有趣的知识 -- CPU利用率,延迟,吞吐量之间的关系
本文从排队论的角度出发分析CPU利用率,延迟和吞吐量之间的关系,这篇文章大量参考喵叔的文章, 油管视频, 本质上只是简单的复述,作为我自己学习的整理。
CPU利用率和延迟之间的关系
做在线服务的时候,我们经常会给CPU利用率设置一个阈值,如果超过了这个阈值,我们会对服务扩容。这个阈值到底应该如何选择,为什么当CPU利用率到达了50%(意味着它有一半时间是空闲的),我们就需要对其进行扩容? 要回答这些问题就意味着,我们不能仅仅对CPU和延迟有一个感性的认识,而应该有一个定量的描述。
1. Little’s Law
Little’s Law 是排队论中的一个重要定律,由 John D. C. Little 在 1961 年提出。该定律指出,在一个系统中,平均的顾客数等于平均的到达率乘以平均的服务时间。 换算到计算机中即系统中的平均请求数等于单位时间内的请求数量乘以平均的处理时间,其公式可以表示为
其中:
: 系统中的平均请求数,即当前正在处理以及待处理的请求
: 单位时间内到达的请求数,即QPS
: 单个请求的平均处理时间, 即延迟
2. 模型构建
在得知上述定理后,我们可以对我们的服务进行一个简单的模型构建M/M/1模型
- 我们只有一个服务器
- 服务器一次只处理一个请求
- 请求的到来服从泊松分布
- 请求的处理时间服从泊松分布
因为整个服务是动态的,每时每刻待处理的请求数量都是变化的,但是它们都服从马尔科夫链,其中每个状态的变化都是一个泊松过程。
因此如果当前状态为 , 那么它的上一个状态为 ( ), 由于整个系统处于平稳的状态,所以离开状态的速率等于进入状态的速率, 即
其中:
代表状态的概率,即请求数量为的概率
代表状态的概率,即请求数量为的概率
代表QPS
代表单位时间内处理请求的数量
根据上面的式子,我们可以得到如下的递推式
我们可以从上述公式推导出
又由于所有的概率之和为1
同样的我们如果按照这个模型来计算平均待处理的请求数,可以得到
将P(X=0)代入可以得到
再通过Little’s Law的公式我们可以得到
整个推导过程较长,你可以只记住最后一个公式,最后我们得到延迟和QPS以及单位时间处理请求量之间的关系。
3.CPU利用率的表示
我们可以将CPU的利用率看作一段时间内的请求数量除以同一段时间内CPU最大可处理的请求数量,那么我们有以下公式
将其代入第二节我们得到的公式可以得到延迟与CPU利用率之间的关系
那么这个图具体长什么样呢?我们可以通过Walfram查看
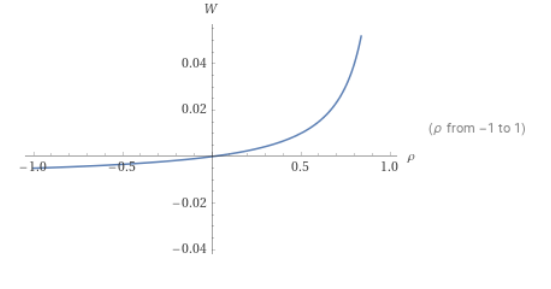
从这幅图中我们可以发现随着CPU利用率的提升,延迟会快速的增长,我们可以通过下面的数据更具体的感受这一关系
| CPU usage | latency | latency increase |
|---|---|---|
| 0.2 | 0.0025 | |
| 0.3 | 0.0042 | 68% |
| 0.4 | 0.006 | 42% |
| 0.5 | 0.01 | 66% |
| 0.6 | 0.015 | 50% |
| 0.7 | 0.023 | 53% |
| 0.8 | 0.040 | 73% |
| 0.9 | 0.090 | 125% |
| 0.99 | 0.99 | 1000% |
可以看到每次CPU利用率提升10%,延迟就会增加50%以上。如果CPU利用率到达80%,延迟的增长率甚至能到125%. 所以,我们可以得出以下结论
- 为什么有时候CPU利用率到达了50%就需要扩容? 因为延迟的增长和CPU的利用率并不是线性增长.
- 如果CPU利用率到达了80%,就需要高度重视服务的负载了.
- 如果你想要低延迟,你需要保持低CPU利用率。在代码不变的情况下,高CPU利用率意味着高延迟。(想到了之前公司领导提出的高利用率,低延迟的降本增效项目)
吞吐量和延迟之间的关系
吞吐量和延迟一直是系统调优中永恒不变的话题,那么他们的到关系到底是怎么样的,我们能否像之前一样通过某种公式来描述它?
