LevelDB(2) -- 读
本文将介绍LevelDB的读操作,以及相应的迭代器
Overview
我们先看一下levelDB读操作的整体流程。
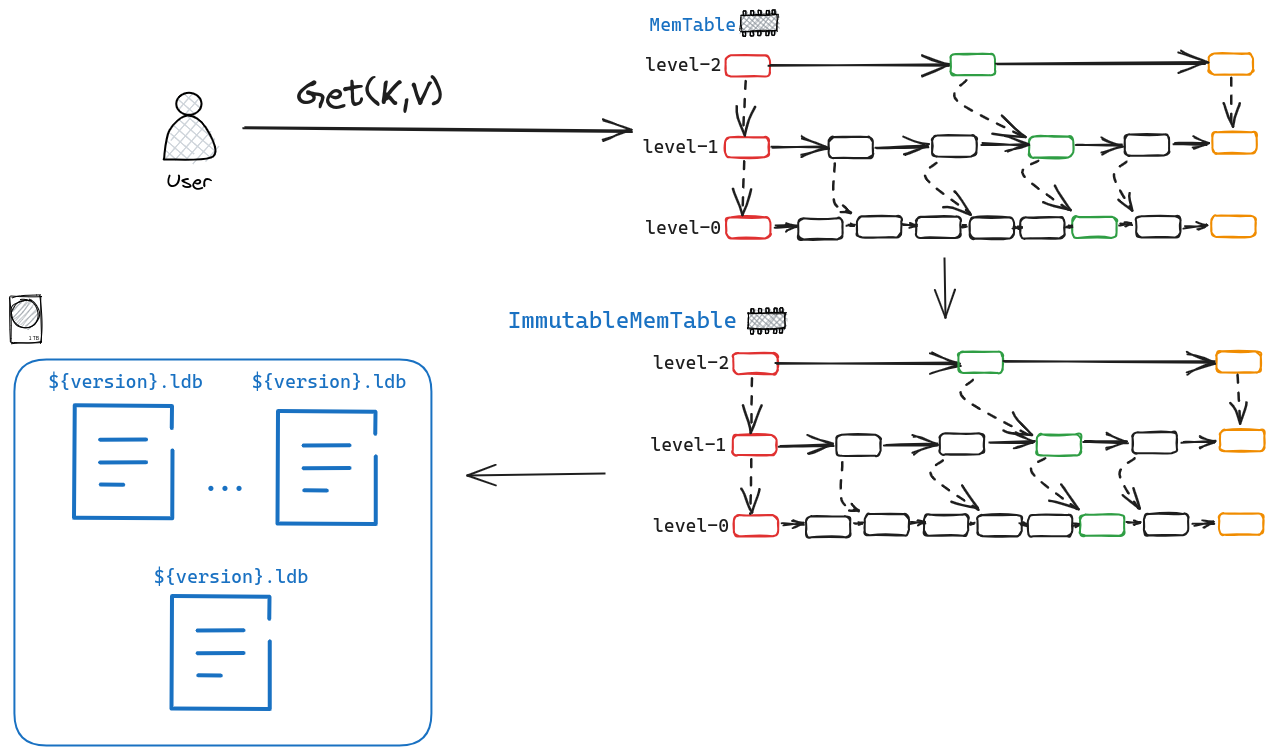
我们首先会尝试从MemTable中读取对应的KV,如果没获取到,我们会从ImmutableMemTable中读取,如果仍旧没读到,我们就会尝试去${version}.ldb中获取对应的KV。
因为MemTable与ImmutableMemTable的结构完全一致,他们的区别仅仅是一个是目前正在使用的MemTable,一个是已经达到Flush的阈值,准备往磁盘中写了。因此这篇文章会分为两部分来介绍
- 从
Memtable中读取KV。 - 从
${version}.ldb中读取KV。
Read From Memtable
还记得我们在 LevelDB(1) — 写中对于Memtable的描述,它会将用户输入的Key转化为InternalKey再插入,因此为了查询的时候,Key保持一致。我们也需要先将Key转化为InternalKey。
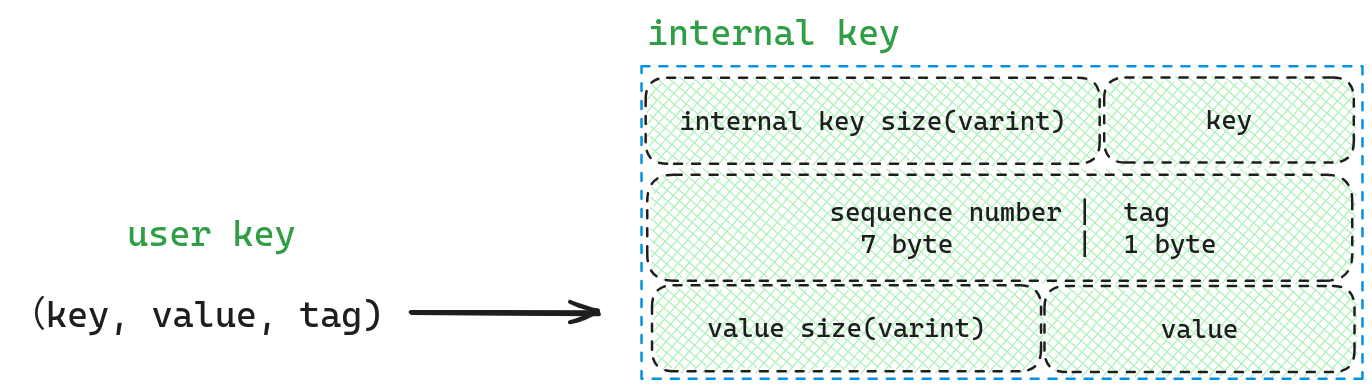
在这里sequence number为最大值(这样我们才能获取最新的数据),如果用户有指定snapshot。那么这个sequence number则为该snapshot的值。tag则为kValueTypeForSeek* ,因为我们排序数据项时会考虑序列号, 而且会在 user_key 部分相等时按照 tag (由七个字节序列号后跟一个字节 ValueType 构成)降序排列(tag 越大 internal_key 越小), 所以我们应该使用最大的 ValueType,这样调用 MemTable.Seek(k) 确保找到的第一个大于等于 k 的数据项(MemTable 中数据项从小到大排序)就是我们要找的数据项.
在完成InternalKey的构造后,我们开始在Memtable中查询数据。Memtable的整个查询接口都是由迭代器暴露出来的,因此我们先看一下迭代器的接口。
class Iterator {
public:
// Initialize an iterator over the specified list.
// The returned iterator is not valid.
//
// 构造方法返回的迭代器是无效的
explicit Iterator(const SkipList* list);
// Returns true iff the iterator is positioned at a valid node.
//
// 当且仅当迭代器指向有效的 node 时才返回 true.
bool Valid() const;
// Returns the key at the current position.
// REQUIRES: Valid()
//
// 返回迭代器当前位置的 key.
