LevelDB(1) -- 写
本文将介绍LevelDB是如何存储写入数据, 以及数据在磁盘中的存储格式.
Overview
我们先看一下LevelDB整体的写流程是什么样子的.
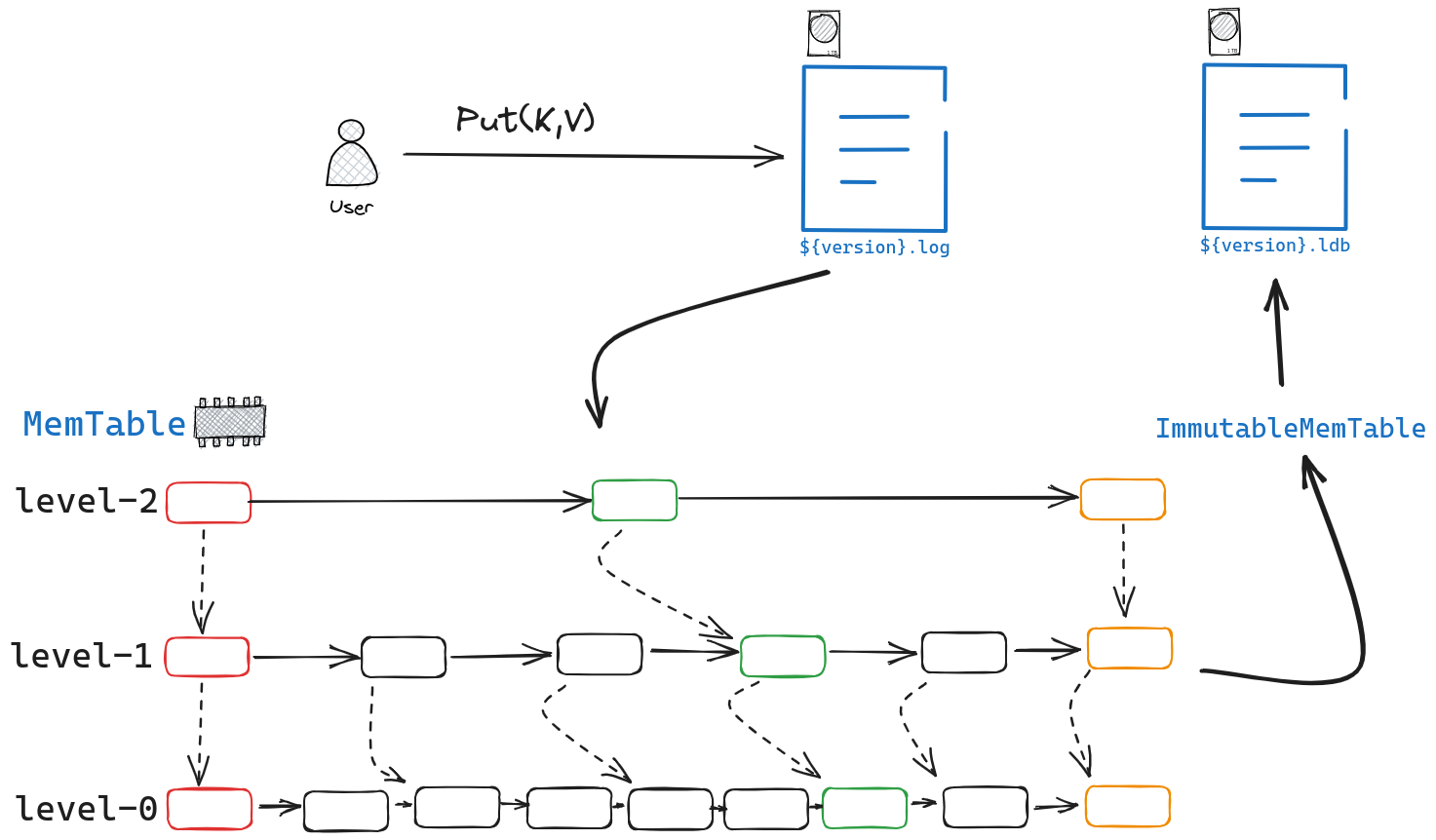
从图中可以看出levelDB采用经典的WAL方式来进行写入,即先将写入的操作写到log文件中,再将实际的数据写到内存中的Memtable中(Memtable采用skipList实现),当Memtable达到阈值后再将其转化为ImmutableMemTable,最终将其落盘持久化保存.
因此本文后面将主要介绍
- log文件的格式与生成
- memtable的实现
- ldb文件的格式与生成
写操作的生成
在讲述文件的格式与生成之前,我们需要先描述写操作是如何生成.
