LevelDB(3) -- 压实与版本
本文将介绍LevelDB的压实操作,以及相应的版本管理。
Compact
通过前面的文章,我们知道LevelDB会先将添加的KV写入到内存中的MemTable中,等到MemTable到达一定阈值后,再将MemTabledump到磁盘中,而且LevelDB为了写的性能,并不会做update-in-place,而是标记删除。这就会导致,随着数据的增多,无用的数据也增多(被标记删除的旧记录),文件数也会越来越多。因此我们需要将多个小文件合并为一个大文件,从而删除无用的数据,并且减少文件数从而提升查询性能。
合并可以减少空间的占用也许比较好理解,但是为什么减少文件数可以提升性能呢?首先,如果文件数多,那么做一个查询时,需要查询的文件数也相应会变多。其次通过压实合并文件,同一level中的文件可以保证key之间没有重叠,从而每一层只需要查找一个文件即可,不同level之间的文件中的key也尽可能没有重叠。
下面我们来看一下LevelDB的Compact实现
Compact的时机
LevelDB在三种情况下会尝试触发Compact
- DB刚被打开时,此时会尝试触发一次Compact
- 有数据写入时,此时也会尝试触发一次Compact
- 查询数据时,也会尝试触发一次Compact
第一种情况没什么好说的,就是打开的时候看看能不能让整个DB更整洁。
第二种情况则是如果数据写入前,发现MemTable已经到达阈值了,那么此时需要将当前的MemTabledump到磁盘中(这也是一种压实)dump的具体细节在 LevelDB(1) — 写::ldb文件的格式与生成。
第三种情况则是查询数据时,如果我们一次查询,查询了多个文件,这就说明level与level之间有key重叠(同level中key不重叠,除了level-0,因此如果查询了多个文件说明一定涉及多个level), 对于这种情况我们会记录这个文件被查询的次数,当到达阈值后,我们就要尝试进行Compact,这样子后续再查时,我们可能只需要查找一个文件就可以了。
一个文件可以被查询的阈值是如何设置的,我们直接看代码与注释,相信就可以很好的理解了。
// We arrange to automatically compact this file after
// a certain number of seeks. Let's assume:
// (1) One seek costs 10ms
// (2) Writing or reading 1MB costs 10ms (100MB/s)
// (3) A compaction of 1MB does 25MB of IO:
// 1MB read from this level
// 10-12MB read from next level (boundaries may be misaligned)
// 10-12MB written to next level
// This implies that 25 seeks cost the same as the compaction
// of 1MB of data. I.e., one seek costs approximately the
// same as the compaction of 40KB of data. We are a little
// conservative and allow approximately one seek for every 16KB
// of data before triggering a compaction.
f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
levels_[level].deleted_files.erase(f->number);
levels_[level].added_files->insert(f);Compact的实现
我们先看代码
void DBImpl::BackgroundCall() {
MutexLock l(&mutex_);
// 该标识已经在 DBImpl::MaybeScheduleCompaction 进行设置
assert(background_compaction_scheduled_);
if (shutting_down_.Acquire_Load()) {
// No more background work when shutting down.
} else if (!bg_error_.ok()) {
// No more background work after a background error.
} else {
// 执行具体的压实任务
BackgroundCompaction();
}
background_compaction_scheduled_ = false;
// 前一次压实可能在某个 level 产生了过多文件, 所以再调度
// 一次压实, 如果判断真得需要的话.
MaybeScheduleCompaction();
background_work_finished_signal_.SignalAll();
}在这里我们可以看到,我们再Compact后,仍然会尝试再次Compact这是因为再上一次的Compact后,可能我们产生了过多的文件,从而需要再次Compact.
下面的代码是Compact的具体实现.
// 该方法仅在 DBImpl::BackgroundCall 调用
void DBImpl::BackgroundCompaction() {
// 压实过程需要全程持有锁, 这也暗示压实不能耗费太多时间.
mutex_.AssertHeld();
// 先压实已满的 memtable
if (imm_ != nullptr) {
CompactMemTable();
return;
}
// 如果手动触发了一个压实
if (is_manual) {
// ...
} else {
// 否则根据统计信息确定待压实 level
c = versions_->PickCompaction();
}
Status status;
if (c == nullptr) {
// 无需压实
} else if (!is_manual && c->IsTrivialMove()) {
// 不做压实, 直接把文件从 level 移动到 level+1
assert(c->num_input_files(0) == 1);
FileMetaData* f = c->input(0, 0);
// 将该文件从 level 层删除
c->edit()->DeleteFile(c->level(), f->number);
// 将该文件增加到 level+1
c->edit()->AddFile(c->level() + 1, f->number, f->file_size,
f->smallest, f->largest);
// 应用本次移动操作
status = versions_->LogAndApply(c->edit(), &mutex_);
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log, "Moved #%lld to level-%d %lld bytes %s: %s\n",
static_cast<unsigned long long>(f->number),
c->level() + 1,
static_cast<unsigned long long>(f->file_size),
status.ToString().c_str(),
versions_->LevelSummary(&tmp));
} else {
CompactionState* compact = new CompactionState(c);
// 做压实
status = DoCompactionWork(compact);
if (!status.ok()) {
RecordBackgroundError(status);
}
// 清理压实现场
CleanupCompaction(compact);
// 释放压实用到的输入文件
c->ReleaseInputs();
// 删除过期文件
DeleteObsoleteFiles();
}
delete c;
//....