// 要求: 当前迭代器有效.
const Key& key() const;
// Advances to the next position.
// REQUIRES: Valid()
//
// 将迭代器移动到下个位置.
// 要求: 当前迭代器有效.
void Next();
// Advances to the previous position.
// REQUIRES: Valid()
//
// 将迭代器倒退一个位置.
// 要求: 当前迭代器有效.
void Prev();
// Advance to the first entry with a key >= target
//
// 将迭代器移动到第一个 key >= target 的数据项所在位置.
void Seek(const Key& target);
// Position at the first entry in list.
// Final state of iterator is Valid() iff list is not empty.
//
// 将迭代器移动到 skiplist 第一个数据项所在位置.
// 迭代器的最终状态是有效的, 当且仅当 skiplist 不为空.
void SeekToFirst();
// Position at the last entry in list.
// Final state of iterator is Valid() iff list is not empty.
//
// 将迭代器移动到 skiplist 最后一个数据项所在位置.
// 迭代器的最终状态是有效的, 当且仅当 skiplist 不为空.
void SeekToLast();
private:
const SkipList* list_;
Node* node_;
// Intentionally copyable
};这里面我们主要关注Seek
template<typename Key, class Comparator>
inline void SkipList<Key,Comparator>::Iterator::Seek(const Key& target) {
node_ = list_->FindGreaterOrEqual(target, nullptr);
}可以看到里面实际使用的还是SkipList::FindFreaterOrEqual
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node*
SkipList<Key,Comparator>::FindGreaterOrEqual(const Key& key, Node** prev)
const {
// head_ 为 SkipList 原始数据链表的起始节点,
// 该节点不存储用户数据, 仅用作哨兵.
Node* x = head_;
// 每次查找都是从最高索引层开始查找, 只要确认可能存在
// 才会降到下一级更细致索引层继续查找.
