[译] Binary quantization
什么是 binary quantization?
目前的向量数据库会构建大规模的向量索引,并将向量索引放在内存中进行搜索。这样可以实现实时查询,但相应的成本也相应增加。Binary quantization(BQ) 是一种向量压缩算法,可以在内存占用和查询准确性之间做出权衡。
我们可以通过类比的方式来了解这一技术。假设每个要存储的向量都像是一个家庭地址。这个地址可以精确地定位某人的居住位置,包括国家、州、城市、街道号甚至门牌号。但为了获得这种精确性,需要占用大量内存来存储、搜索和读取每个地址(详细的地址占用的内存更多)。同样地,在多维空间中定位一个向量,可以将向量中每个维度的数字视为沿该维度指定的方向移动的距离。
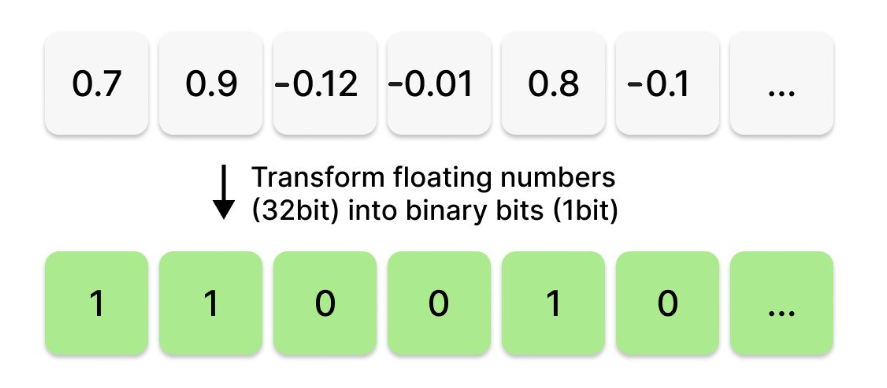
Binary quantization(BQ) 的压缩过程是根据每个数字的符号将向量中的每一维转换为0(负数)或1(正数)。这听起来似乎有些不可思议,因为丢失了每个维度上的具体数字,那么如何精确定位该向量呢?尽管BQ听起来似乎不太可靠,但在高维度矢量上却能取得不错的效果。接下来让我们来看看原因!
二值化不仅适用于向量的压缩,我们还可以从其他领域理解其用途,比如在计算机视觉中。如果对一幅图像进行二值化,即对每个像素,如果大于某个阈值,则替换为1;否则,替换为0。这样生成的图像是黑白二进制图像。虽然会丢失图像细节,但显著地压缩了图像大小。