}从代码中可以看到,整个Compact的实现分为两部分,如果有需要被dump到磁盘的MemTable,那么就直接进行压实。具体流程我在LevelDB(1) — 写::ldb文件的格式与生成有详细的描述,这里不赘述。在本篇文章中,我们主要关注第二部分,即自动Compact。
首先我们会尝试挑选出需要被Compact的level。
Compaction* c;
int level;
const bool size_compaction = (current_->compaction_score_ >= 1);
const bool seek_compaction = (current_->file_to_compact_ != nullptr);
// 我们倾向于因为某层数据太多而触发的压实,
// 而非因为查询次数超过上限(即 FileMetaData->allowed_seeks)触发的压实.
// 实现办法就是先检查大小后检查查询次数.
// 先看有无 level 存储比值已经超过上限
if (size_compaction) {
level = current_->compaction_level_;
assert(level >= 0);
assert(level+1 < config::kNumLevels);
c = new Compaction(options_, level);
// 找到待压实 level 第一个可能包含 compact_pointer_[level] 的文件
for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
// 把这个文件追加到 level 对应的待压实文件集合中
c->inputs_[0].push_back(f);
break;
}
}
// 如果 level 对应的待压实文件集合为空(说明 compact_pointer_[level]
// 位于 level 最后一个文件之后), 则回绕到开头, 将其第一个
// 文件加入到待压实集合.
if (c->inputs_[0].empty()) {
// Wrap-around to the beginning of the key space
c->inputs_[0].push_back(current_->files_[level][0]);
}
} else if (seek_compaction) { // 再看是否有文件因为查询次数过多
// (Version::Get() 时候疑似包含但实际不包含目标 key 的最底层
// level 的第一个文件会被记录到统计信息中, 然后会被 Version::UpdateStats() 处理)
// 而可以触发压实
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
} else {
return nullptr;
}
c->input_version_ = current_;
c->input_version_->Ref();
// level-0 文件可能彼此重叠, 所以要把全部重叠文件都加入到待压实文件集合中
if (level == 0) {
InternalKey smallest, largest;
GetRange(c->inputs_[0], &smallest, &largest);
// Note that the next call will discard the file we placed in
// c->inputs_[0] earlier and replace it with an overlapping set
// which will include the picked file.
// 注意下面这个方法会清除 inputs[0] 内容, 不过不用担心, 由于已经提前提取到了
// inputs[0] 键范围所以下面这个方法会把那个被清除的文件重新捞回来.
current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]);
assert(!c->inputs_[0].empty());
}
// 将 level+1 中与 level 对应待压实集合重叠的文件拿出来做压实
SetupOtherInputs(c);
return c;根据Compact的触发原因不同,我们采用不同的策略
- 由于某一层的数据超过阈值导致的
Compact,对于这种情况我们采用round-robin的方式来进行Compact,即如果上一次Compact的最大的key为“A1”,那么我们这一次就挑选出比”A1”大的文件来做Compact. - 如果是由于查询次数过大导致的
Compact,那么我们就直接选择该文件来做Compact
注意,我们会对Level-0做特殊的处理,因为Level-0中文件的Key会重叠,因此我们会将所有Key重叠的文件都作为准备Compact的候选项。
在获得需要Compact的文件后,我们需要在上一层寻找与当前层重叠的文件作为一个整体一起compact。如下图所示。
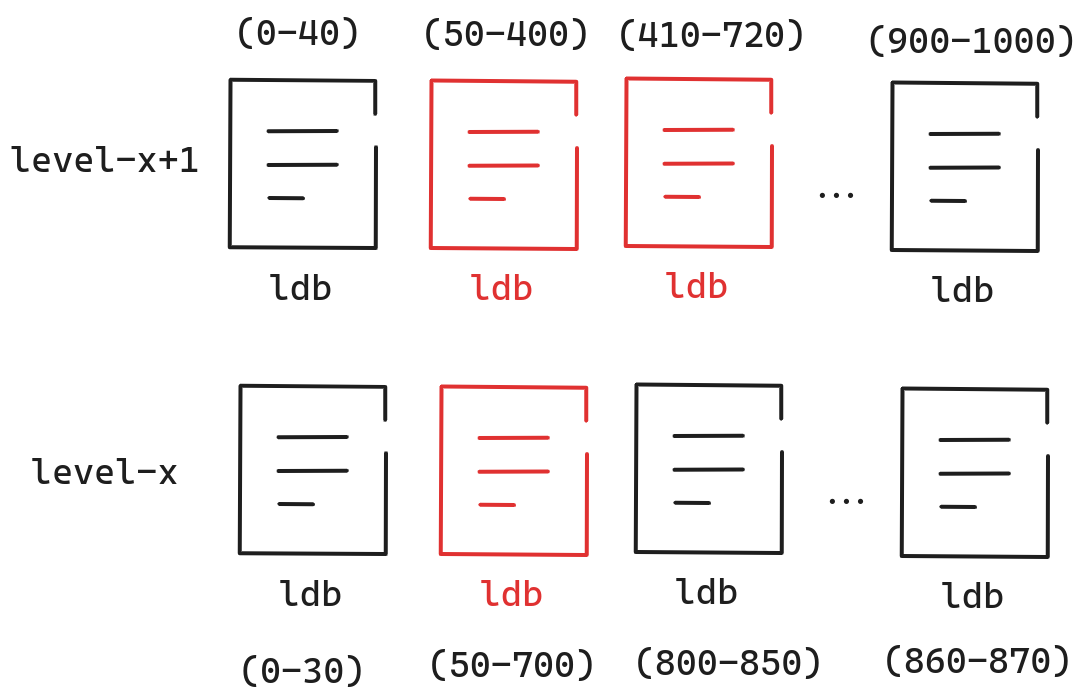
在得到上一层准备被Compact的文件后,我们会获得key的范围,如上图所示,一开始Level-x的范围为(50-700),在得到Level-x+1准备被Compact的文件后,范围来到了(50-720)。在某些情况下,我们在不改变Level-x+1准备被Compact的文件数的前提下,从Level-x中选择更多的文件来进行Compact,从而使得Compact的效率更高。之所以不改变Level-x+1准备被Compact的文件数,是为了防止无限制的循环下去,从而导致Level-x和Level-x+1的所有文件全部都需要进行Compact。
在决定了需要Compact的文件后,我们有两种方式进行Compact
TrivialMove
return (num_input_files(0) == 1 && num_input_files(1) == 0 &&
TotalFileSize(grandparents_) <=