// 索引层计数从 0 开始, 所以这里减一才是最高层.
int level = GetMaxHeight() - 1;
while (true) {
// 下面用的 Next 方法是带同步设施的, 其实由于 SkipList 对外开放的操作
// 需要调用者自己提供同步, 所以这里可以直接用 NoBarrier_Next.
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// key 大于 next, 在该索引层继续向后找
x = next;
} else {
// key 可能存在.
//
// 如果 key 比 SkipList 中每个 node 的 key 都小,
// 那么最后返回的 node 为 head_->Next(0),
// 同时 pre 里面存的都是 dummy head;
// 调用者需要使用返回的 node 与自己持有 key进一步进行对比,
// 以确定是否找到目标节点.
if (prev != nullptr) prev[level] = x;
if (level == 0) {
// 就是它!如果 key 比 SkipList 里每个 node 的都大, 则 next 最终为 nullptr.
return next;
} else {
// 确定目标范围, 但是粒度太粗, 下沉一层继续找
level--;
}
}
}
}代码写的十分简单易懂,从最高层开始寻找,如果Key大于当前节点,那么往后继续找,否则下沉一层继续找,如果已经是最后一层了,那么返回该节点。
在找到节点后,我们根据InternalKey的格式将用户输入的key解析出来进行比较,如果不相等,那么返回未找到,如果相等说明我们查到了这个key的最新值,我们查看该节点的tag是kTypeValue 还是kTypeDeletion?如果是kTypeValue,那么我们找到了那个值,但如果是kTypeDeletion则说明该值已经被删除。
可以看到从Memtable中查询数据还相对较为简单,只要明白InternalKey的排列顺序即可。
Read From LDB FILE
如果从Memtable中无法找到对应的KV,那么我们就需要从文件中进行查找了。
这里我们分为两种情况,Level-0的的文件查找以及Level-1以上的文件查找。之所以要这么区分是因为Level-0各个文件的key可能重叠,例如file1的range为[0,100],file2的range为[50,200]。而level-1及以上的文件的key则不重叠,也就是不相交,因此我们会采用不同的方式来进行读取。查找的过程先从Level-0开始,而后逐级向上。这是因为Level越低,数据越新,如果我们得到了最新的数据,就不用再往下面找了。
1. 确定需要读取的文件
首先要做的就是要确定哪些文件。从下图中我们可以看到,对于Level-0以及其他Level,确定要读取的文件是不一样的。

因为Level-0中的文件key之间可能有重叠,因此我们需要一个个进行检查,而对于Level-x(x>1)来说,每个文件不相交,因此我们可以对他们按key排序后,进行二分查找,从而加快查找的速度。
2. 读取ldb文件,查找KV
在确定了读取的文件后,我们需要读取相应的文件,并检查需要查询的KEY是否在ldb文件中。
为了读取文件,我们会先尝试从TableCache中找到需要的文件Cache,如果没找到,我们再去磁盘中读取并反序列化为Table,将反序列化的Table插入到TableCache中。
2.1 TableCache的实现
目前LevelDB使用的缓存策略为LRU,我们先看一下Cache的接口。
class LEVELDB_EXPORT Cache {
public:
Cache() = default;
Cache(const Cache&) = delete;
Cache& operator=(const Cache&) = delete;
// 析构时调用构造时传入的 deleter 函数销毁每一个数据项.
virtual ~Cache();
// Cache 中存储的数据项的抽象类型, 具体实现参见 LRUHandle
struct Handle { };
/**
* 插入一对 <key, value> 到 cache 中, 同时为这个映射设置
* 一个对 cache 容量的消耗, 具体使用时候用的是要插入的数据
* 字节数.
*
* 该方法返回一个 handle, 对应本次插入的映射.
* 当调用者不再需要这个映射的时候, 需要调用 this->Release(handle).
*
* 当被插入的数据项不再被需要时, key 和 value 将会被传递给这里指定的 deleter.
* @param key 要插入的映射的 key
* @param value 要插入的映射的 value
* @param charge 要插入的映射对应的花费
* @param deleter 要插入的映射对应的 deleter
* @return 要插入的映射对应的 handle
*/
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) = 0;
/**
* 如果 cache 中没有针对 key 的映射, 返回 nullptr.
* 其它情况返回对应该映射的 handle.
* 当不再需要这个映射的时候, 调用者必须调用 this->Release(handle).