当用户调用DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) 时,我们会将key,value包装成一个WriteBatch,顾名思义,WriteBatch中会有许多的写操作.其定义如下所示.
class LEVELDB_EXPORT WriteBatch {
public:
WriteBatch();
// skip ....
// Intentionally copyable.
WriteBatch(const WriteBatch&) = default; // 默认拷贝构造
WriteBatch& operator =(const WriteBatch&) = default; // 默认赋值构造
// skip ....
// Store the mapping "key->value" in the database.
void Put(const Slice& key, const Slice& value);
~WriteBatch();
// skip ....
private:
std::string rep_; // See comment in write_batch.cc for the format of rep_
};
} // namespace leveldb我们可以看到其本质就是一个string,我们会将写操作通过Put接口将其写入到rep_中,WriteBatch在内存中的格式如下图所示.
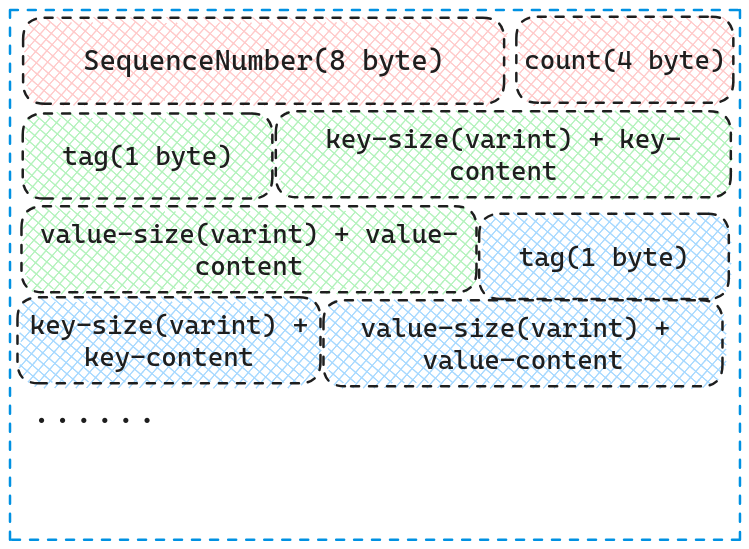
从图中可以看到,WriteBatch由SequenceNumber,count以及count个KV对组成, 其中前8个byte为SequenceNumber(LevelDB中写操作的唯一自增编号),紧跟着的4个byte为存储的KV对个数。KV对则由tag,key-size And key's content, value-size And value's content构成。
其中tag为枚举类型,kTypeDeletion表明删除,kTypeDeletion表明增加.
enum ValueType {
kTypeDeletion = 0x0,
kTypeValue = 0x1
};在生成WriteBatch后(此时WriteBatch中仅有用户输入的KV对),我们生成Writer, 并将WriteBatch存入Writer中。
struct DBImpl::Writer {
Status status;
WriteBatch* batch;
bool sync;
bool done;
port::CondVar cv;
explicit Writer(port::Mutex* mu) : cv(mu) { }
};随后,我们会将Writer放到队列中(一个经典的生产者,消费者模型)。当该Writer为队首时才会被拿出来执行。
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}当该Writer被拿出来执行时,我们首先会确保Memtable仍然有较为充足的空间给它进行写入,不然的话我们可能要进行compact(目前可以不关注,后续在讲compact的时候会详细阐述,这里先假定空间一定充足)。
此时,我们会尝试将多个WriterBatch合并为一个后一起执行。具体逻辑可以参考代码
WriteBatch* DBImpl::BuildBatchGroup(Writer** last_writer) {
mutex_.AssertHeld();
assert(!writers_.empty());
// 取出队首 writer
Writer* first = writers_.front();
// 取出队首 writer 的待写数据集
WriteBatch* result = first->batch;
assert(result != nullptr);
// 计算队首 writer 数据集大小
size_t size = WriteBatchInternal::ByteSize(first->batch);
// 虽然支持合并, 但是有两个限制条件:
// 1. 不合并同步写入操作(设置了 writer.sync), 发现同步写操作立马停止后续合并操作并返回已合并内容.