MaxGrandParentOverlapBytes(vset->options_));如果 level 层只有 1 个待压实文件 , level+1 层没有与 level 待压实文件发生重叠的文件 且 level+2 层与 level 待压实文件重叠的字节数不大于上限,则可以用移动替代压实.这里之所以要判断**level+2 层与 level 待压实文件重叠的字节数不大于上限** 是因为如果 level 与祖父(即 level+2) 有大量重叠数据, 合并后会创建一个父文件(即 level+1), 很显然这个文件和自己父亲 level(即上面说的 level+2)存在大量重叠数据, 这个情况会导致后续非常昂贵的合并.
DoCompactionWork
// 具体压实就做一件事情:
// 遍历待压实文件, 如果某个 key (位于 level-L 或者 level-(L+1))的类型属性取值为"删除",
// 则确认其在 level-(L+2) 或之上是否存在, 若不存在则丢弃之, 否则写入合并后的文件.
Status DBImpl::DoCompactionWork(CompactionState* compact) {
const uint64_t start_micros = env_->NowMicros();
// 用于 imm_ 压实耗时统计
int64_t imm_micros = 0;
Log(options_.info_log, "Compacting %d@%d + %d@%d files",
compact->compaction->num_input_files(0),
compact->compaction->level(),
compact->compaction->num_input_files(1),
compact->compaction->level() + 1);
assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);
assert(compact->builder == nullptr);
assert(compact->outfile == nullptr);
// 如果快照列表为空, 则将最新的操作序列号作为最小的快照
if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
// 否则从快照列表获取最老的快照对应的序列号作为最小快照.
// 虽然最老, 但是没有 release 就是要保障可见性的.
compact->smallest_snapshot = snapshots_.oldest()->sequence_number();
}
// 真正做压实工作的之前要释放锁
mutex_.Unlock();
// 针对待压实的全部文件创建一个大迭代器
Iterator* input = versions_->MakeInputIterator(compact->compaction);
// 迭代器指针拨到开头
input->SeekToFirst();
Status status;
ParsedInternalKey ikey;
// 下面三个临时变量用来处理多个文件(如果压实涉及了 level-0)
// 或多个 level 存在同名 user key 的问题, 典型地有如下两种:
// 1. level-0 文件可能存在重叠, 同名 user key 后出现的更新,
// 序列号也更大.
// 2. 低 level 和高 level 之间可能重叠(这个可能其实是肯定,
// 因为不重叠就不用压实了), 同名 user key 先出现的更新, 序列号也更大.
std::string current_user_key;
bool has_current_user_key = false;
// 如果 user key 出现多次, 下面这个用于记录上次出现时对应的
// internal key 的序列号.
SequenceNumber last_sequence_for_key = kMaxSequenceNumber;
for (; input->Valid() && !shutting_down_.Acquire_Load(); ) {
// 优先处理已经写满待压实的 memtable
if (has_imm_.NoBarrier_Load() != nullptr) {
const uint64_t imm_start = env_->NowMicros();
mutex_.Lock();
if (imm_ != nullptr) {
// immutable memtable 落盘
CompactMemTable();
// 如有必要唤醒 MakeRoomForWrite()
background_work_finished_signal_.SignalAll();
}
mutex_.Unlock();
imm_micros += (env_->NowMicros() - imm_start);
}
// 即将被处理的 key
Slice key = input->key();
// 当发现截止到 key, level 和 level+2 重叠数据量已经达到上限, 则
// 开始进行压实; key 也是压实的最右区间.
// 一进来循环看到这个判断代码可能比较懵, 肯定看不太懂, 其实下面这个判断一般
// 要经过若干循环才能成立, 先看后面代码再回来看这个判断.
if (compact->compaction->ShouldStopBefore(key) &&
compact->builder != nullptr) {
// 将压实生成的文件落盘
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
// Handle key/value, add to state, etc.
bool drop = false;
// 反序列化 internal key
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
// 如果这个 user key 之前迭代未出现过, 记下来
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key,
Slice(current_user_key)) != 0) {
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
// 标记这个 user key 截止目前轮次迭代对应的序列号;
// 因为是首次出现所以这里直接置为序列号最大可能取值.
