PQIVF(Prodcut Quantization)
Product Quantization是一种用于向量量化的方法,由Hervé Jégou和Olivier Chum于2011年在论文《Product quantization for nearest neighbor search》中首次提出。这篇论文解决了在大规模数据集上进行最近邻搜索的问题。相较于其他的ANN搜索算法通过牺牲一定的内存空间来减少搜索空间,PQ通过对向量进行量化压缩,使得所需要的内存空间大幅减小。
What is Product Quantization?
如果想要搞清楚PQ,那么首先得明白 Quantization 的含义,Quantization即量化,这是一个从信号处理领域来的名词,按照Wikipedia的定义
Quantization is the process of constraining an input from a continuous or otherwise large set of values to a discrete set (such as the integers).
量化就是将一个集合映射到另一个离散的集合之中,那么PQ实际上就是将数据集中的每一个向量映射到另一个集合中,比如说整数集合。即
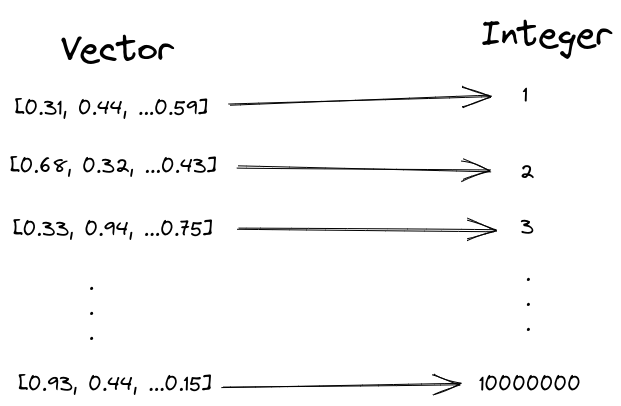
通过这种方式我们可以用一个INT来表示整个向量,也就是说如果向量原来的维数为128.那么单个向量的内存占用就会从128 * 4 byte (float) 降低为 4 byte(int), 内存可以减少128倍。但是量化要求我们的映射为满射,即被映射的集合中任一元素,原始集合中至少存在一个元素与之对应。也就是说如果我们将向量映射到整个LONG空间,我们会有LONG_MAX * 8 byte 即18,446GB的内存占用,这显然是不可接受的。那如果我们仅将向量映射到UINT8,我们会有 256 * 2 byte 即512B的内存占用,内存问题看似解决了。但是如果我们数据集中有100万个向量,我们将其映射到0-255,平均一个整数有3906个向量与其对应,我们在搜索时无法区分这3906个向量与待查询向量之间的距离差别,这就会导致糟糕的召回率。因此选择一个合适的映射空间大小,使得内存占用以及召回率达到一个sweet point,这就是PQ所要达成的效果。
请注意,Product Quantization并不是通过降维来减少空间大小。
在Product Quantization中量化后向量的数量仍然保持不变。但是,压缩后的向量值现在被转换为一个小整数,你可以认为这个整数仅仅只是一个符号。通过将高维向量转化为一个符号,从而减少了向量的内存空间占用。
How Product Quantization Work?