1. 模型构建
首先我们假定以下条件
- 我们只有一个服务器
- 服务器一次只处理一个请求
- 请求的到来服从泊松分布
- 请求的处理时间服从泊松分布
- 每个请求的处理时间保持一样
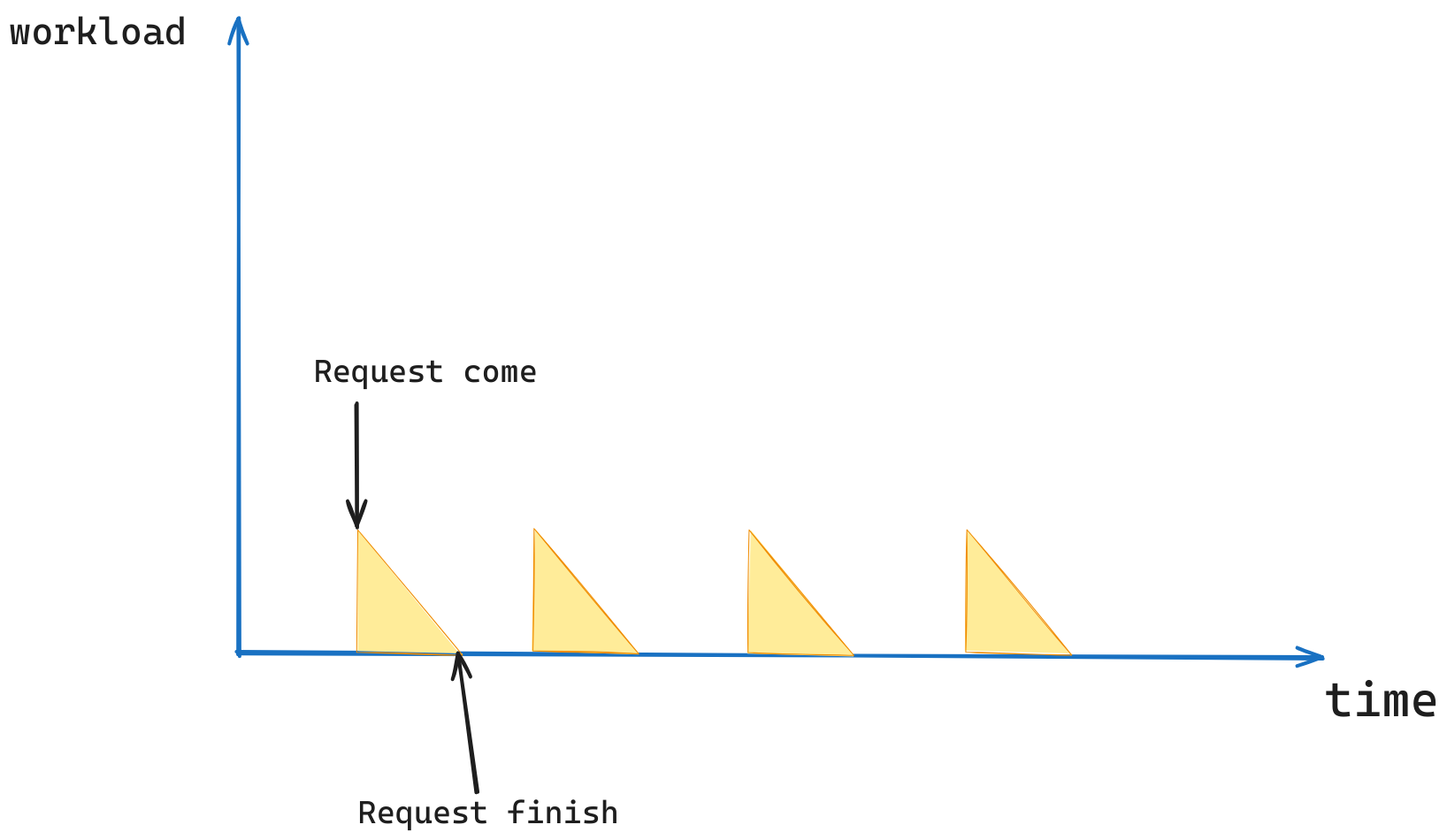
根据以上的假设,我们可以用以下的图片来表明该模型,横轴表明时间,纵轴表明待处理的工作量。
我们可以用下面的图来表明更一般的情况,即有可能一个请求还没处理完,下一个请求就来了。
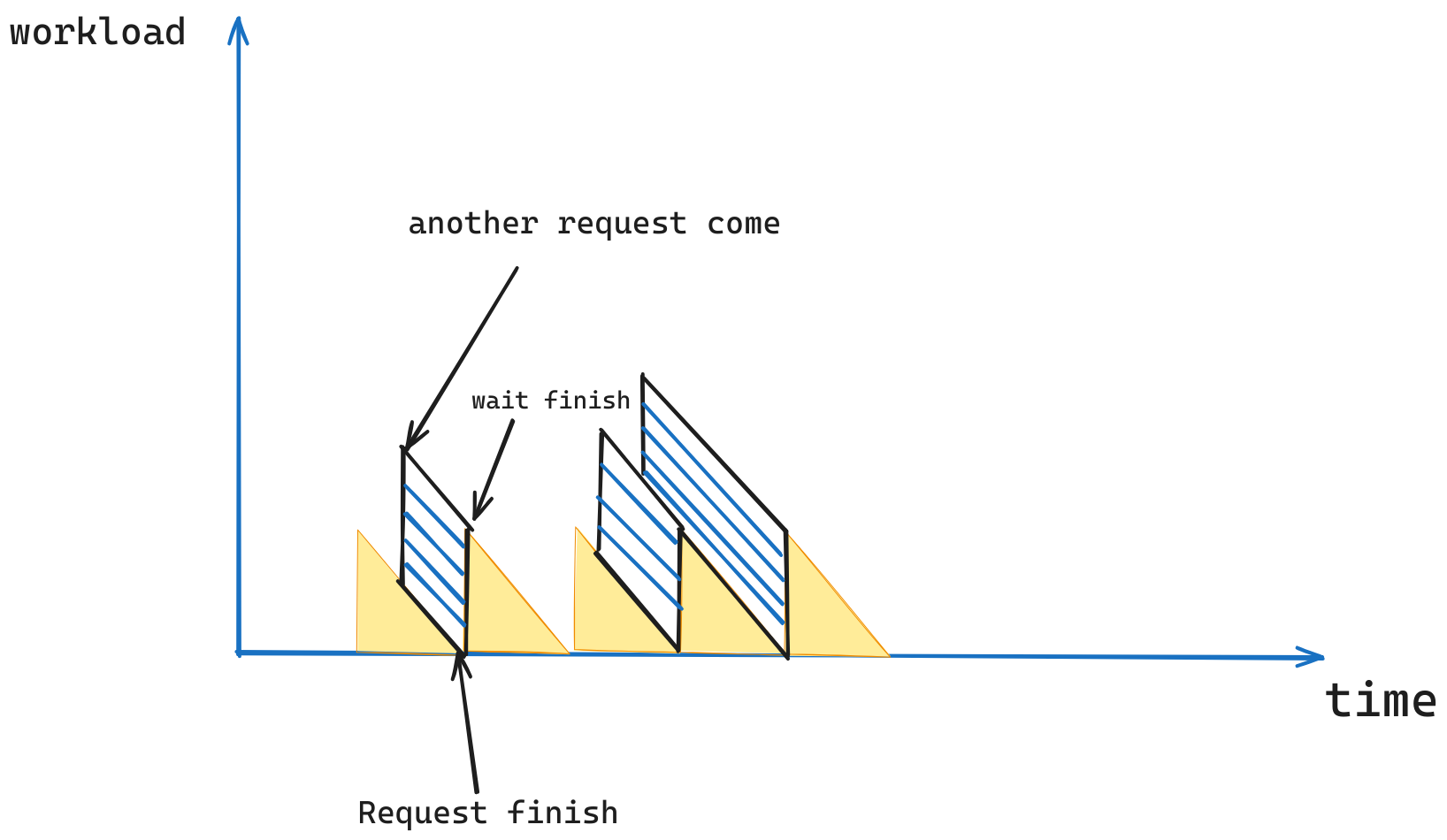
现在我们可以尝试计算这个图形的面积,我们有两种方式计算这个图像的面积
第一种方式
其中:
为时间的长度
为请求的平均等待时间
第二种方式
其中:
为时间的长度
为单位时间内可以处理的请求数,即吞吐量
为每个请求的处理时间
为请求的平均等待时间
我们将上面两个公式进行求解
可以得到
如果我们固定S(每个请求的处理时间), 我们可以获得以下W与 的函数图像,即延迟和吞吐量的关系。