// 确保最新的数据一定不会被drop
last_sequence_for_key = kMaxSequenceNumber;
}
// 序列号过小, 丢弃这个 key 本次迭代对应的数据; 后面还有这个 key
// 对应的更新的数据.
// 上一个seq <= smallest_snapshot, 那么这个必然 < smallest_snapshot
// 因此可以直接丢弃。
if (last_sequence_for_key <= compact->smallest_snapshot) {
// Hidden by an newer entry for same user key
drop = true; // 规则 (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
// 对于这个 user key:
// (1) 更高的 levels(指的是祖父 level 及之上)没有对应数据了
// (2) 更低的 levels 对应的数据的序列号会更大(这个是显然地)
// (3) 目前正在被压实的各个 levels(即 level 和 level+1) 中序列号
// 更小的数据在循环的未来几次迭代中会被丢弃(根据上面的规则(A)).
//
// 综上, 这个删除标记已经过期了并且可以被丢弃.
drop = true;
}
// 如果没有snapshot,相同的user key只保存最新数据。
last_sequence_for_key = ikey.sequence;
}
#if 0
Log(options_.info_log,
" Compact: %s, seq %d, type: %d %d, drop: %d, is_base: %d, "
"%d smallest_snapshot: %d",
ikey.user_key.ToString().c_str(),
(int)ikey.sequence, ikey.type, kTypeValue, drop,
compact->compaction->IsBaseLevelForKey(ikey.user_key),
(int)last_sequence_for_key, (int)compact->smallest_snapshot);
#endif
// 如果当前数据项不丢弃, 则进行压实落盘
if (!drop) {
// 如有必要则创建新的 output file
if (compact->builder == nullptr) {
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
if (compact->builder->NumEntries() == 0) {
// 如果一个都没写过, input 迭代器又是从小到大遍历,
// 所以当前 user key 肯定是最小的
compact->current_output()->smallest.DecodeFrom(key);
}
// 否则当前 user key 目前就是最大的
compact->current_output()->largest.DecodeFrom(key);
// 将该 user key 对应的数据项写入 sstable.
// TODO 这里有个地方没看明白:
// 如果当前 user key 首次出现, 则
// 上面 last_sequence_for_key 被置为 kMaxSequenceNumber,
// 且类型不是 kTypeDeletion, 那当前数据项就不会被 drop, 即使
// 这个数据项实际 sequence number 小于 smallest_snapshot,
// 有点矛盾了.
compact->builder->Add(key, input->value());
// 如果 sstable 文件足够大, 则落盘并关闭
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
}
// 处理下个 key
input->Next();
}
if (status.ok() && shutting_down_.Acquire_Load()) {
status = Status::IOError("Deleting DB during compaction");
}
if (status.ok() && compact->builder != nullptr) {
status = FinishCompactionOutputFile(compact, input);
}
if (status.ok()) {
status = input->status();
}
delete input;
input = nullptr;
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros - imm_micros;
for (int which = 0; which < 2; which++) {
for (int i = 0; i < compact->compaction->num_input_files(which); i++) {
stats.bytes_read += compact->compaction->input(which, i)->file_size;
}
}
for (size_t i = 0; i < compact->outputs.size(); i++) {
stats.bytes_written += compact->outputs[i].file_size;
}
mutex_.Lock();
stats_[compact->compaction->level() + 1].Add(stats);
if (status.ok()) {
status = InstallCompactionResults(compact);
}
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log,
"compacted to: %s", versions_->LevelSummary(&tmp));
return status;
}实际的压实工作其实很简单,对于待压实的文件构建一个统一的迭代器,从小到大顺序访问(还记得InternalKey的构造吗,该构造可以保证我们总是最先读到最新的数据),不断的将数据写入到新的文件中。注意,如果遇到遇到标记删除的数据,不应该马上drop,而是应该确定上层没有该key的数据了,再drop(因为如果drop了,会导致以后读取该数据,可能读到上层的数据,从而导致一个本该被删除的数据又被读到了)
后面每次把最新的数据写到新的文件中。下面两种情况需要将新生成的文件落盘。
- 文件到达阈值
- 文件与grandparent重叠的byte数到达阈值(减少后续的
Compact压力)
最终完成压实的操作。
Version
LevelDB的最后,我们介绍一下版本,版本可以认为是LevelDB管理文件的一个接口,如果你想要获取文件,获取某一Level的文件,你都需要通过Version。
LevelDB的版本由三部分组成
- VersionSet 负责维护所有的Version
- Version 一个确定的版本,可以认为是数据库的Snapshot。
- VersionEdit 增量更新的版本,当完成增量更新后,VersionEdit就会变为Version。
我们先看一下Version
class Version {
VersionSet* vset_;
// 接下来两个指针使得 Version 可以构成双向循环链表
// 指向链表中下个 version 的指针
Version* next_;
// 指向链表中前个 version 的指针
Version* prev_;
// 该 version 的活跃引用计数
int refs_;
// 核心成员, 该成员保存了当前最新的 level 架构信息,
// 即 db 每个 level 的文件元数据链表
std::vector<FileMetaData*> files_[config::kNumLevels];
// 基于查询统计而得出的下个待压实的文件及其所在的 level
FileMetaData* file_to_compact_;
int file_to_compact_level_;
// 基于存储比值计算的压实分数,
// 小于 1 意味着未到上限, 压实不是很需要.