现在,让我们考虑一下将一个句子向量embedding进行二值化后会呈现怎样的形式。在下面的图示中,我们将句子:“All your vector embeddings belong to you!”转化为一个384维的向量。第一张图展示了向量的所有384个数字,每个数字都是一个32位的浮点数,在热力图上用颜色渐变的方式显示。每个向量维度上的数字决定了热力图上颜色渐变的程度。下面的图展示了相同的向量,但我们对向量进行了阈值处理,使得所有正值维度转换为1(白色),而负值维度转换为0(黑色)。因此,我们得到了一个黑白相间的热力图,看起来有点像条形码。这就是对向量进行Binary quantization(BQ)的效果!得到的向量大小要小得多,但也丢失了很多细节。
Binary quantization(BQ)通过仅保留向量的方向来简化向量的编码。每个向量维度都用一个比特位编码,表示它是正还是负。例如,像 [12, 1, -100, 0.003, -0.001, 128, -1000, 0.0001] 这样的向量将被压缩为单个字节,结果是二进制序列[1,1,0,1,0,1,0,1]。通过将每个维度存储的数字从float32转换为1-bit,将每个向量占用的空间减少了32倍。然而,我们无法从BQ后的向量还原出原始向量——这使得这成为一种有损压缩技术。
使用二值化向量的细节
二值化向量的距离计算
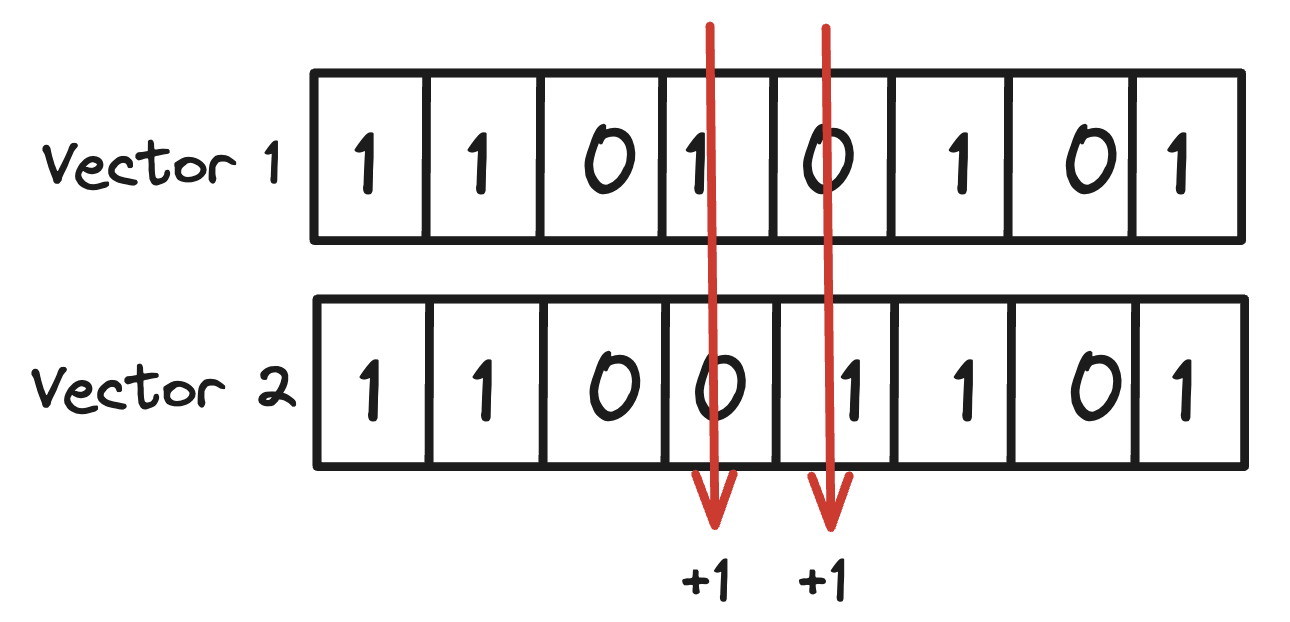
首先,我们考虑如何计算两个二值化向量之间的距离。计算方法很简单:因为我们仅关注它们的方向性,我们只需要评估它们每个维度的bit是否一致。即计算两个向量不同比特位的数量。在这里,因为可以利用位操作,会比计算非二值化向量之间的距离要快得多。