// 2. 为了避免小数据量写入操作被延迟太久, 针对合并上限做了限制, 最大 1MB.
size_t max_size = 1 << 20;
// 如果队首 writer 要写内容大小不超过 128KB
if (size <= (128<<10)) {
// 则 max_size 改为不超过 256KB
max_size = size + (128<<10);
}
*last_writer = first;
std::deque<Writer*>::iterator iter = writers_.begin();
++iter; // Advance past "first"
// iter 从 first 之后 writer 开始遍历
for (; iter != writers_.end(); ++iter) {
Writer* w = *iter;
// 同步写操作不做合并
if (w->sync && !first->sync) {
// Do not include a sync write into a batch handled by a non-sync write.
break;
}
if (w->batch != nullptr) {
size += WriteBatchInternal::ByteSize(w->batch);
if (size > max_size) {
// 避免 batch group 过大
break;
}
// Append to *result
if (result == first->batch) {
// 不篡改 first writer 的 batch, 而是把若干 batch 合并到临时的 tmp_batch_ 中
result = tmp_batch_;
assert(WriteBatchInternal::Count(result) == 0);
WriteBatchInternal::Append(result, first->batch);
}
WriteBatchInternal::Append(result, w->batch);
}
// last_writer 指向被合并的最后一个 writer
*last_writer = w;
}
return result;
}简单来说,遍历待执行的WriteBatch,只要它
- 不要求同步
- 合并后不会导致WriteBatch大小超过
max_size。
都会被合并,但只要违反上述任意一条,合并流程就会终止。
经过上述流程,我们完成了对写操作的所有预处理,可以进行真正的写操作了。
log文件的格式与生成
在生成了待写入的WriteBatch后,我们首先将其写入到log文件中。log文件的内部格式是通过block进行组织的,具体结构如下图所示。
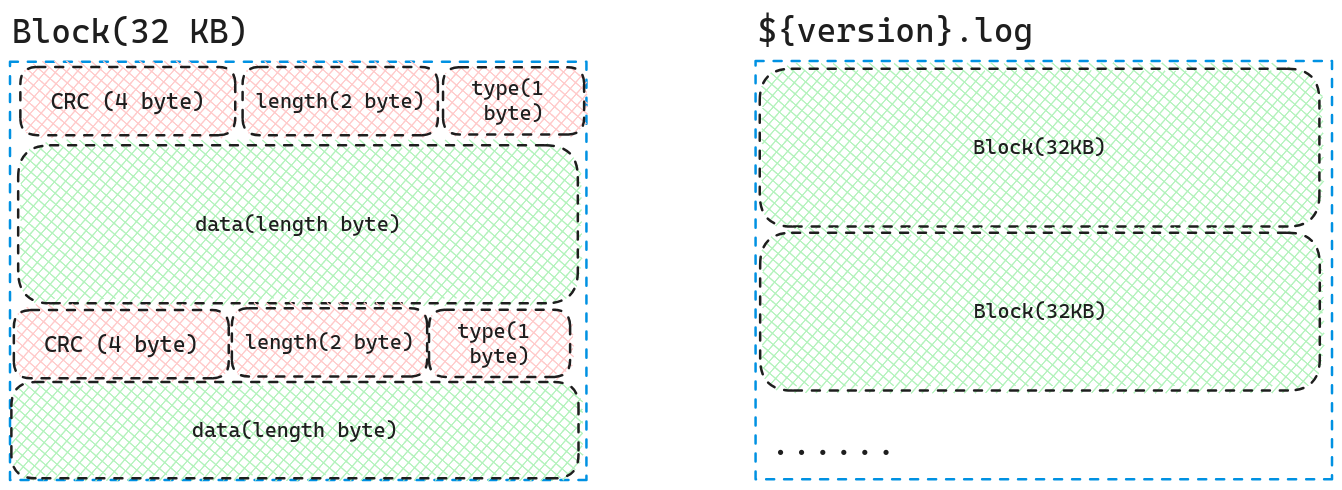
我们可以看到log文件是由一个个Block组成的,而每一个Block的大小都是固定的32KB,Block中存储着多个WriteBatch:头四个byte为校验和,后两个byte为data的长度,后续的一个byte为type(前七个byte被统称为Header),最后剩下的就是data的数据,也就是WriteBatch中的rep_。
如果一个block剩余空间不足以存储Header,也就是他剩下的存储空间小于7byte,那么我们会对这个Block末尾填充0,然后将数据写到新的Block中。
现在我们来讲一下Header中的type代表着什么。考虑这么一种情况,如果block中的剩余空间太小,以致于我们的WriteBatch无法全部存储在该Block中,那么我们可能要将数据分为不同的块存储到不同的Block中,为了后续读的时候可以知道,这是不是一个完整的块,以及何时读完了完整的块。我们需要type来进行标识。
type依旧为枚举类型.