1. Split And Train
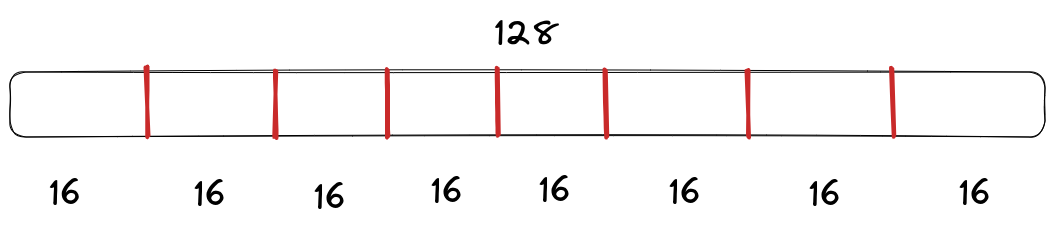
假设向量的维数为128,我们首先将该向量平均分为8份,每一个的维数为16。
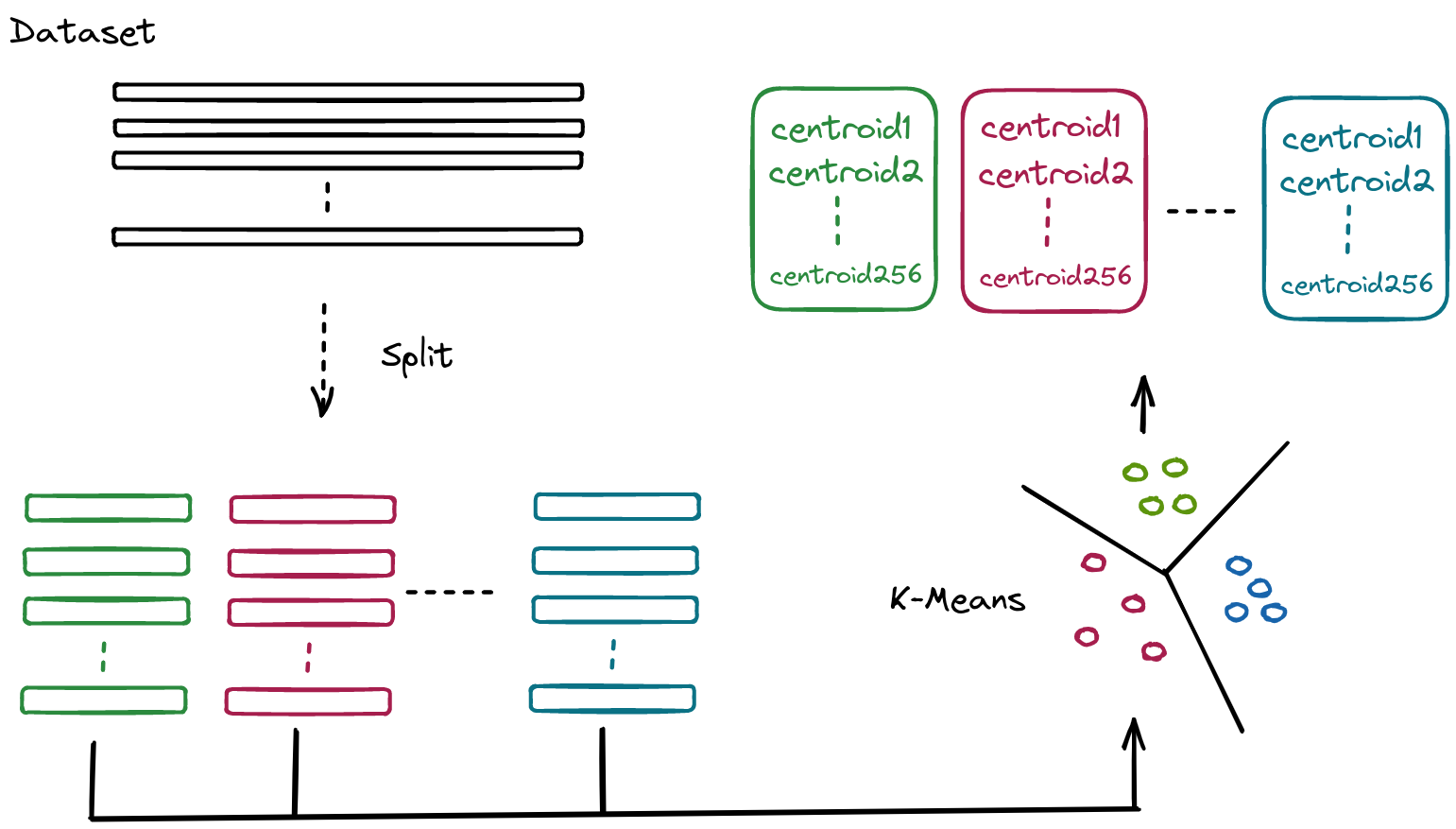
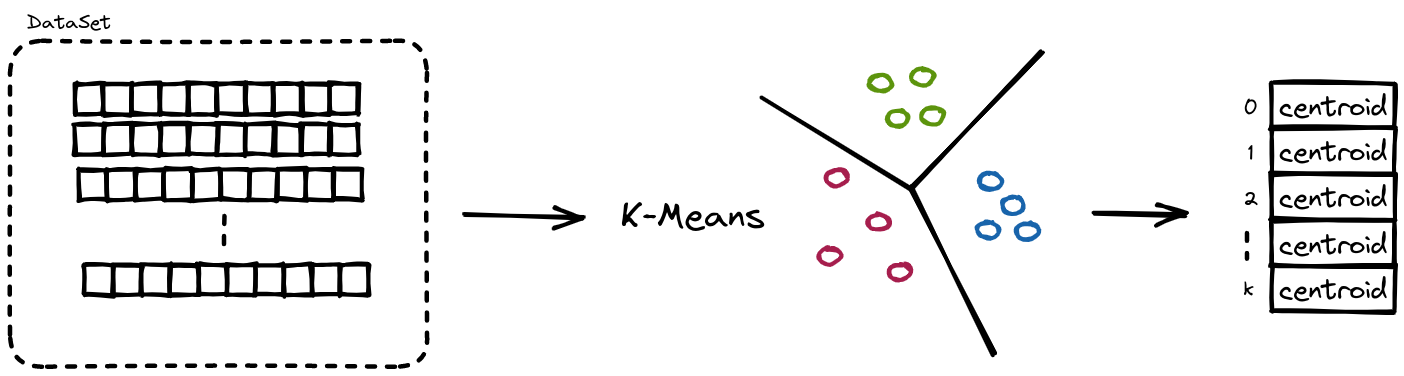
如果我们有1000个向量,我们将每一份向量平均分为8份,V0, V1… V7。那么我们会有1000个V0, 1000个V1,…1000个V7。我们分别对他们进行K-means聚类,同时假定我们选定K-means的K为256。那么我们在每一个Vi中会得到256个centroids。
2. Encode