例如,将向量[12, 1, -100, 0.03, -0.01, 128, -100, 0.01]压缩为11010101,以及将第二个向量[11, 4, -99, -0.01, 0.02, 130, -150, 0.02]压缩为11001101,它们之间的距离由不同比特位的数量决定 (距离为2)。这实际上也就是两个向量之间的汉明距离。
BQ下数据分布的重要性
与我们介绍的product quantization不同,BQ并不适用于所有类型的数据——我们会在后面解释原因。然而,如果我们正在处理归一化的数据,特别是在利用余弦度量距离时,无需担心,因为Weaviate会为您无缝处理数据归一化。现在,让我们讨论增加维数的影响。
一维向量的BQ
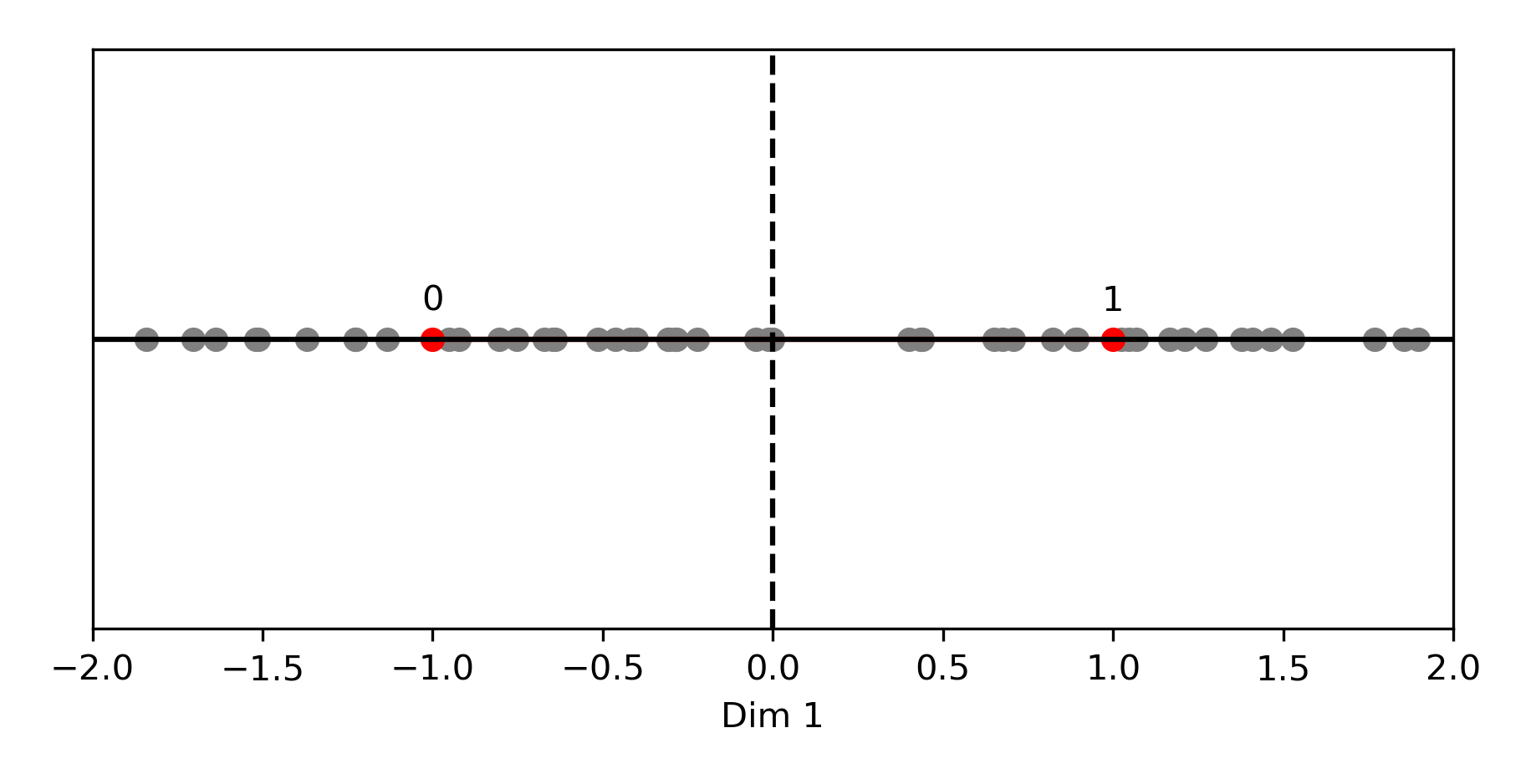
在下面的图片中,我们绘制了一个归一化后,在一维空间中唯一可能的两个点(0, 1),用红色表示。量化器会分配给正向向量 1,分配给负向向量 0。
让我们扩大我们的视角,涵盖两个维度。因为我们考虑的是归一化后的向量,我们预期所有向量都位于以(0,0)为中心,半径为1的圆内。我们的重点是理解量化器如何将数据分成四个不同的区域,利用两个可能的bit值和两个维度来实现二次幂的效果。
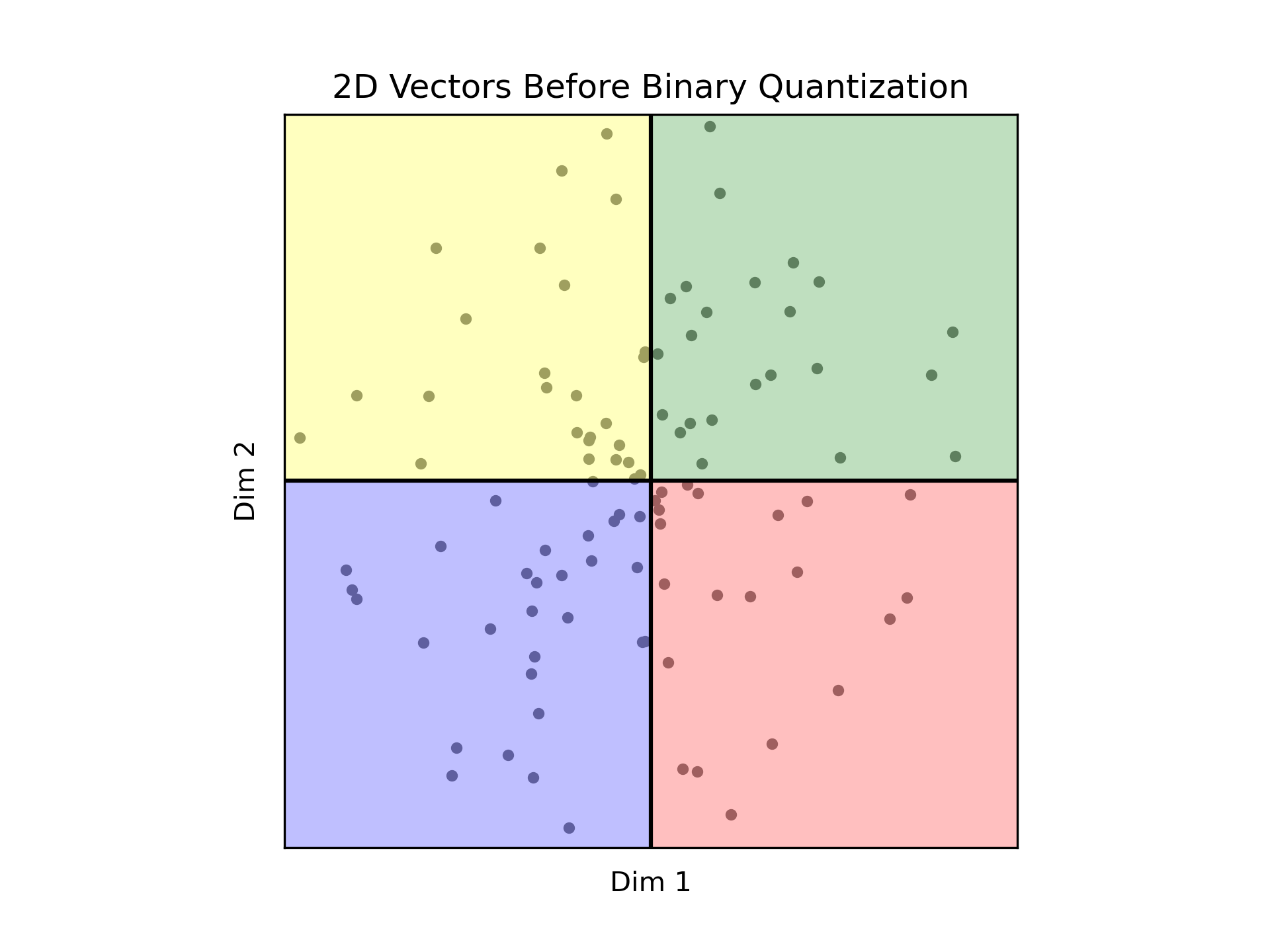
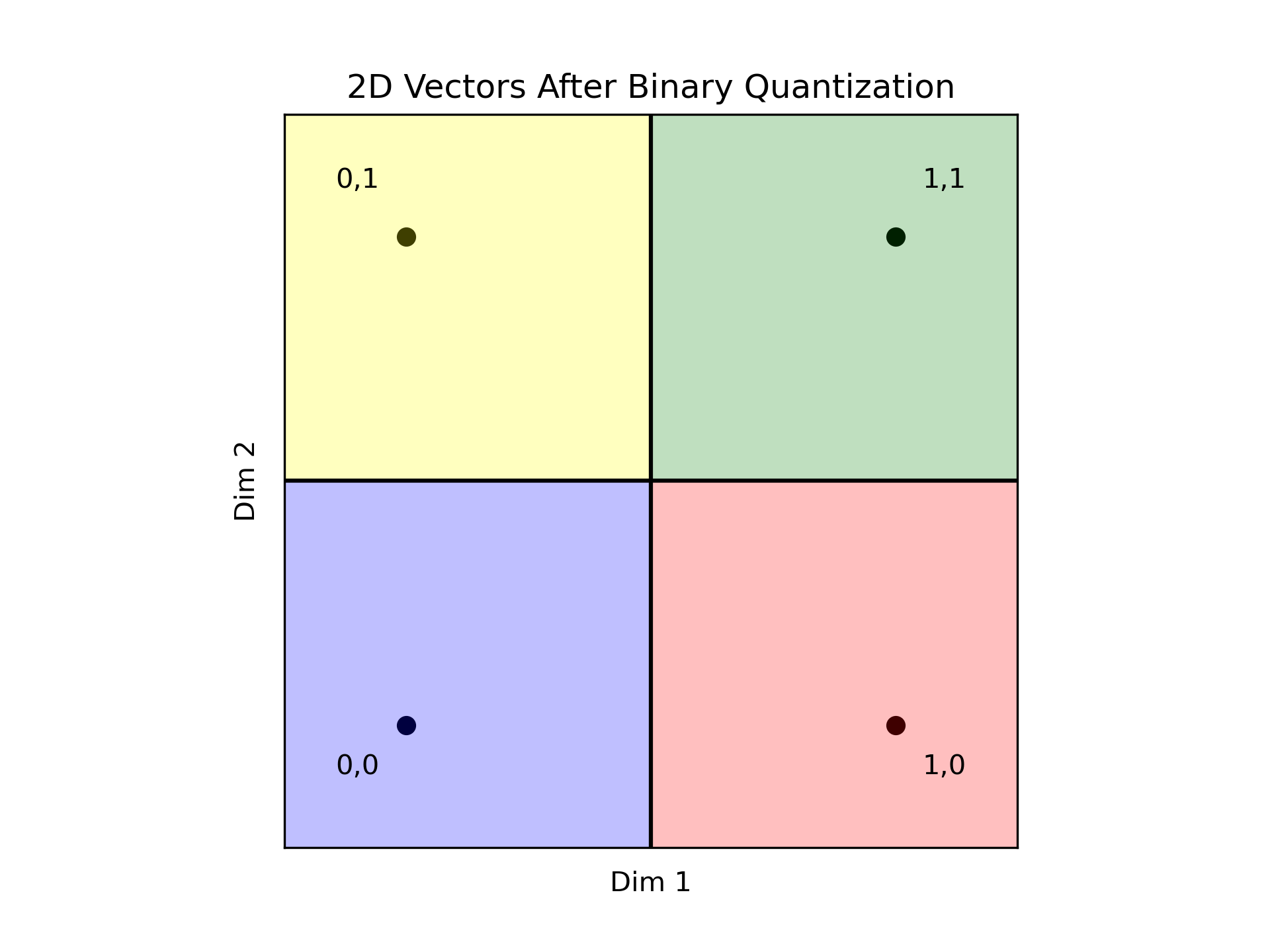