enum RecordType {
// Zero is reserved for preallocated files
kZeroType = 0,
kFullType = 1,
// For fragments
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
};其中
- kFullType 表明后续的data数据为完整的数据
- kFirstType 表明这是分块后的第一块数据,仍需要继续读取
- kMiddleType表明这是分块后的中间数据,仍需要继续读取
- kLastType 表明这是分块后的最后一块数据,无需读取。
在将WriteBatch的数据写入到log文件后,我们就完成了写入的第一步,写日志。
MemTable的实现
在将writeBatch写入到log文件后,我们便可以将数据写入MemTable中。
我们会对writeBatch中的(tag,Key,value)进行遍历,根据tag的不同,决定是向MemTable添加还是删除。
因为MemTable的内部实现是skiplist,而skiplist只能回答key在不在,而不能回答key关联的value是什么,因此我们需要将用户输入的(key,value)转化为skiplist中内部使用的key。
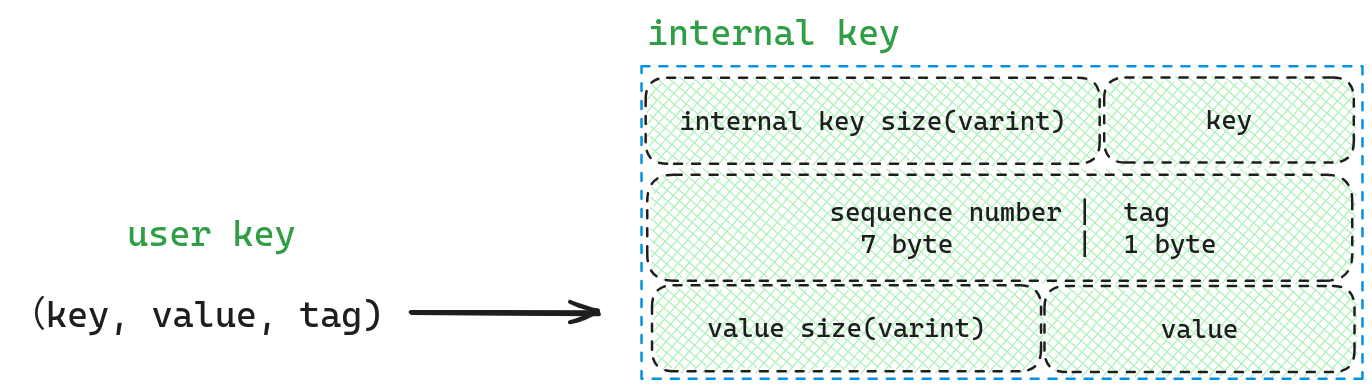
从图中可以发现,key和value中间被(sequence number , tag)隔开,这样的目的是为了后续在排序时,我们可以先按照key从小到大排序, 当key相同时,(sequence number, tag)按照由大到小排序,通过这种方式,永远是版本最新的在最前面((sequence number, tag)越大,版本越新)。
最后就是向MemTable中插入该internal key。
template<typename Key, class Comparator>
void SkipList<Key,Comparator>::Insert(const Key& key) {
// pre 将用于存储 key 对应的各个索引层的前驱节点
Node* prev[kMaxHeight];
// 找到第一个大与于目标 key 的节点, 一会会把 key
// 插到这个节点前面.
// 如果为 nullptr 表示当前 SkipList 节点都比 key 小.
Node* x = FindGreaterOrEqual(key, prev);
// 虽然 x 是我们找到的第一个大于等于目标 key 的节点,
// 但是 leveldb 不允许重复插入 key 相等的数据项.
assert(x == nullptr || !Equal(key, x->key));
// 确定待插入节点的最大索引层数
int height = RandomHeight();
// 更新 SkipList 实例维护的最大索引层数
if (height > GetMaxHeight()) {
// 如果最大索引层数有变, 则当前节点将是索引层数最多的节点,
// 需要将前面求得的待插入节点的前驱节点高度补齐.
for (int i = GetMaxHeight(); i < height; i++) {
// 新生成了几个 level, key 对应的前驱节点肯定都是 dummy head
prev[i] = head_;
}
//fprintf(stderr, "Change height from %d to %d\n", max_height_, height);
// 这里在修改 max_height_ 无需同步, 哪怕同时有多个并发读线程.
// 其它并发读线程如果观察到新的 max_height_ 值,
// 那它们将会要么看到 dummy head 新的索引层(注意 SkipList
// 初始化时会把 dummy head 的索引高度直接初始化为最大, 默认是 12,
// 所以不存在越界问题)的值都为 nullptr, 要么看到的是
// 下面循环将要赋值的新节点 x.
