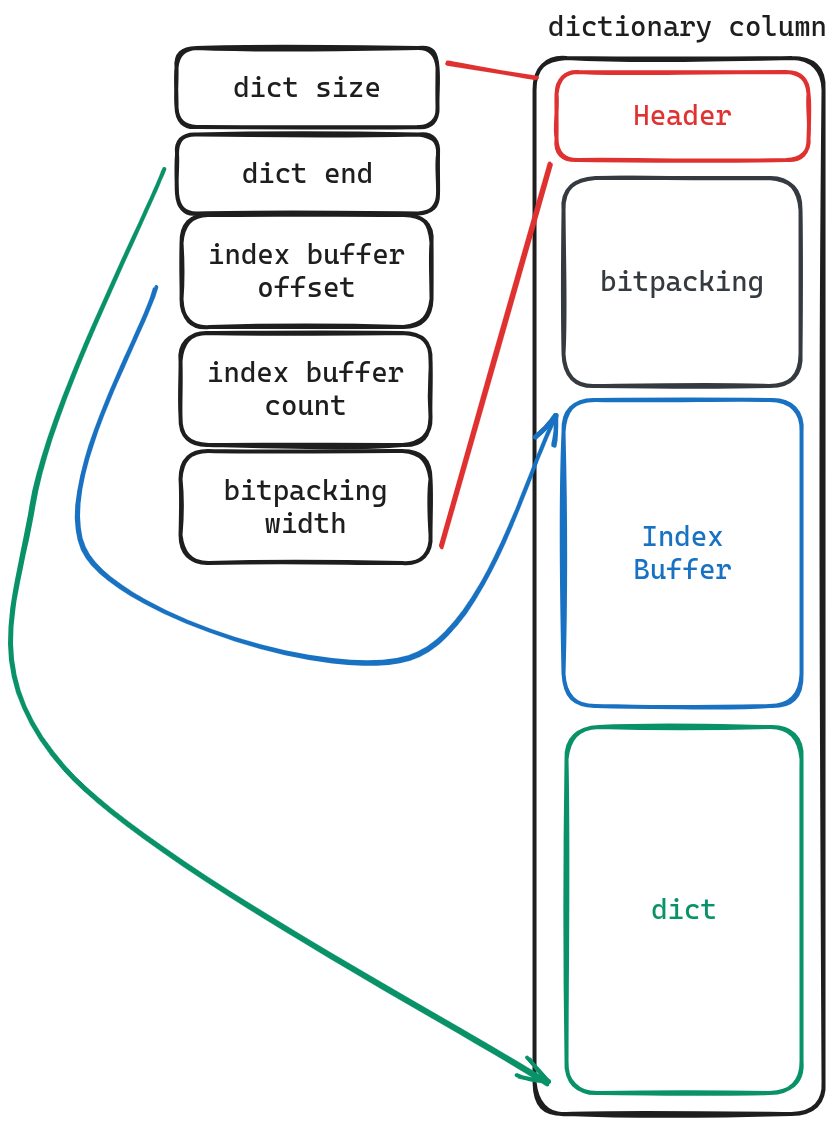
如果你理解了uncompress column中string的存储方式,那你也会较为容易的理解Dictionary column, 其中dict含义保持不变,index Buffer则是之前提到的offsets,bitpacking 存储的则是该行对应的值是index Buffer中的第几个。通过 dict.get(indexBuffer[bitpacking[i]]) 获得存储的值。
值得注意的是,这里还有一个优化时,在实际扫描时,会先对dict进行解压,而后如果发现要扫描所有数据时,只需要解压bitpacking即可。
Last
本文介绍了DuckDB中table的存储结构,duckDB相比于其他的数据库,它仅使用一个文件存储整个数据库(其实我也不知道这是好是坏,但是它的定位是单机数据库,不寻求分布式能力,也许还可以?) 同时它使用了row group的方案,并对其进行懒加载的方式提升性能。column也支持多种压缩格式。