在这种情况下,绿色区域(编码11)包含了两个维度都为正的点,而蓝色区域(编码为00)则包含了两个维度都为负的点。红色区域(编码为10)表示第一个维度为正,第二个维度为负的情况,而黄色区域(编码为01)表示第一个维度为负,第二个维度为正的情况。
重要的是,在每个区域内,任何点与同一区域内的任何其他点之间的距离都是零。而相邻区域中的点之间的距离为1。和完全相反的区域中的点,距离延伸到2。
这种区分强调了数据分布的关键作用。虽然我们使用的是归一化数据,但是归一化并不是强制性的,但归一化后的数据与所描述的情景非常一致。那么让我们分析另一种情况。
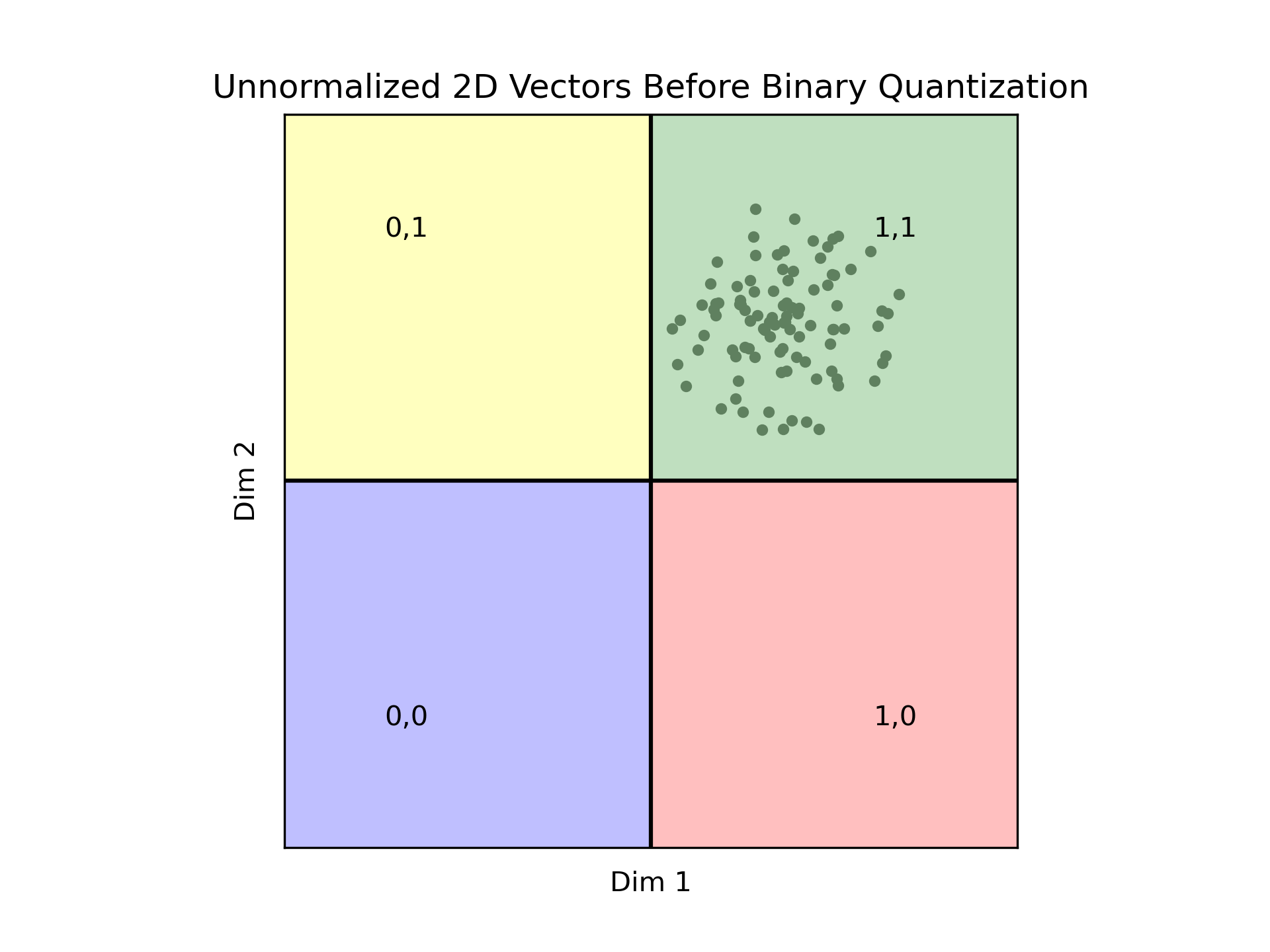
我们所有的数据都落在第一象限中。因此,所有向量都被编码为11,这使得所有向量之间难以区分。这种情况说明了一个不好的数据分布可以使Binary quantization无法使用。正如先前所述,虽然归一化不是强制性的,但选择归一化的数据在数据分布方面提供了一定程度的保证,有助于使用Binary quantization。
然而,如果你的数据没有归一化,确保区域的平衡和逻辑划分就变得至关重要。考虑以下例子。
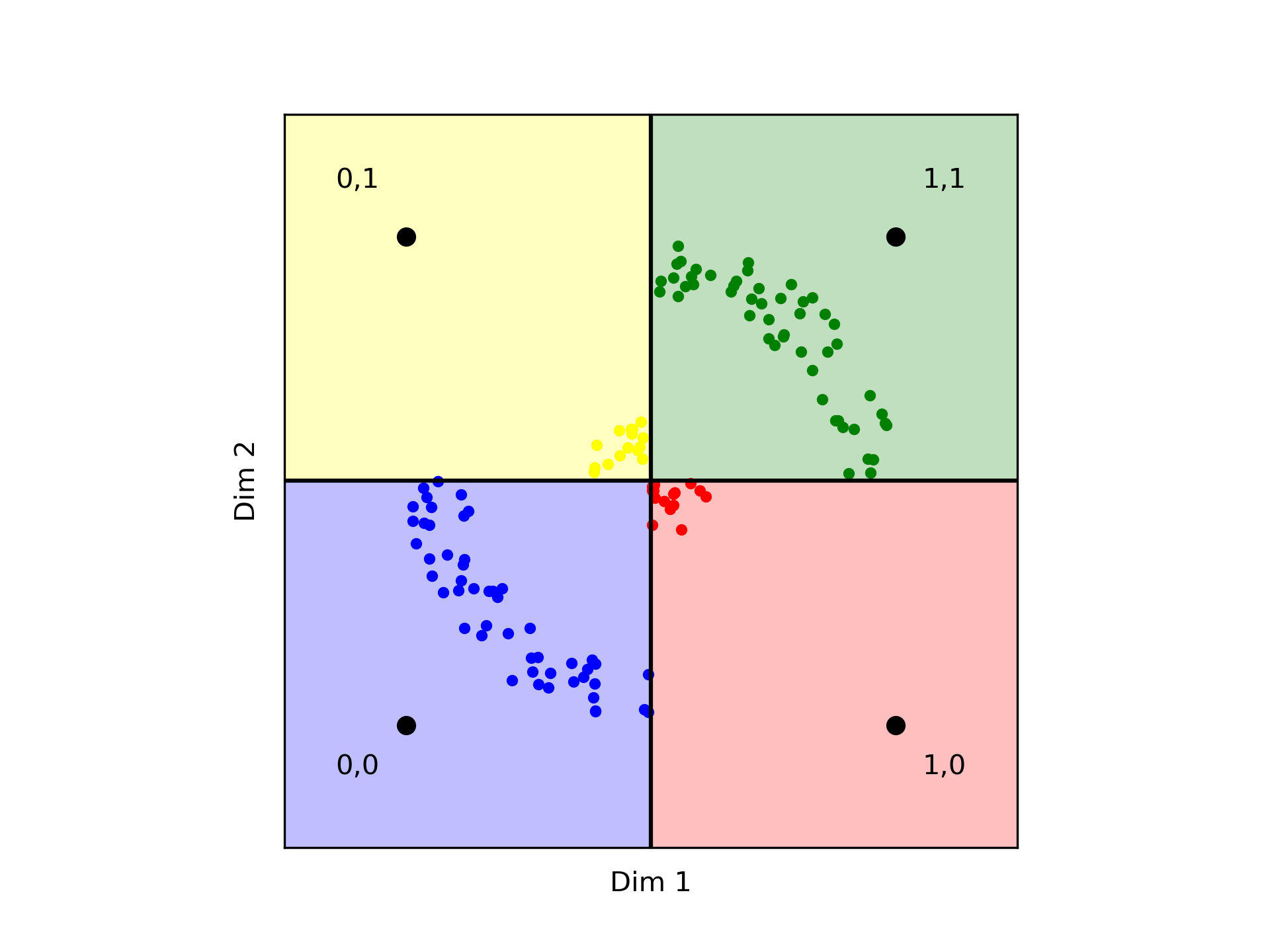
在这种情况下,使用Binary quantization会表明黄色点距离红色点更远,而与蓝色和绿色点更接近。虽然在基于角度的度量(如余弦)中这是成立的,但它与在L2度量下的距离相矛盾,我们可以看到黄色和红色点实际上更接近。
N维向量的BQ