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
}
// 为待插入数据创建一个新节点
x = NewNode(key, height);
// 将 x 插入到每一层前后节点之间, 注意是每一层,
// 插入的时候都是先采用 no barrier 方式为 x 后继赋值, 此时 x 还不会被其它线程看到;
// 然后插入一个 barrier, 则上面 no barrier 的修改针对全部线程都可见了(其中也包括
// 了 NewNode 时可能发生的通过 NoBarrier_Store 方式修改的 arena_.memory_usage_),
// 最后修改 x 前驱的后继为自己.
for (int i = 0; i < height; i++) {
// 注意该循环就下面两步, 而且只有第二步采用了同步设施, 尽管如此,
// 第一步的写操作对其它线程也是可见的.
// 这是 Release-Acquire ordering 语义所保证的.
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}为了可以读懂上面的代码,我们先来阐述一下LevelDB是如何实现skiplist的。
首先我们先看一下SkipList::Node的定义
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
explicit Node(const Key& k) : key(k) { }
Key const key;
Node* Next(int n) {
assert(n >= 0);
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
void SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].Release_Store(x);
}
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].NoBarrier_Store(x);
}
private:
// Array of length equal to the node height.
// next_[0] is lowest level link.
port::AtomicPointer next_[1];
};从代码中,我们看到Node有两个成员变量,一个是key,一个是next_,key没有什么好说的,主要需要理解的是next_,简单点来说,next_的长度等于Node的高度,next_[i]为Node在level-i的后继节点。通过下图,相信你可以更好理解。
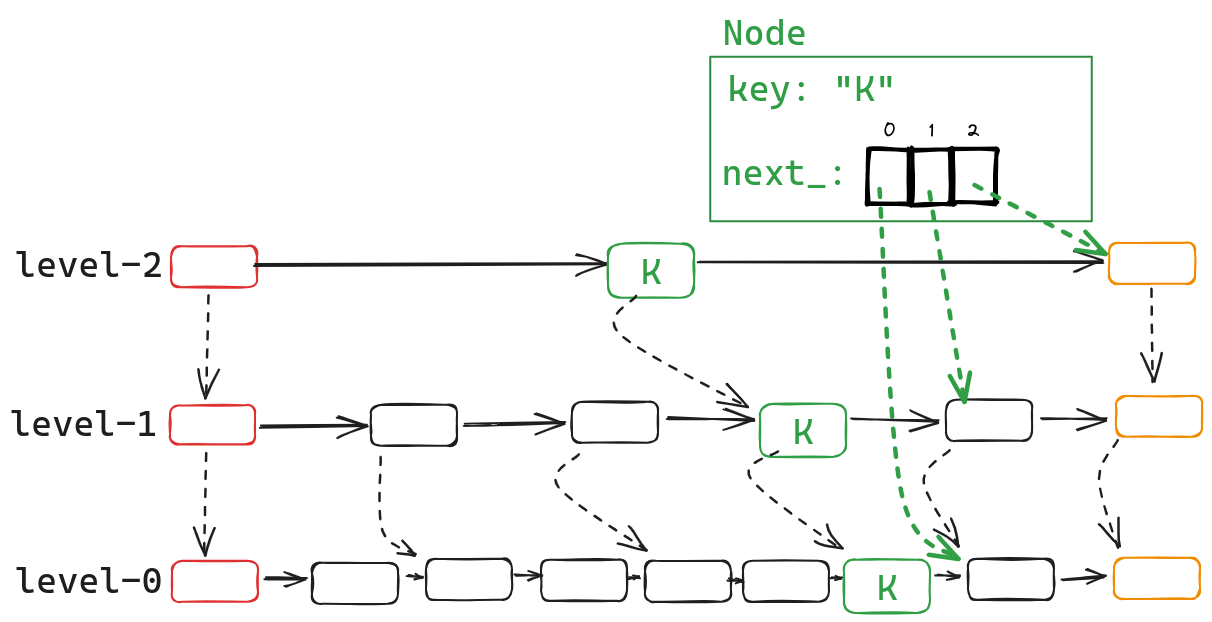
了解完Node后,我们还需要知道SkipList::head_,这个成员变量是一个dummy node,它的类型也是Node,它的next_点保存着每一个level的首节点。
因此插入的过程可以描述为
- 找到第一个大与于目标 key 的节点, 一会会把 key插到这个节点前面,如果为 nullptr 表示当前 skipList 节点都比 key 小.同时会记录每一层刚好比key小的节点。
- 为该节点随机生成一个层数,作为该节点的最大层数。
- 通过之前找到的刚好比他大的节点,以及刚好比他小的节点,将该节点插入进skiplist.