// 由 Finalize() 计算.
double compaction_score_;
// 基于存储比值而得出的下个待压实的 level.
// 由 Finalize() 计算.
int compaction_level_;
};
我们可以看到Version最重要的是保存着每一层的文件元信息,通过这些信息,我们可以获得每一个Level所拥有的文件。这也就是Version最重要的作用,确定Level的格式。
我们再看一下VersionSet
class VersionSet {
Env* const env_;
const std::string dbname_;
const Options* const options_;
// 每次用户进行查询操作的时候(DBImpl::Get())可能需要去查询
// 磁盘上的文件, 这就要求有个缓存功能来加速.
// 下面这个成员会缓存 sstable 文件对应的 Table 实例,
// 用于加速用户的查询, 否则每次读文件解析
// 就很慢了. 目前在用的缓存策略是 LRU.
// 该变量实际值来自 DBImpl 实例, 具体见 VersionSet 构造方法.
TableCache* const table_cache_;
const InternalKeyComparator icmp_;
uint64_t next_file_number_;
uint64_t manifest_file_number_;
// 记录最近一次更新操作对应的序列号(逐一递增, WriteBatch 包含一批更新操作, 每个更新操作都会有一个序列号).
// 具体修改建 DbImpl::Write 方法
uint64_t last_sequence_;
uint64_t log_number_;
uint64_t prev_log_number_; // 0 or backing store for memtable being compacted
// Opened lazily
// 当前 MANIFEST 文件
WritableFile* descriptor_file_;
// MANIFEST 文件格式同 log 文件, 所以写入方法就复用了.
// 其每条日志就是一个序列化后的 VersionEdit.
log::Writer* descriptor_log_;
// 属于该 VersionSet 的 Version 都会被维护到一个双向循环链表中,
// 而且新加入的 Version 都会插入到 dummy_versions_ 前面.
// dummy_versions_.next_ 默认指向自己(具体见 Version 构造函数)后续指向最老的 version.
Version dummy_versions_;
// 指向当前 Version == dummy_versions_.prev_
Version* current_;
// Per-level key at which the next compaction at that level should start.
// Either an empty string, or a valid InternalKey.
// 记录了每个 level 各自对应的下次压实的起始 key
std::string compact_pointer_[config::kNumLevels];
// No copying allowed
VersionSet(const VersionSet&);
void operator=(const VersionSet&);
}我们可以看到VersionSet保存着整个数据库的元信息,例如下一个文件的number,最新的sequence…,同时也维护者最新的Version,我们可以将其视作数据库的元信息。
我们再看一下VersionEdit
class VersionEdit {
private:
friend class VersionSet;
typedef std::set< std::pair<int, uint64_t> > DeletedFileSet;
// 比较器名称
std::string comparator_; // comparator name
uint64_t log_number_;
uint64_t prev_log_number_;
// 下个 MANIFEST 文件编号, 从 1 开始
uint64_t next_file_number_;
// 下个写操作的序列号
SequenceNumber last_sequence_;
bool has_comparator_;
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
// 记录每个 level 下次压实的起始 key
std::vector< std::pair<int, InternalKey> > compact_pointers_;
// 保存从当前 level 架构要删除的一个文件
DeletedFileSet deleted_files_;
// 保存要新增到当前 level 架构中的文件(注意第二个参数不是指针类型)
std::vector< std::pair<int, FileMetaData> > new_files_;
};
VersionEdit存储着目前数据库的增量信息,可以认为是实时的Version
我们从数据库的Open过程,来将这三个类串联起来。Open的过程主要还是Recover完成的,我们来看Recover的代码
Status DBImpl::Recover(VersionEdit* edit, bool *save_manifest) {
mutex_.AssertHeld();
// Ignore error from CreateDir since the creation of the DB is
// committed only when the descriptor is created, and this directory
// may already exist from a previous failed creation attempt.
// 创建数据库目录(一个目录代表一个数据库)
env_->CreateDir(dbname_);
assert(db_lock_ == nullptr);
// 锁定该目录
Status s = env_->LockFile(LockFileName(dbname_), &db_lock_);
if (!s.ok()) {
return s;
}
// 如果 CURRENT 文件(记录当前 MENIFEST 文件名称)不存在则创建之
if (!env_->FileExists(CurrentFileName(dbname_))) {
if (options_.create_if_missing) {
// 创建之
s = NewDB();
if (!s.ok()) {
return s;
}
} else {
// 报错
return Status::InvalidArgument(
dbname_, "does not exist (create_if_missing is false)");
}
} else {
if (options_.error_if_exists) {
return Status::InvalidArgument(
dbname_, "exists (error_if_exists is true)");
}
}
//....