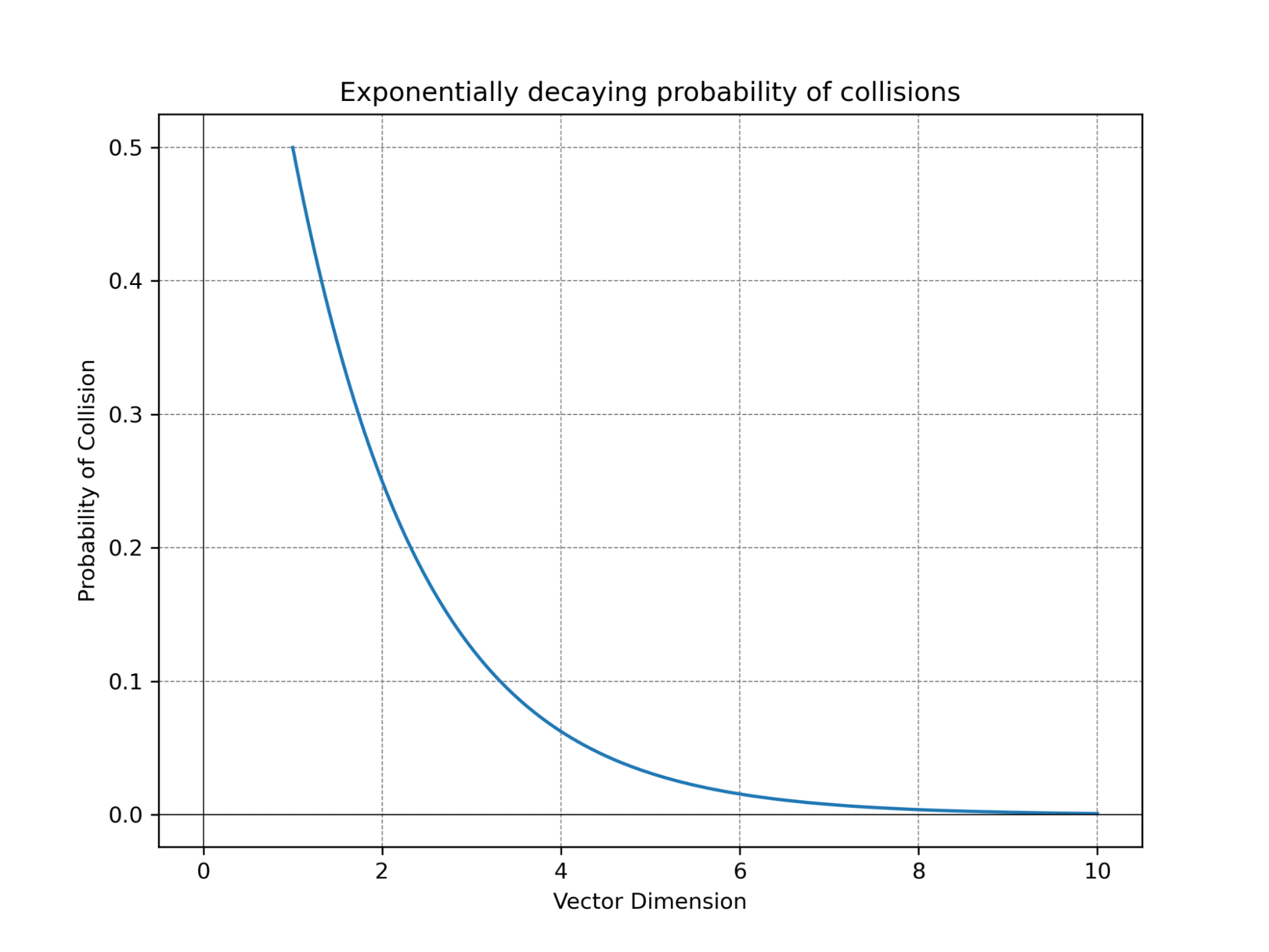
让我们考虑数据量以及在应用Binary quantization后能够唯一表示向量的能力。在得知了维数和数据量后,我们对碰撞的程度可以有一个预期,我们将两个向量之间的碰撞定义为两个不同的向量进行Binary quantization后具有相同的表示。如前面的例子所示,在对二维向量进行二Binary quantization时,我们只能构建四个区域。因此,当向量数超过四个时,就会发生碰撞,使得两个不同的向量无法区分。
然而,好在随着维度的增加,可划分的区域数量呈指数增长。对于每一个维度的增长,区域数量翻倍,提供了更强大的向量表示能力。例如,当维度数为时,你已经有令人惊讶的个区域可供使用——即使你有数十亿或数万亿个向量,向量之间的碰撞也几乎不可能发生。而当维度数来到了,区域的数量可以轻松容纳任何数量的向量,而不会发生任何碰撞。
BQ的性能提升
让我们重新审视一下Binary quantization的优势。通常,我们使用量化的方法来节省内存,将每个数字编码为1-bit。在Weaviate中,浮点向量被表示为float32数组,从而产生了1:32的压缩比,这已经值得令人称赞了。
然而,Binary quantization还有一个显著的次要好处:现在,位操作可以被用来计算量化后的向量之间的距离计算。仅需要对两个二进制数组之间进行简单的异或(XOR)操作,统计结果中的1的数量。而Go语言提供了针对这些二进制函数进行SIMD优化的操作,从而计算速度比使用原始向量快得多。但确切地说快多少呢?