当将WriteBatch所有的(key, value,tag),全部插入MemTable后,我们可以认为插入的过程已经全部完成了,剩下的就是将之前合并到新的WriteBatch的那些Writer移出队列,并唤醒队列的头部Writer,相信通过代码,可以很容易理解。
while (true) {
// [&w, last_writer] 的 batch 被合并写入 log 了, 所以将其出队.
Writer* ready = writers_.front();
writers_.pop_front();
// &w 并没有 wait, 它是本次负责合并写入的 writer,
// 所以它 &w 的 status 和 done 可以不用改, 反正也用不到.
if (ready != &w) {
// 传递合并写执行结果给 group 中各个 writer
ready->status = status;
ready->done = true;
// 唤醒当前方法入口的 w.cv.Wait(), 通过此处被唤醒的
// writers 都是被合并到队首 writer 统一写入 log 文件的.
// 它们被唤醒后, 只需检查下 done 状态就可以返回了.
ready->cv.Signal();
}
// last_writer 指向被合并处理的最后一个 writer
if (ready == last_writer) break;
}
// 如果当前 writers_ 队列不为空, 唤醒当前的队首节点.
if (!writers_.empty()) {
// 叫醒新的待写入 writer
writers_.front()->cv.Signal();
}ldb文件的格式与生成
当把WriteBatch所有的(key, value,tag),全部插入MemTable后,Put流程就算结束了。 ldb文件的格式与生成,应当属于compact中的内容。但是趁现在对MemTable的记性还比较新,可以顺便将ldb文件一起讲了。而且ldb文件本质上就是将MemTable落盘,内容上也不算突兀。
ldb文件由五部分组成
- data blocks
- filter blcoks
- filterindex block
- index block
- footer
其中data blocks中保存着KV数据,filter blocks中存储着布隆过滤器,filterindex block存储着指向filter blocks的索引,index block存储着指向data blocks的索引,footer存储着指向filterindex block和index block的索引。
我们先看一下组成data block以及index block的基础组成部分。
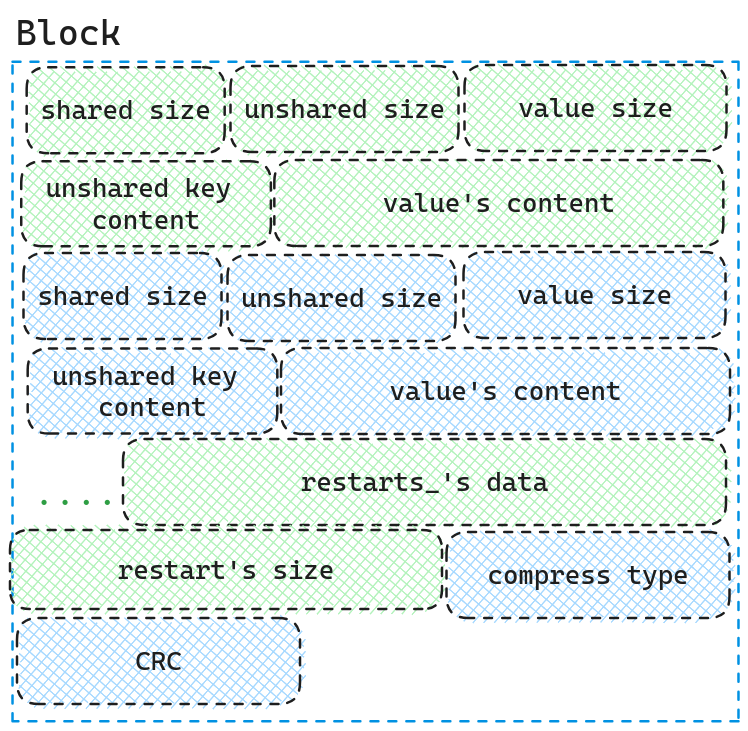
因为data block和index block都是由KV组成,data block的Key是skipList的internal key, Value是用户输入的Value.index block的Key是每个data block的最后一个Key, Value是data block的handle.