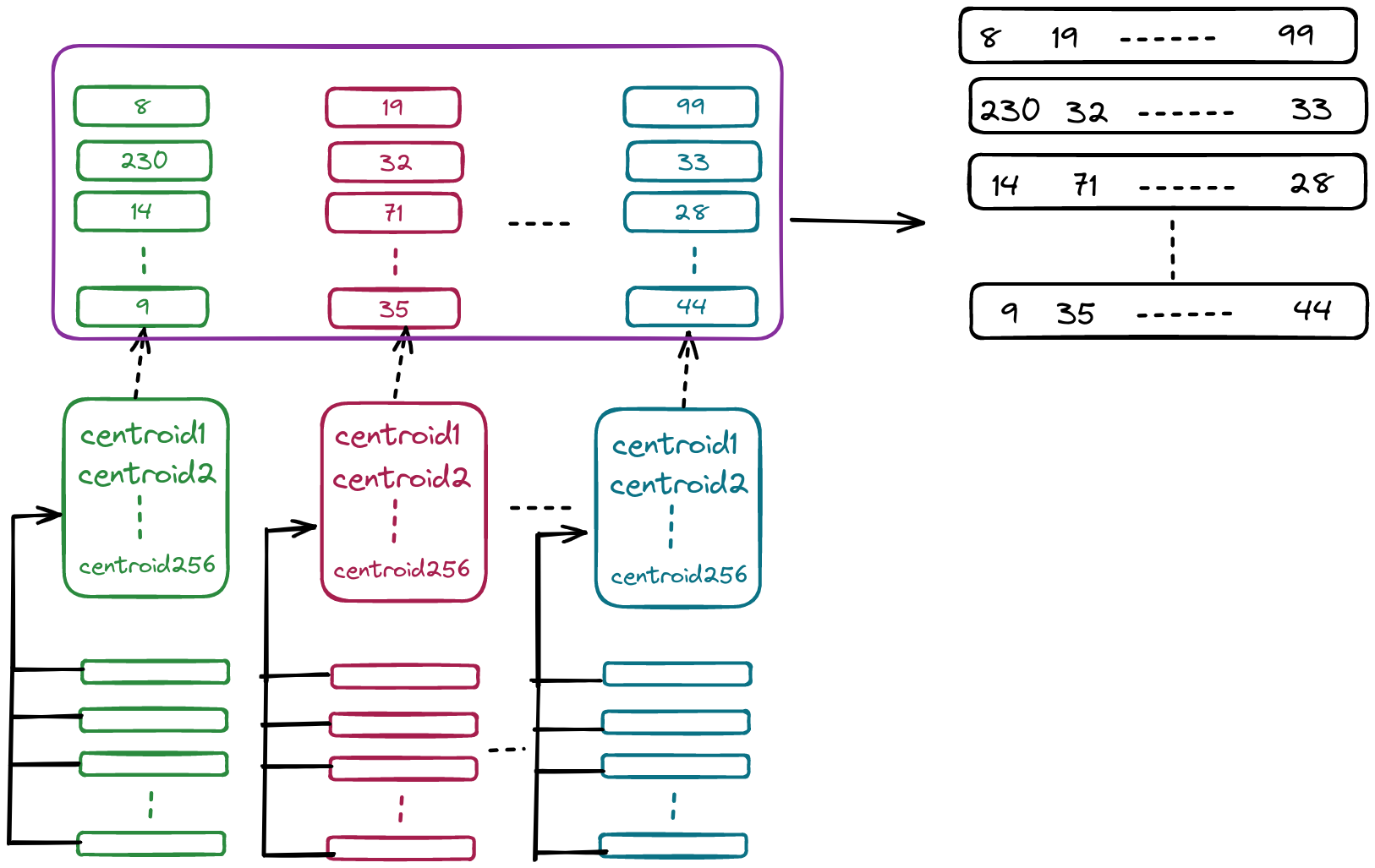
在得到centroids后,我们为每一个向量进行编码,我们首先分别对V0,V1,…V7进行编码,编码的规则相当简单。我们拿V0进行举例,首先我们遍历V0中每一个向量,并且选择距离当前向量最近的一个centroids作为其对应的编码值,如果向量A距离centroids42最近,那么A的编码值即为42。在完成V0,V1…V7的编码值后,我们将其拼接起来就会得到所有向量的编码值。
Summary
目前PQ的构建部分已经讲完了,我们现在重新审视一下PQ这个算法,首先考虑PQ的映射空间大小,尽管我们单个Vi只有256个质心,也就是说无论向量有多少,它们只会映射到0-255,但是我们通过对向量进行split,使得整体的映射空间大小为 (M为向量被split的份数), 从而极大的扩充了映射空间的大小,那我们再考虑内存占用的大小,V0占用的空间大小为 整体的空间大小为, 相比于原始的大小极大的减小了内存占用(D 为向量的维数)。因此PQ在保证了内存占用低的同时提供了一个较大的映射空间,从而保证了召回率。
3. Search
当我们已经对数据库中的所有向量都已经进行了量化,我们需要在用户给定任意向量后,从数据库中寻找与该向量最相似的N个向量,首先我们仍旧对query进行split。

注意我们不会对Query进行量化,仅仅只做Split,原因是这样子可以在距离计算时保证更高的精度,详情可以参考论文原文
在Split后,我们会计算对应的Split部分与每一个centroids的距离,并将该距离进行保存。
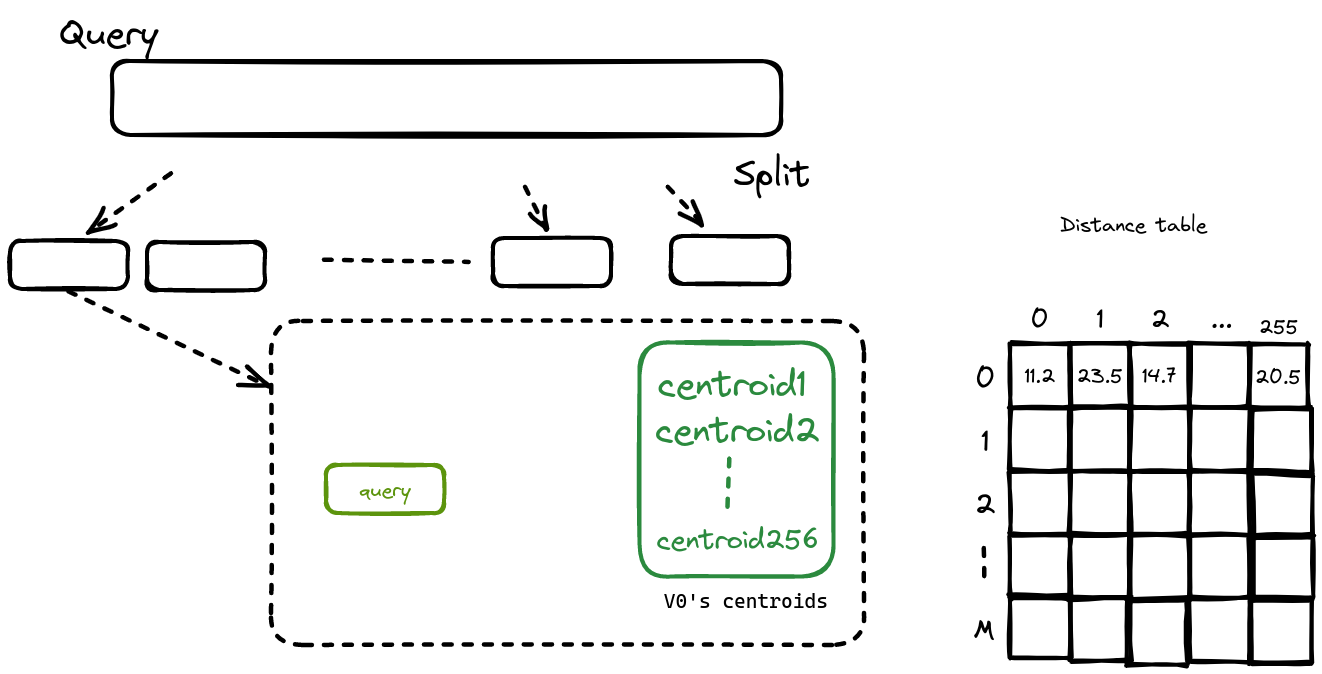
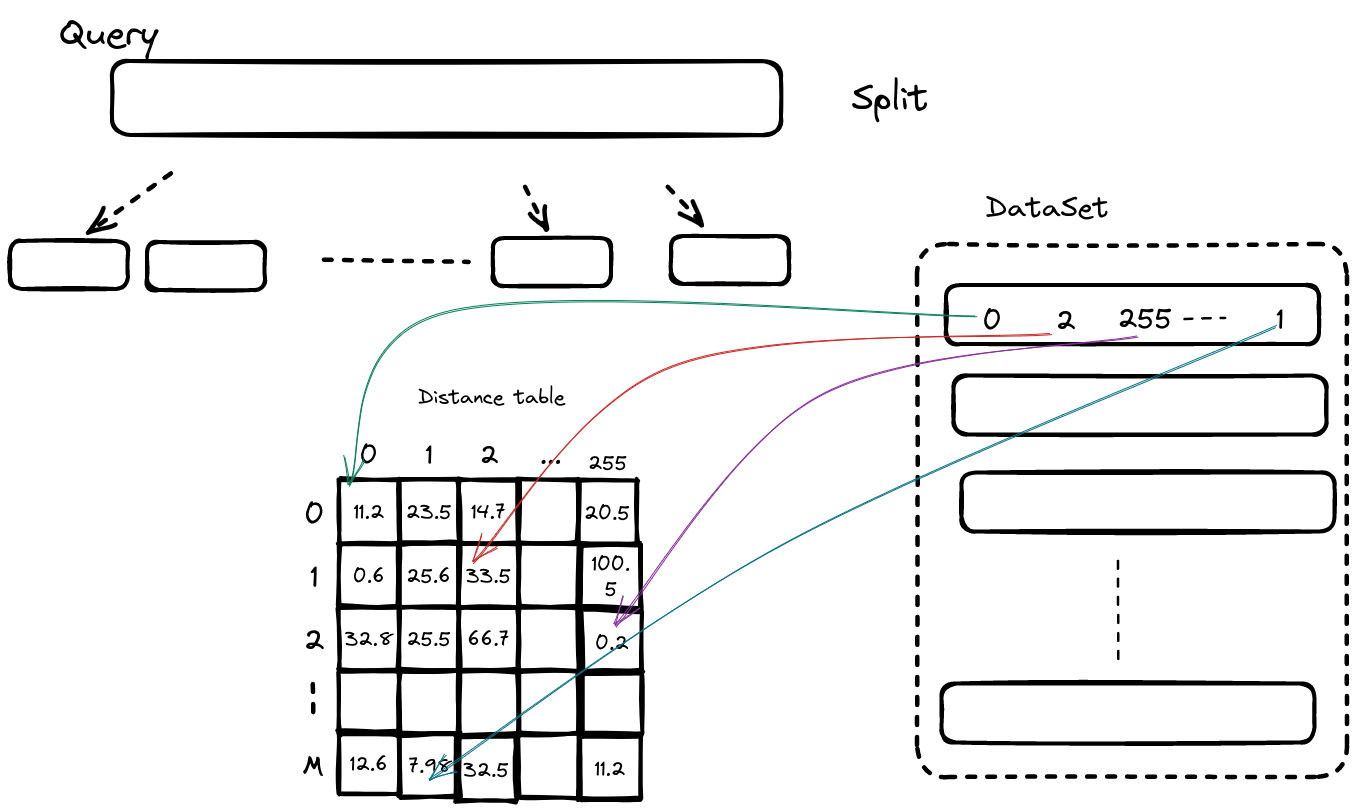
随后我们遍历数据库中所有的向量,通过查表分别计算出Query中每一段与他们之间的距离,随后相加得到最终的距离,并最终选择距离最近的K个向量。
4. IVF
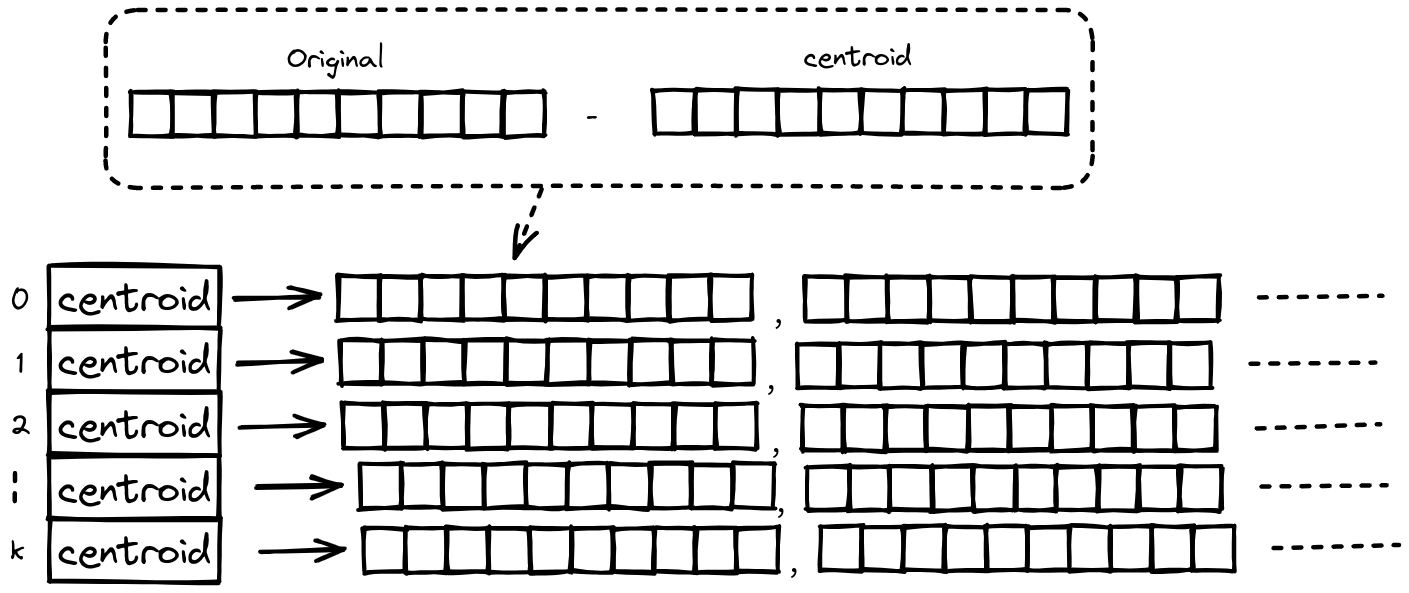
尽管PQ大幅减少了我们所需要的内存,但是在搜索时,我们仍然需要与数据集中的每一个向量计算他们之间的距离,因此我们希望可以在保证召回率的同时,减少计算量。为此我们引入了IVF(Inverted File Index), 首先我们先对数据集中的向量进行k-means聚类,从而将数据集划分为k个小数据集,同时计算数据集中的向量与其对应的质心之间的残差,并对残差进行PQ压缩。