}首先Recover会将目录锁定起来,如果目录下没有CURRENT文件,那么该数据库为新建立的,新建一个数据库即可。
在这里CURRENT文件记录着最新的MANIFEST文件名。
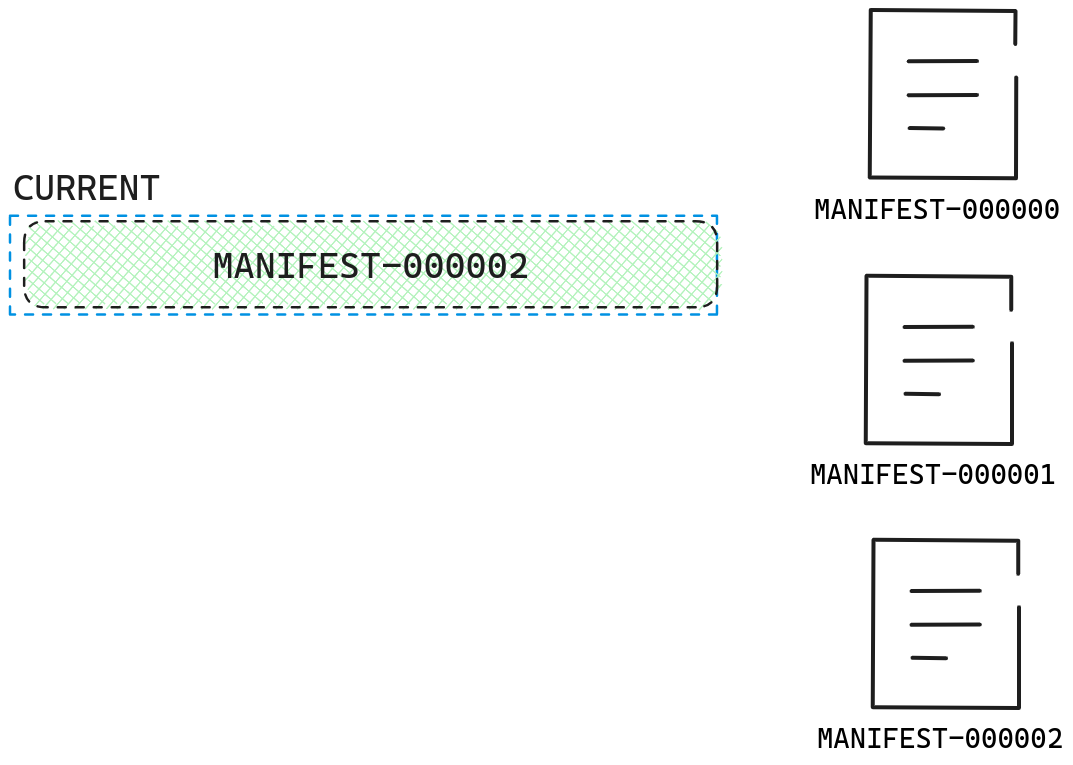
在得到了最新的MANIFEST文件名后,我们就可以调用VersionSet::Recover读取MANIFEST文件
Builder builder(this, current_);
{
LogReporter reporter;
reporter.status = &s;
log::Reader reader(file, &reporter, true/*checksum*/, 0/*initial_offset*/);
Slice record;
std::string scratch;
// 循环读取 MANIFEST 文件日志, 每一行日志就是一个 VersionEdit
while (reader.ReadRecord(&record, &scratch) && s.ok()) {
VersionEdit edit;
// 将 record 反序列化为 version_edit
s = edit.DecodeFrom(record);
if (s.ok()) {
if (edit.has_comparator_ &&
edit.comparator_ != icmp_.user_comparator()->Name()) {
s = Status::InvalidArgument(
edit.comparator_ + " does not match existing comparator ",
icmp_.user_comparator()->Name());
}
}
// 将 VersionEdit 保存到 VersionSet 的 builder 中,
// 后者可以一次性将这些文件变更与当前 Version 合并构成新 version.
if (s.ok()) {
builder.Apply(&edit);
}
if (edit.has_log_number_) {
// 保存最新的日志文件名, 越后面的日志(record)记录的日志文件名越新
log_number = edit.log_number_;
have_log_number = true;
}
if (edit.has_prev_log_number_) {
prev_log_number = edit.prev_log_number_;
have_prev_log_number = true;
}
if (edit.has_next_file_number_) {
next_file = edit.next_file_number_;
have_next_file = true;
}
if (edit.has_last_sequence_) {
last_sequence = edit.last_sequence_;
have_last_sequence = true;
}
}
}Manifest的文件格式与LOG文件保持一致,LOG文件的具体格式如下图所示。
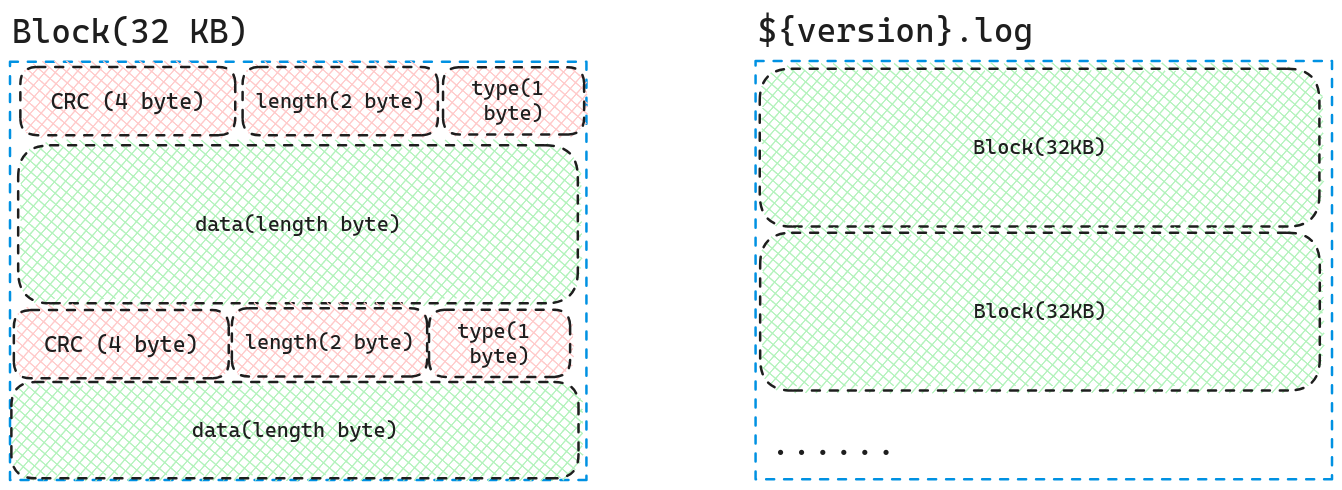
而里面的data则是VersionEdit的序列化形式(里面的tag可能出现多次)。