我们可以详细看一下这个Block的结构组成,因为我们的Key是按照顺序的,因此我们可以使用仅存储两个Key不同的部分,从而减少空间占用,因此我们先存储两个Key相同的长度大小,需要存储的Key的大小,Value的长度大小,存储的Key的内容,存储的Value内容.我们可以通过下面的例子更好的阐述一下这个概念
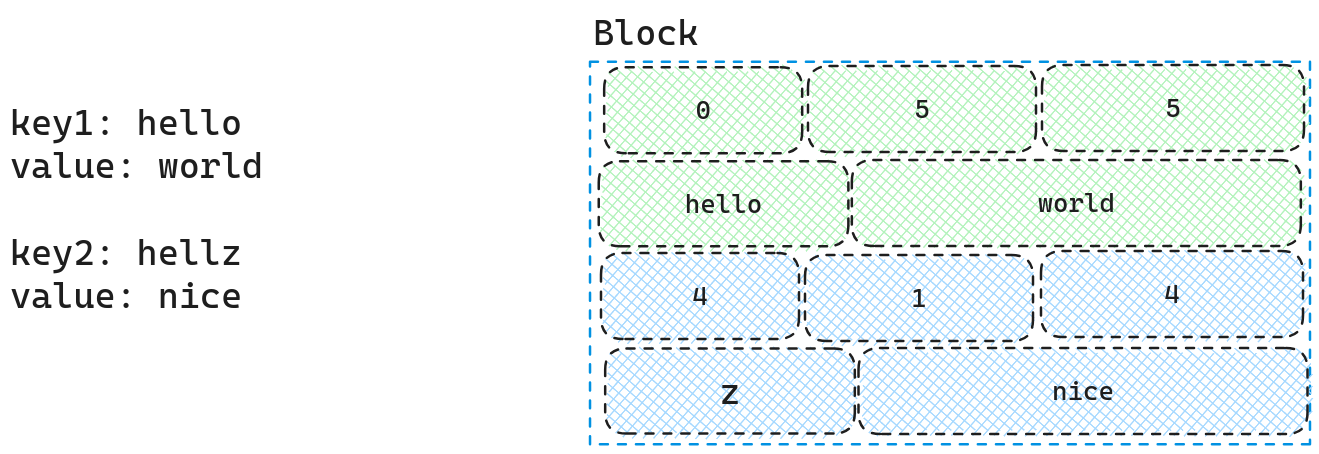
如图所示,因为hello以及hellz共享hell,因此对于hellz我们仅需要存储z即可.
每个 block 的前缀压缩不是从第一个数据项开始就一直下去, 而是每隔一段(间隔可配置)设置一个新的前缀压缩起点(作为新起点的数据项的 key 保存原值而非做前缀压缩), restart指的就是新起点, 从这个地方开始继续做前缀压缩.在写入文件前,我们还需要对KV对以及restart数据一起进行压缩,压缩的方式由compress type表示,
因此单个Block由KV对, restart数组,restart数组长度,压缩类型,CRC校验和组成.而data block以及index block则是由一个个Block组成.
而filter block则是根据data block的大小生成布隆过滤器,默认每2K个大小生成一个布隆过滤器.它的存储结构为
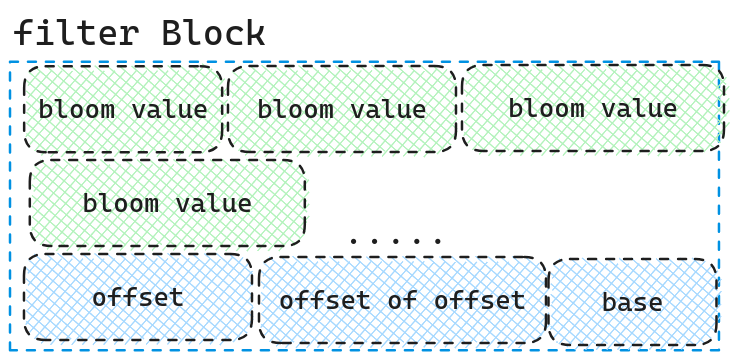
开始存着一系列的布隆过滤器,然后是各个布隆过滤器的offset数组,紧跟着offset的offset(通过该值找到offset,因为offset是数组是一个变值),最后跟的是这个filter block的元信息(data block数据多大后产生一个布隆过滤器)
而filter index block则使用Block的存储格式存储着Key: “filter.$(filter.name)”, Value: offset and size of filter block
最后的Footer的格式则为下图所示.

Footer中存储着filter index block的指针以及index block的指针以及magic number
在介绍完各个模块的磁盘结构后,我们可以看一下ldb文件的全貌,以及各部分之间的关系,如下图所示.