需要注意的是每一个centroid后面都会挂载属于这个分区的向量,但这向量不是数据集中的原始向量,而是原始向量与centroid的残差。之所以选择残差是因为这样可以降低数据集中的方差,从而在进行ANN搜索时,距离计算的误差也会更小,从而产生更好的搜索质量。
可以认为我们实际上是将整个数据集划分为几个更小的数据集后,再对每一个分区进行PQ压缩。当我们搜索时,我们会选择probe个距离最近的分区(通过计算与centroid之间的距离决定),同样的计算Query与对应centroid的残差,并使用这个残差在该分区进行PQ搜索,在完成所有分区的搜索后,返回距离最近的K个向量。
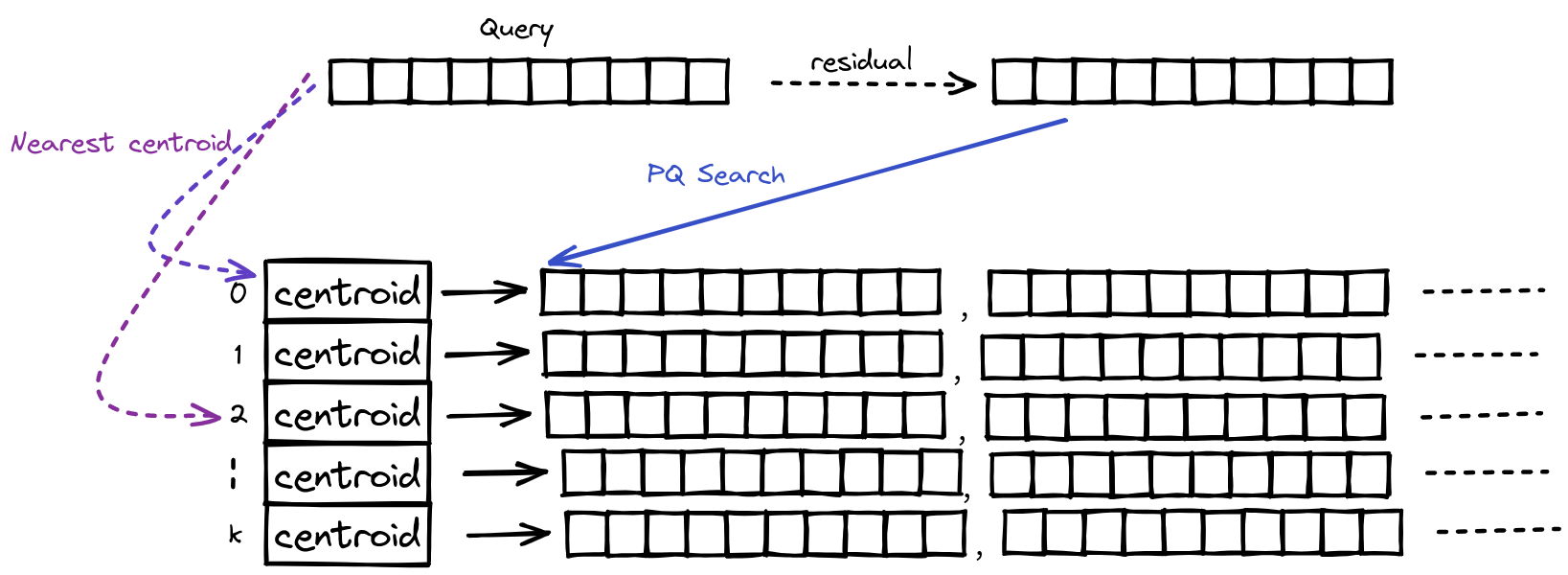
这里之所以选择probe个距离最近的分区而不是选择最近的那一个分区,是因为作者在论文中提到
The query vector and its nearest neighbors are often not quantized to the same partition centroid, but to nearby ones
因此为了召回率我们会扩大一部分的搜索范围,因此probe的数量也体现了召回率与搜索速度之间的tradeoff。
5. Summary
PQ通过对向量进行量化,降低向量搜索时所使用的内存,同时通过对向量分段量化,扩展映射空间。而IVF在PQ的基础上进一步减少搜索空间,从而降低了搜索时间。