* @param key 要查询映射的 key
* @return 要查询的映射对应的 handle
*/
virtual Handle* Lookup(const Slice& key) = 0;
/**
* 先通过 Lookup 查询映射对应的 handle, 然后调用该函数来释放该映射.
*
* 前提一: handle 之前未被释放过.
* 前提二: handle 必须是通过在 *this 上调用某个方法返回的.
* @param handle 通过 Lookup 查询到的映射对应的 handle
*/
virtual void Release(Handle* handle) = 0;
/**
* 成功调用 Lookup 后返回的 handle 中封装的 value 可以通过该方法解析.
*
* 前提一: handle 之前未被释放过
* 前提二: handle 必须是通过在 *this 上调用某个方法返回的
* @param handle
* @return
*/
virtual void* Value(Handle* handle) = 0;
/**
* 如果 cache 包含了 key 对应的映射, 删除之.
* 注意, 底层的数据项将会继续存在直到现有的指向该数据项的全部 handles 已被释放掉.
* @param key 要删除的映射对应的 key
*/
virtual void Erase(const Slice& key) = 0;
/**
* 返回一个新生成的数字 id.
* 可能会被共享同一个 cache 的多个客户端用来对键空间进行分区.
*
* 典型地用法是, 某个客户端在启动时调用该方法生成一个新 id,
* 然后将该 id 作为它的 keys 的前缀.
* @return
*/
virtual uint64_t NewId() = 0;
/**
* 移除 cache 中全部不再活跃的数据项.
* 内存受限的应用可以调用该方法来减少缓存造成的内存消耗.
*
* 该方法的默认实现什么也不做, 强烈建议在派生类实现中重写该方法.
* leveldb 未来版本可能会将该方法修改为一个纯抽象方法.
*/
virtual void Prune() {}
/**
* 返回 cache 为了存储当前全部元素的总花费的估计值
* @return
*/
virtual size_t TotalCharge() const = 0;
private:
void LRU_Remove(Handle* e);
void LRU_Append(Handle* e);
void Unref(Handle* e);
struct Rep;
Rep* rep_;
};对于Cache接口的实现则为ShardedLRUCache,它维护了多个cache shard,从而在并发访问时,无须使用一把大锁,而是可以更加细粒度的加锁,从而提升并发时的性能。
我们看一下ShardedLRUCache::Insert的实现
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
// 计算 hash
const uint32_t hash = HashSlice(key);
// 基于 hash 做 sharding
return shard_[Shard(hash)].Insert(key, hash, value, charge, deleter);
}从代码中,我们可以看到ShardedLRUCache只计算key所属的shard,然后具体的逻辑由LRUCache执行。
/**
* 该方法类似 Cache::Insert() 不过多了一个 hash 参数.
* 该方法线程安全, 允许多个线程并发向同一个 shard 中插入.
*
* @param key 要插入的数据项的 key
* @param hash 要插入的数据项的 hash
* @param value 要插入的数据项的 value
* @param charge 要插入的数据项的 charge
* @param deleter 要插入的数据项的 deleter
* @return 返回插入的数据项的句柄
*/
Cache::Handle* LRUCache::Insert(
const Slice& key, uint32_t hash, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
MutexLock l(&mutex_);
// 基于 LRUHandle 本身大小和 key 的实际长度来分配空间.
// 减掉的 1 指的是 LRUHandle 初始化时为 key_data 预占的空间,
// 不减掉的话后面加上 key.size() 就多了一个字节.
LRUHandle* e = reinterpret_cast<LRUHandle*>(
malloc(sizeof(LRUHandle)-1 + key.size()));
e->value = value;
e->deleter = deleter;
e->charge = charge;
e->key_length = key.size();
e->hash = hash;
e->in_cache = false;
// 能存在于 cache 中的最小 ref 值,
// 表示当前除了 cache 对象还没有任何外部引用.
e->refs = 1;
memcpy(e->key_data, key.data(), key.size());
if (capacity_ > 0) {
// 放入 in_use_ 列表就要增加引用.
e->refs++;
// 该数据项被放到了 shard 中
e->in_cache = true;
// 将该数据项追加到 shard 的 in_use 链表
LRU_Append(&in_use_, e);
usage_ += charge;
// 将数据项插入到 hashtable, 这可以看做一个二级缓存.