为了回答这个问题,我们展示了使用我们的Binary quantization和原始向量进行的暴力搜索结果。我们对维度范围从768、1536到4608的10,000个向量进行100次查询搜索
| 维数 | 原始向量延迟 (microseconds) | 压缩后向量延迟 (microseconds) | Recall |
|---|---|---|---|
| 768d | 1771.85 | 230.72 (13%) | 0.745 |
| 1536d | 3703.68 | 353.3 (9%) | 0.744 |
| 4608d | 16724.41 | 896.37 (5%) | 0.757 |
虽然召回率并不是很高,但我们可以通过超额获取候选邻居并重新评分来解决这个问题。值得注意的是,随着向量维度的增加,我们可以观察到更显著的加速。例如,当暴力搜索768维的压缩向量时,与使用未压缩向量相比,我们只需花费13%的时间。同样地,对于1536维的压缩向量,我们只需花费9%的时间,而对于4608维的压缩向量,只需花费未压缩向量时间的5%。
一般而言,我们依靠构建图来进行ANN搜索,因为一个个搜索数百万个向量是不切实际的。然而,由于时间显著减少,暴力搜索数据现在成为了一种可行的选择。例如,在768维的情况下,暴力搜索100万个向量只需花费23毫秒。即使在最坏的情况下(4608维),现在也是切实可行的,大约需要90毫秒。
那么,最终结论是什么呢?Weaviate能够为您的数据提供闪电般快速的暴力搜索吗?答案取决于您的数据大小和搜索速度的期望。
暴力搜索有几个优点。首先,你可以不需要索引,节省构建索引所需的时间。虽然在Weaviate中建立索引并不是特别缓慢,但暴力搜索允许您完全跳过此步骤。其次,你不再需要存储邻接点,从而进一步节省内存。事实上,如果你选择直接从磁盘上暴力搜索数据,内存使用量将会变得微不足道——仅仅100MB就足以托管您的应用程序。
最近,Weaviate引入了Flat Index,提供了从磁盘暴力搜索数据的选项(默认行为),或者只保留内存中的压缩数据,并从磁盘获取一小部分完整向量进行最终排序。与传统的HNSW索引相比,这两种方法都加快了数据加载速度,同时减少了内存消耗。然而,如果您的需求要求高性能,HNSW仍然是首选。尽管如此,Flat Index提供了一种经济高效、高性能的替代方案。此外,Weaviate现在支持二进制量化(BQ),可用于和HNSW索引。
索引时间的提升
现在,让我们讨论一些性能指标。所有实验均使用Go benchmark进行。在博客的最后,我们将提供有关如何使用自己的数据复现这些实验。首先,我们将使用来自DBPedia的一个中等规模的数据集,使用ADA002(1536维)和Cohere v2(4096维)的embedding向量,首先从索引时间开始。
| Dimensions | 1536 | 4096 |
|---|---|---|
| Flat index | 5s | 7s |
| Hnsw index | 47s | 1m36s |
| Hnsw index+BQ | 21s | 25s |
正如前所述,Flat Index没有数据索引的需要。因此,我们只需将数据发送给服务器并将其存储起来即可。相反,HNSW需要构建索引。值得注意的是,就索引时间而言,HNSW索引也可以从这种压缩中获得明显的的性能提升。
内存占用的提升