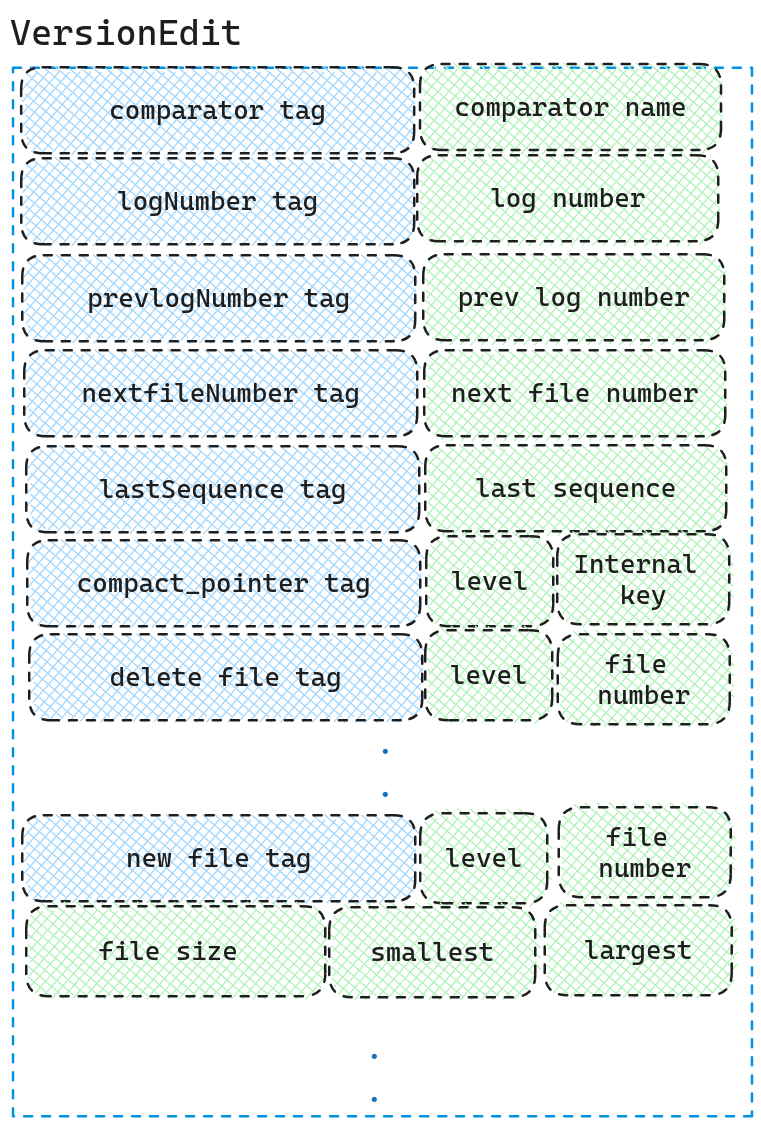
在反序列化VersionEdit后,我们可以将所有的VersionEdit合并给一个Version,本质上就是把VersionEdit的新增文件以及删除文件,compact_pointer,和现有的Version进行合并。
void Apply(VersionEdit* edit) {
// 更新压实指针信息
// 将 edit 中保存的每一层下次压实起始 key 复制到 VersionSet 中
for (size_t i = 0; i < edit->compact_pointers_.size(); i++) {
const int level = edit->compact_pointers_[i].first;
// 与下面新增和删除不同, 这里直接修改 vset
vset_->compact_pointer_[level] =
edit->compact_pointers_[i].second.Encode().ToString();
}
// 删除文件
// 将 edit 中保存的待删除文件集合导入到 levels_[].deleted_files 中
const VersionEdit::DeletedFileSet& del = edit->deleted_files_;
for (VersionEdit::DeletedFileSet::const_iterator iter = del.begin();
iter != del.end();
++iter) {
const int level = iter->first;
const uint64_t number = iter->second;
levels_[level].deleted_files.insert(number);
}
// 添加新文件
// 将 edit 中保存的新增文件集合导入到 levels_[].added_files 中
for (size_t i = 0; i < edit->new_files_.size(); i++) {
// pair 第一个参数为 level
const int level = edit->new_files_[i].first;
// pair 第二个参数为 FileMetaData
FileMetaData* f = new FileMetaData(edit->new_files_[i].second);
f->refs = 1;
// leveldb 针对经过一定查询次数的文件进行自动压实. 我们假设:
// (1)一次查询消耗 10ms
// (2)写或者读 1MB 数据消耗 10ms(即 100MB/s, 这是一般磁盘 IO 速度)
// (3)1MB 数据的压实做了 25MB 数据的 IO 工作:
// 从 level-L 读取了 1MB
// 从 level-(L+1) 读取了 10-12MB(边界可能没有对齐)重叠数据
// 将压实后的 10-12MB 数据写入到 level-(L+1)
// 基于上述假设, 我们可以得出, 执行 25 次查询消耗的时间与压实 1MB 数据
// 的时间相同, 都是 250ms. 也就是说, 一次查询大约相当于压实 40KB (=1MB/25)数据.