// 如果 shard 中存在与 e "相同的 key 相同的 hash" 的项,
// 则将 e 插入同时将老的数据项从 shard 彻底删除.
FinishErase(table_.Insert(e));
} else {
// 如果 capacity_<= 0 意味着关闭了缓存功能.
// 此处的赋值是防止 key() 方法的 assert 失败.
e->next = nullptr;
}
// 下面这个循环解释了 LRUCache 的 LRU 效果.
// 如果本 shard 的使用量大于容量并且 lru 链表不为空,
// 则从 lru 链表里面淘汰数据项, lru 链表数据当前肯定未被使用,
// 直至使用量小于容量或者 lru 清空.
while (usage_ > capacity_ && lru_.next != &lru_) {
// 这很重要, lru_.next 是 least recently used 的元素
LRUHandle* old = lru_.next;
// lru 链表里面的数据项除了被该 shard 引用不会被任何客户端引用
assert(old->refs == 1);
// 从 shard 将 old 彻底删除
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) {
// to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
// 将 LRUHandle 重新解释为 Cache::Handle
return reinterpret_cast<Cache::Handle*>(e);
}我们首先会malloc一个新的LRUHandle,然后对该LRUHandle进行赋值。随后我们直接使用头插法将这个LRUHandle插入链表中,并且如果这个key之前缓存过,那么我们将旧缓存删除,最后如果发现使用量超过限额,就尝试去除过期的数据。
我们再看看查找的代码,可以发现代码相当简单,通过key去hashtable中找到对应的LRUHandle并返回。
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
// table_ 是个哈希表, 存储了该 shard 全部数据项的指针,
// O(1) 复杂度.
LRUHandle* e = table_.Lookup(key, hash);
if (e != nullptr) {
// 如果查到, 则将该数据项引用数加 1,
// 查询命中后续就要.
Ref(e);
}
return reinterpret_cast<Cache::Handle*>(e);
}2.2 LDB的反序列化与查找
反序列化LDB文件的入口函数为Table::Open, 我们配合着LDB的Layout来理解LDB的反序列化。
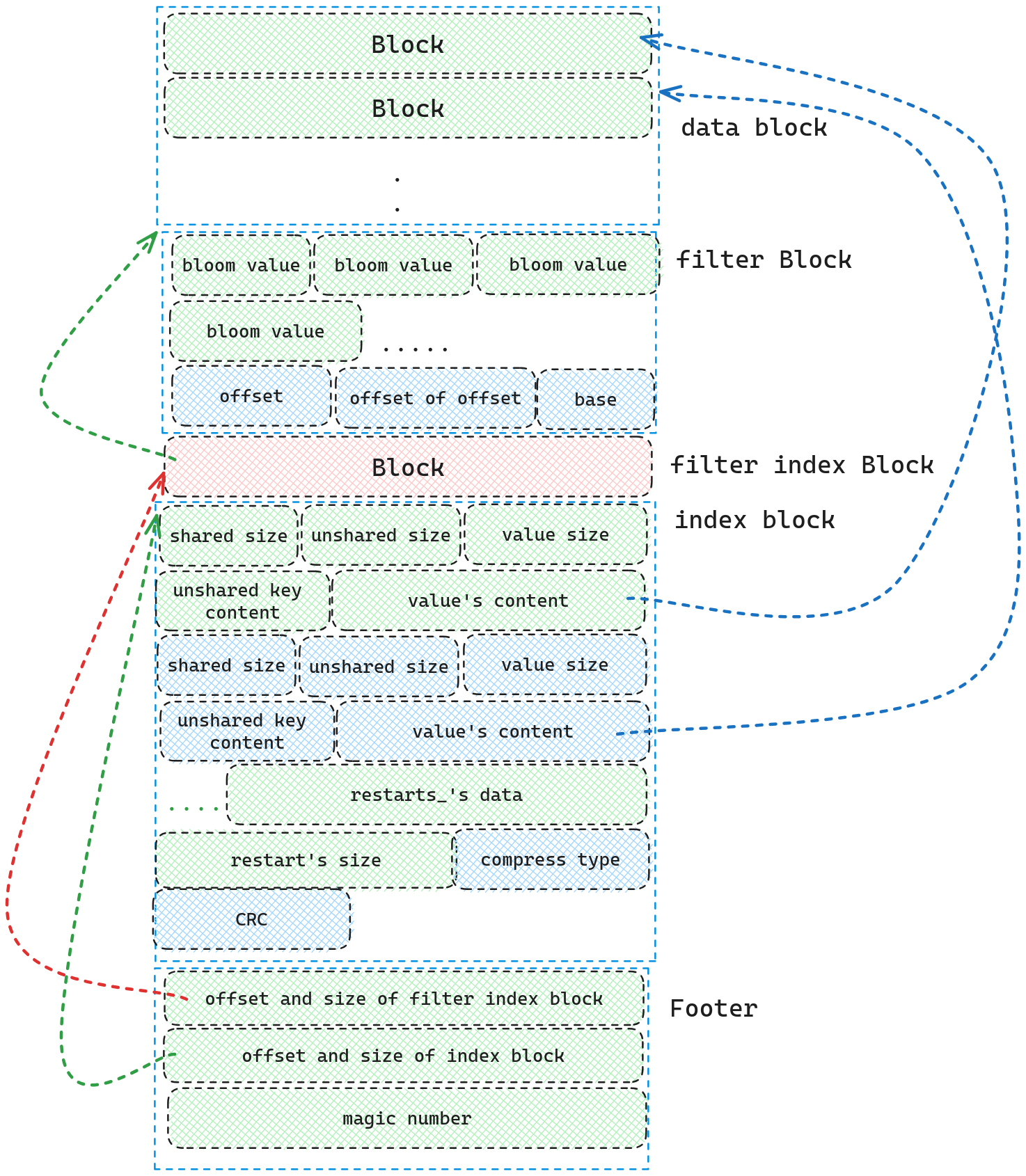
我们首先读取Footer获得index Block,filter index block的位置和大小,随后我们通过index block的位置和大小解析出index Block的内容(这里我们仅仅只是通过CRC检查文件完整性,及其根据compress type来解压文件,并不做更进一步的解析),然后我们再根据filter index block解析出filter block(这里我们会将filter block的base, offset, bloom value全部解析出来)。注意,我们并不会解析data block.
到了这里,我们就算将ldb文件反序列化为Table了。下面我们看一下查找的过程。