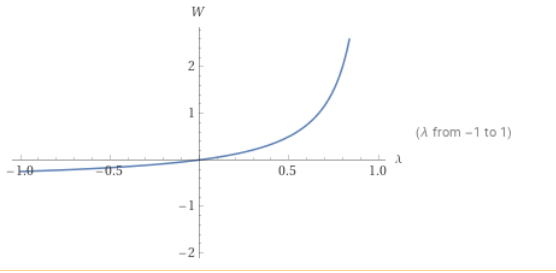
从该公式我们可以得到以下结论
- 延迟与高吞吐成正比,也就是说低延迟和高吞吐是不可能同时存在的。
- 我们也获得了一个符合直觉的情况,如果要高吞吐你需要高CPU利用率,如果你需要低延迟你需要低CPU利用率。
- 如果你可以将处理请求的时间缩短一半,你可以在吞吐量增长一倍的情况下依旧保持之前一般的延迟。
结论
- 为什么有时候CPU利用率到达了50%就需要扩容? 因为延迟的增长和CPU的利用率并不是线性增长.
- 如果CPU利用率到达了80%,就需要高度重视服务的负载了.
- 如果你想要低延迟,你需要保持低CPU利用率。在代码不变的情况下,高CPU利用率意味着高延迟。
- 延迟与高吞吐成正比,也就是说低延迟和高吞吐是不可能同时存在的。
- 我们也获得了一个符合直觉的情况,如果要高吞吐你需要高CPU利用率,如果你需要低延迟你需要低CPU利用率。
- 如果你可以将处理请求的时间缩短一半,你可以在吞吐量增长一倍的情况下依旧保持之前一般的延迟。