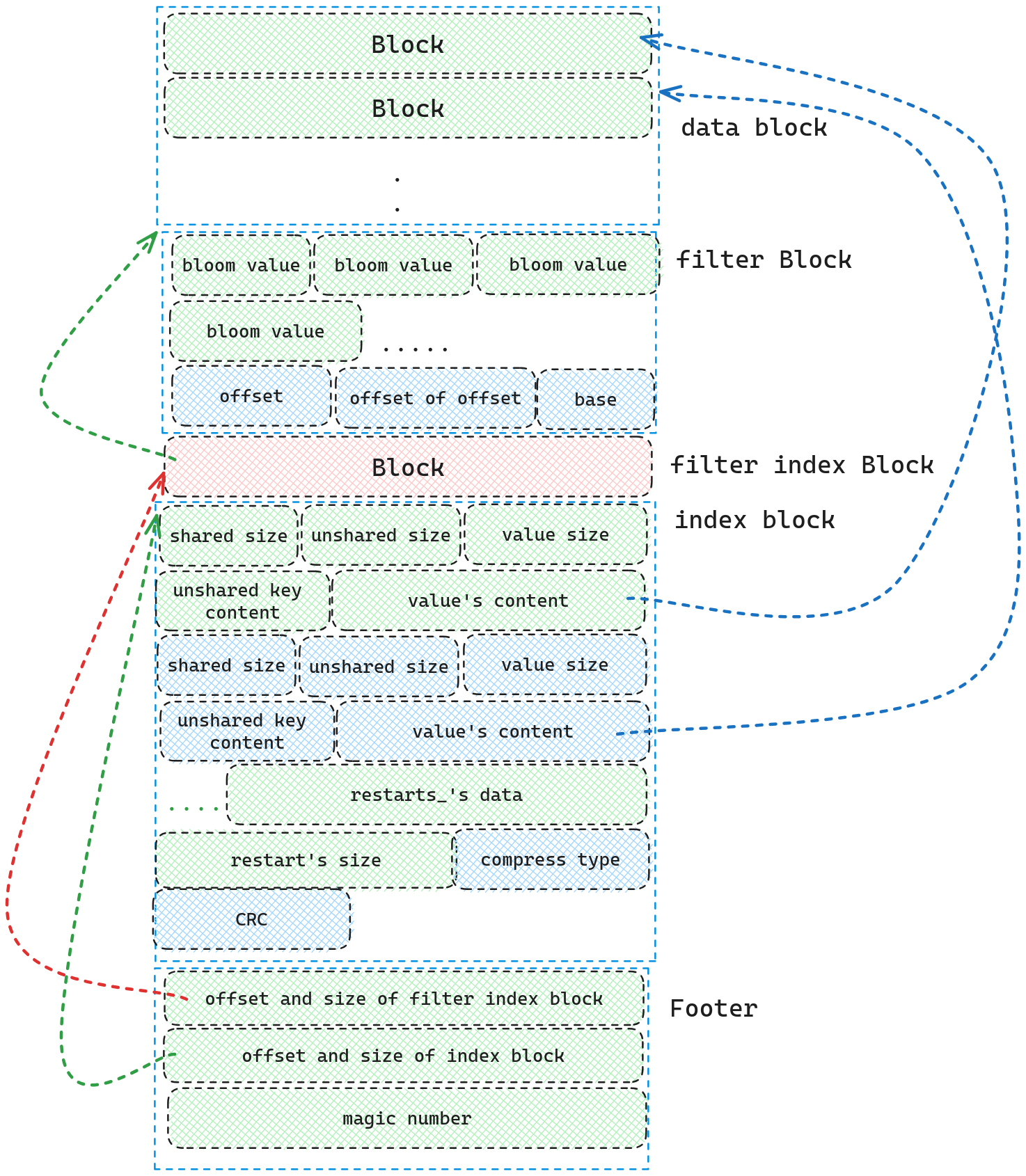
在了解了整个全貌后,我们可以看一下整个生成的流程是怎么样的.
- 首先构建出一个新的
TableBuilder, 然后按序将Memtable中的数据写入TableBuilder. TableBuilder将数据全部写入data block中 (按照Block的格式写)- 当Block的大小超过4K时,将生成的
data block落盘,尝试生成一个filter block,并生成一个index handle,将其插入到index block中.(注意,这里插入index block前,会尝试缩短key的大小,详情请参考代码Comparator::FindShortestSeparator).
最后等所有数据添加完后,依次写入data block, filter block, filter index block, index block,以及footer
Overview
本文介绍了LevelDB的写操作的流程,以及相关文件的生成与格式。这篇文章并没有将所有的细节都写出来,如果你想要详细了解,我推荐你还是需要去读相关代码。这篇文章更侧重描写出LevelDB的大概轮廓,以及一些比较重要的细节。希望对你理解LevelDB相关代码有所帮助。