现在,让我们讨论内存占用。我们将区分Flat Index的不同配置项,因为它们具有不同的内存占用。当使用Flat Index时,无论数据大小如何,无论是否使用BQ, 所有数据都从磁盘中检索。如果我们选择缓存压缩数据,它将存储在内存中。由于不需要索引,Flat Index的内存占用低于HNSW+BQ的内存占用。此外,我们将展示HNSW不同情况下的内存占用。在这两种情况下,您可以预期内存占用量随维数和向量数量的增加而呈更多或更少线性增长。
| Dimensions | 1536 | 4096 |
|---|---|---|
| Flat index | 77MB | 77MB |
| Flat index + BQ + Cache | 141MB | 183MB |
| Hnsw index | 1.02GB | 1.79GB |
| Hnsw index+BQ | 214MB | 297MB |
延迟分析
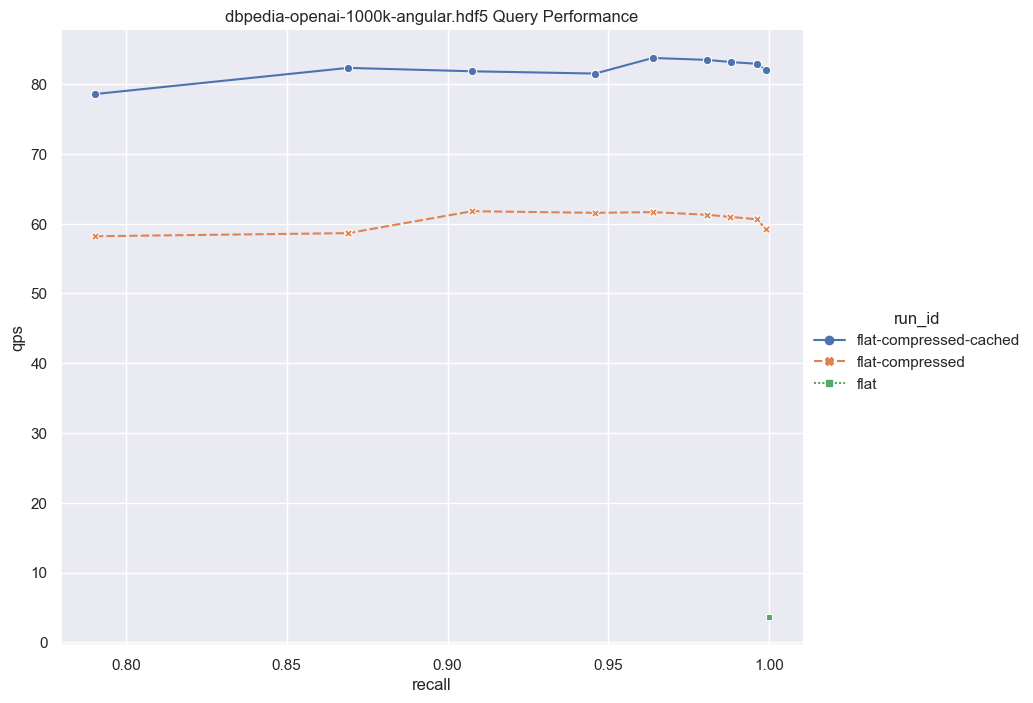
最后,让我们来看一下QPS与召回率曲线,以了解不同方案之间的性能。为了生成这样的曲线,我们修改了HNSW下的ef参数,以及Flat Index下的rescoringLimit参数。我们还使用了10个并发核心来测量QPS。
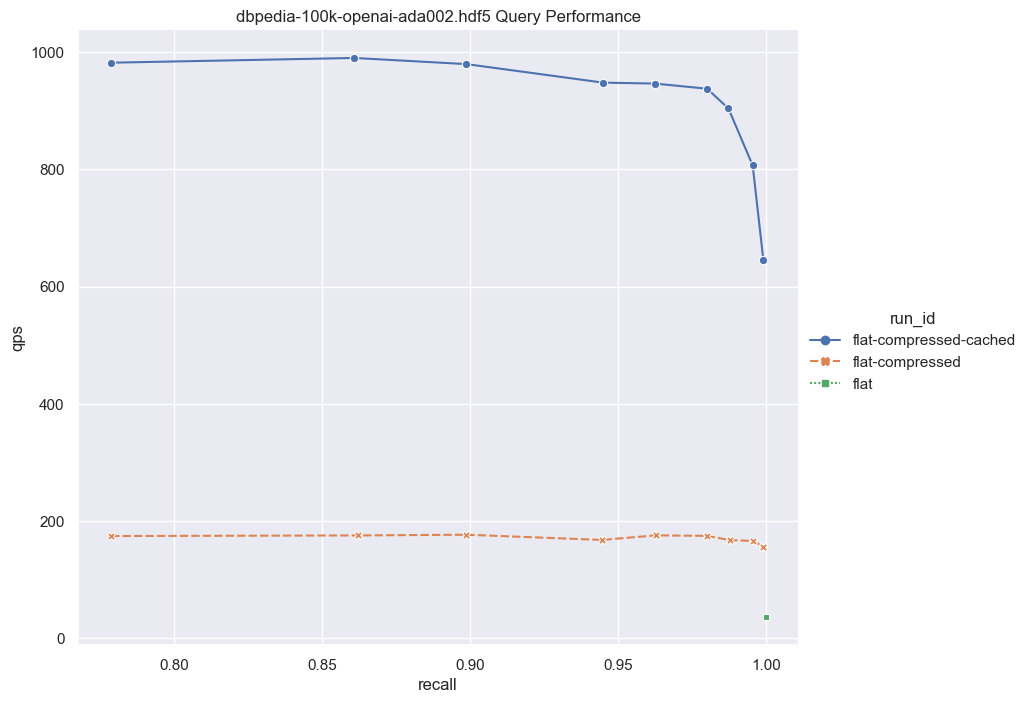
请注意,纯Flat Index场景中的QPS较低(显示为右下角的绿点)。是因为这种情境下,我们需要在磁盘中检索所有完整的向量,并在未压缩的向量上执行暴力搜索。虽然这种方法性能较差,但它不需要内存分配。
接下来,我们采用相同的方式,但集成了Binary quantization(BQ)。在这个情景中,我们需要从磁盘中读取的数据较少,因为我们仅需要访问压缩后的向量(比未压缩相比小32倍)。此外,由于我们仅需要用位操作计算距离,因此暴力搜索也变得更快。暴力搜索后,我们会生成一个候选列表,然后对它们进行重新评分。在重新评分过程中,我们只需要检索少量完整向量来构建最终结果。这个方式仍然保持了磁盘操作,同时提供了更好的性能。需要注意的是,这种方法取决于BQ的兼容性;否则,可能无法实现最佳的召回率。此外,确保足够高的rescoringLimit对于保证良好的召回率至关重要。
最后,我们测试了具有缓存的压缩向量的平坦索引(用蓝色曲线表示)。这种方式QPS在600到1000之间。当然在这种情况下,内存占用量略微增加,因为压缩后的向量被保留在内存中,只有一小部分向量从磁盘中获取。
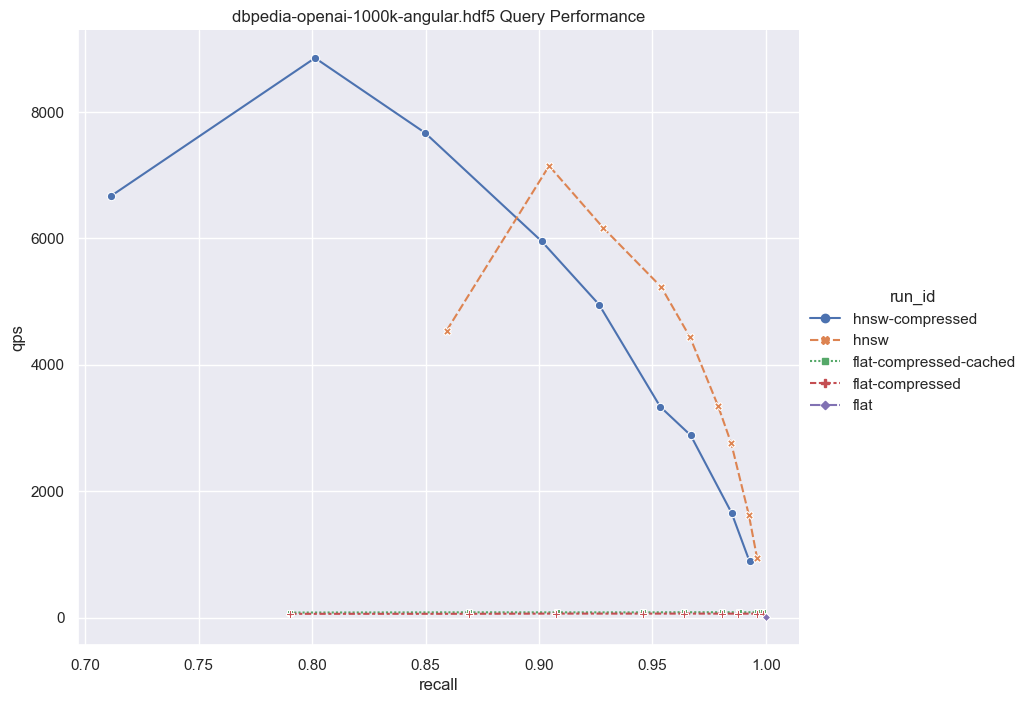
接下来,我们将考虑较大维度的情况。
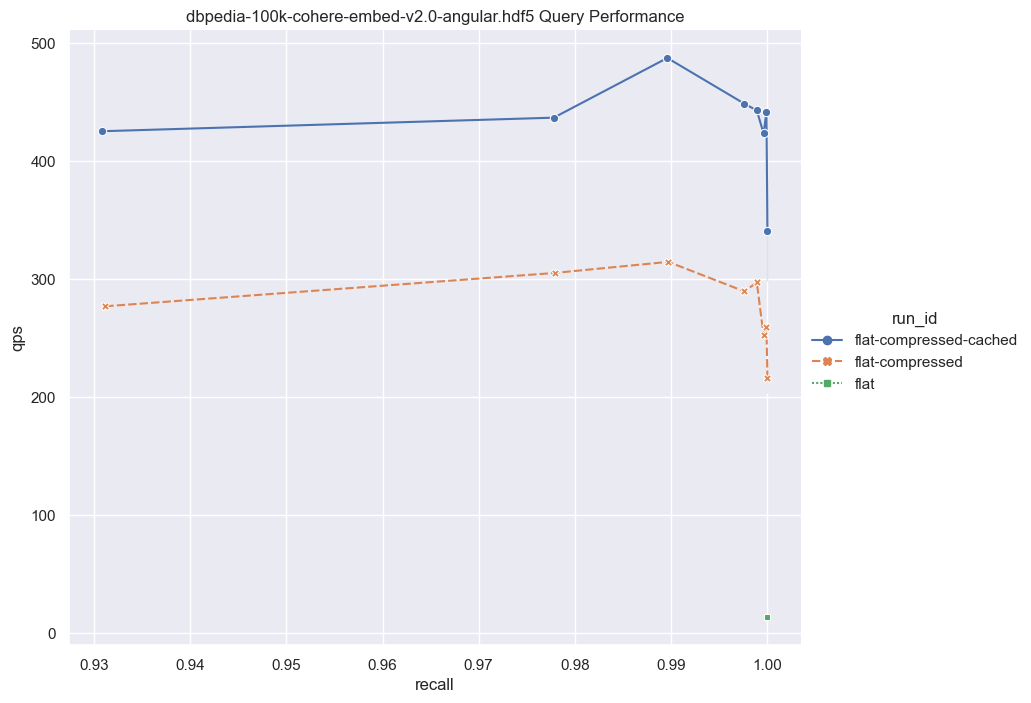
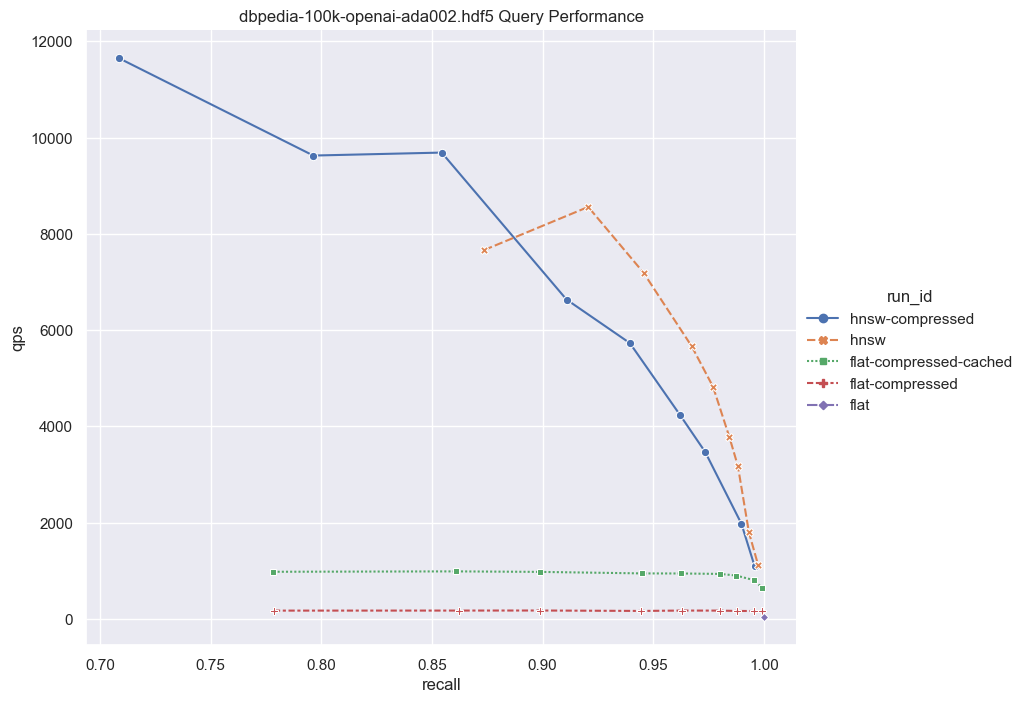
鉴于这些结果,值得考虑以下几点:对于一个相对较小的向量数据集(100,000),如果你的目标是非常高的召回率,那么 flat-compressed-cached曲线与HNSW之间的性能差异并不十分明显。有人可能会认为100,000个向量并不是一个很大的数量,这是一个正确的观点。然而,让我们考虑将此功能与多租户结合。