// 在 table 中查找 k 对应的数据项.
// 如果 table 具有 filter, 则用 filter 找;
// 如果没有 filter 则去 data block 里面查找,
// 并且在找到后通过 saver 保存 key/value.
// 注意, 针对 data block 的读取和解析发生在这个方法里.
Status Table::InternalGet(const ReadOptions& options, const Slice& k,
void* arg,
void (*saver)(void*, const Slice&, const Slice&)) {
Status s;
// 针对 data index block 构造 iterator
Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator);
// 在 data index block 中寻找第一个大于等于 k 的数据项, 这个数据项
// 就是目标 data block 的 handle.
iiter->Seek(k);
if (iiter->Valid()) {
// 取出对应的 data block 的 BlockHandle
Slice handle_value = iiter->value();
FilterBlockReader* filter = rep_->filter;
BlockHandle handle;
// 如果有 filter 找起来就快了, 如果确定
// 不存在就可以直接反悔了.
if (filter != nullptr &&
handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) {
// 没在该 data block 对应的过滤器找到这个 key, 肯定不存在
} else {
// 如果没有 filter, 或者在 filter 中查询时无法笃定
// key 不存在, 就需要在 block 中进行查找.
// 看到了没? Open() 方法没有解析任何 data block, 解析
// 是在这里进行的, 因为这里要查询数据了.
Iterator* block_iter = BlockReader(this, options, iiter->value());
block_iter->Seek(k);
if (block_iter->Valid()) {
// 将找到的 key/value 保存到输出型参数 arg 中,
// 因为后面会将迭代器释放掉.
(*saver)(arg, block_iter->key(), block_iter->value());
}
s = block_iter->status();
delete block_iter;
}
}
if (s.ok()) {
s = iiter->status();
}
delete iiter;
return s;
}我们首先会在index block中寻找刚好大于等于k的数据项,从而可以快速定位到data block,当然在往data block中查找前,我们可以先使用布隆过滤器来确定该值是否在这个data block 中,如果说在的话,我们就可以直接在data block中进行查找,并返回查找结果。
Overview
本文介绍了LevelDB的读操作的流程。这篇文章并没有将所有的细节都写出来,如果你想要详细了解,我推荐你还是需要去读相关代码。这篇文章更侧重描写出LevelDB的大概轮廓,以及一些比较重要的细节。希望对你理解LevelDB相关代码有所帮助。