// 现实可能没这么理想, 我们保守一些, 假设每次查询大约相当于压实 16KB 数据, 这样
// 我们就可以得出压实之前一个文件被允许查询的次数 == [文件字节数/16KB],
// 一个文件最大 2MB, 则在压实前最多允许查询 128 次, 超过次数会触发压实操作.
f->allowed_seeks = (f->file_size / 16384);
// 如果允许查询次数小于 100, 则按 100 次处理.
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
// todo 一个文件会同时出现在删除列表和新增列表?
levels_[level].deleted_files.erase(f->number);
levels_[level].added_files->insert(f);
}
}
// 将当前 version 与 builder 保存的新增文件按序合并
// 追加到新 Version v 中.
void SaveTo(Version* v) {
BySmallestKey cmp;
cmp.internal_comparator = &vset_->icmp_;
// 从低到高将当前 Version base_ 每个 level 文件列表和 Builder::levels_ 每个对应 level
// 新增文件列表合并, 并保存到 Version v 对应 level 中.
for (int level = 0; level < config::kNumLevels; level++) {
// 把新加的文件和已有文件进行合并, 丢弃已被删除的文件, 最终结果保存到 *v.
// Version base_ 中 level-L 对应的文件列表
const std::vector<FileMetaData*>& base_files = base_->files_[level];
std::vector<FileMetaData*>::const_iterator base_iter = base_files.begin();
std::vector<FileMetaData*>::const_iterator base_end = base_files.end();
// builder 保存的 level-L 对应的新增文件集合
const FileSet* added = levels_[level].added_files;
v->files_[level].reserve(base_files.size() + added->size());
// 下面两个循环按照文件包含的 key 从小到大顺序合并前述两个文件列表.
// (具体逻辑就是将两个有序列表合并的过程.)
for (FileSet::const_iterator added_iter = added->begin();
added_iter != added->end();
++added_iter) {
// 针对 builder 中每个新增文件 *added_iter,
// 从 base_ 对应 level 寻找第一个大于它的文件,
// 然后将这个文件之前的文件(builder 里文件列表从小到大有序)
// 都追加到 v 中.
// 寻找过程采用 BySmallestKey 比较器(这个抽象极好).
for (std::vector<FileMetaData*>::const_iterator bpos
= std::upper_bound(base_iter, base_end, *added_iter, cmp);
base_iter != bpos; // 如果相等说明 builder 全部文件都比 added_iter 大
++base_iter) {
// bpos 位置处文件小于 added_iter,
// 将其追加到 Version v 对应 level 的文件列表中
MaybeAddFile(v, level, *base_iter);
}
// builder 中小于 added_iter 的文件都追加过了,
// 将 *added_iter 追加到 Version v 的对应 level 的文件列表中.
MaybeAddFile(v, level, *added_iter);
}
// Add remaining base files
// 将 Version base_ 中 level-L 对应的文件列表剩余的文件追加到 Version v 的对应 level-L 的文件列表中
for (; base_iter != base_end; ++base_iter) {
MaybeAddFile(v, level, *base_iter);
}
}
}然后将新生成的Version加入到VersionSet中,并设置为current
void VersionSet::AppendVersion(Version* v) {
// Make "v" current
assert(v->refs_ == 0);
assert(v != current_);
if (current_ != nullptr) {
current_->Unref();
}
current_ = v;
// current_ 引用了 v, 将 v 引用计数加一
v->Ref();
// Append to linked list
// 将 v 加入到双向循环链表中, 新插入的永远是 dummy_versions_ 的前驱.
v->prev_ = dummy_versions_.prev_;
v->next_ = &dummy_versions_;
v->prev_->next_ = v;
v->next_->prev_ = v;
}如果你想知道在Compact时,是如何生成新的Version与新的MANIFEST,那么你可以看一下VersionSet::LogAndApply的实现。
Overview
本文介绍了LevelDB的Compact以及版本。这篇文章并没有将所有的细节都写出来,如果你想要详细了解,我推荐你还是需要去读相关代码。这篇文章更侧重描写出LevelDB的大概轮廓,以及一些比较重要的细节。希望对你理解LevelDB相关代码有所帮助。