Weaviate确保了每个租户的信息完全隔离。如果我们有1000个租户,每个租户都有100,000个向量。令人惊讶的是,预期的性能保持了差不多的一致性。而这1亿个向量则构成了大量的数据。此外,Weaviate支持租户快速停用/惰性重新激活,这可以创建出一个性能异常出色、内存占用极低的性能方案,前提是您已经设计了一个健壮的架构。
现在,让我们将数字进一步放大。对于更大的数据集,暴力搜索与数据大小呈线性关系。如果我们将数据集增加到1,000,000个向量,那么QPS将比这里展示的要慢大约10倍。然而,即使有了这种增加的延迟,对于某些应用程序来说,暴力搜索仍然是一个可行的选项。
PQ与BQ的对比
现在你在Weaviate中有多种量化技术可供选择,那么问题就来了,PQ和BQ哪个更好,应该在哪里使用PQ vs. BQ。这个决定将取决于你具体的数据,并且需要你运行自己的基准测试。我们在下一节提供了代码和说明,以便您进行这样的测试。下面的内存和性能实验旨在让你更容易地做出PQ vs. BQ的选择。
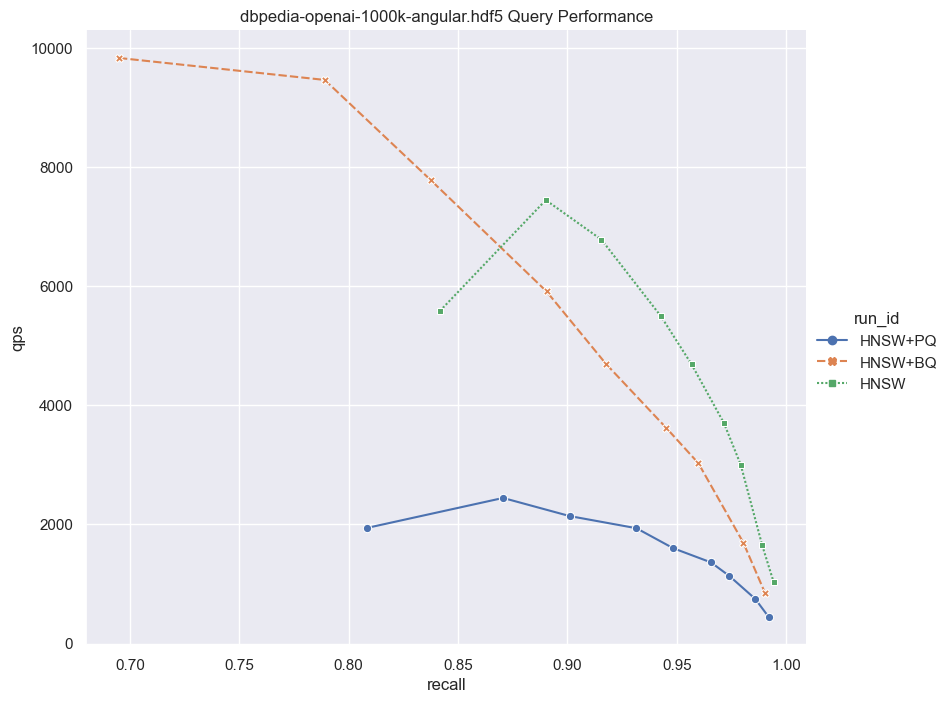
请注意,BQ的主要优势不仅仅是压缩向量。更高效的位计算也起着重要作用。这就是为什么我们上面讨论的flat+bq选项是一个如此好的选择。我们不仅需要从磁盘读取的数据更少,而且更快的距离计算使得在Weaviate中的暴力搜索更快。
| Index | Indexing Time | Memory Usage |
|---|---|---|
| HNSW | 8m42s | 6437.05MB |
| HNSW+PQ | 21m25s | 930.36MB |
| HNSW+BQ | 3m43s | 711.38MB |
| FLAT+BQ | 54s | 260.16MB |
| FLAT+BQ+CACHE | 53s | 352.99MB |
注意BQ是如何极大地缩短了与HNSW的索引时间。
用你自己的数据来测试BQ
在这里,我们提供了代码和说明,这将帮助你在你自己的数据上自行复现上述实验来找到召回率、延迟和内存占用量,最佳的平衡。
我们在这个仓库中包含了一些非常有用的工具。要轻松运行这些测试(或者使用你的数据运行任何测试),你需要将数据以hdf5格式存储,并且具有与ANN基准测试中描述的相同格式。您可以使用Go基准测试工具对数据进行索引。这个基准测试工具可以给您一个更好的QPS概念,同时使用并发查询。它接受几个参数,您可以探索,但在我们的运行中,我们使用以下命令:
go run main.go ann-benchmark -v ~/Documents/datasets/dbpedia-100k-openai-ada002.hdf5 -d cosine --indexType flat注意参数-d用于距离和—indexType用于在hnsw和flat之间切换。
要运行压缩(启用BQ):
go run main.go ann-benchmark -v ~/Documents/datasets/dbpedia-100k-openai-ada002.hdf5 -d cosine --indexType flat --bq enabled注意参数-bq用于激活压缩。
一旦您运行脚本,您将在运行结束时在终端上看到不同的指标。特别注意QPS和召回率。结果将以JSON格式保存在与脚本相同路径下的名为results的存储库中。接下来,您还可以运行visualize.py脚本,生成我们在本文中显示的相同图形。您的图形将在与脚本相同路径下的output.png中可用。
祝愉快压缩!🚀