How Lucene Stores Its Forward Index
This article will introduce how Lucene 9.6 stores its forward index, to help readers better understand its internal workings.
A forward index, also known as a direct index, is a basic data structure in information retrieval systems. It stores the content and attributes of each document in the order of the documents, allowing the system to quickly access detailed information of any specified document. In Lucene, the storage mechanism of forward data is one of the key factors enabling it to efficiently perform full-text searches.
Since the main focus of this article is the storage format of the forward index on the disk, the preprocessing of the document and how the docID is obtained will be ignored.
What is a Forward Index
Simply put, a forward index is a structure that allows querying the corresponding document through docID. We can compare it to a key-value pair, where docID is the key and the document content is the value.

Therefore, the layout of Lucene’s forward index on the disk must allow quick location of the document content through docID.
Building the Forward Index
The entry function for building the forward index is IndexingChain#processDocument (Lucene refers to the forward index as StoredFields).
void processDocument(int docID, Iterable<? extends IndexableField> document) throws IOException {
startStoredFields(docID);
try {
// skip .....
docFieldIdx = 0;
for (IndexableField field : document) {
if (processField(docID, field, docFields[docFieldIdx])) {
fields[indexedFieldCount] = docFields[docFieldIdx];
indexedFieldCount++;
}
docFieldIdx++;
}
} finally {
if (hasHitAbortingException == false) {
// skip ...
// finish forward index
finishStoredFields();
// skip ...
}
}
}If we only focus on the processing of the forward index, we will find that Lucene does three things for the forward index:
- Initialization based on
docID. - Processing each field in the document.
- Finalizing the forward index for this document.
If we are only interested in how the index is stored on the disk, we only need to pay attention to the last two points.
private boolean processField(int docID, IndexableField field, PerField pf) throws IOException {
// skip....
// Add stored fields
if (fieldType.stored()) {
StoredValue storedValue = field.storedValue();
if (storedValue == null) {
throw new IllegalArgumentException("Cannot store a null value");
} else if (storedValue.getType() == StoredValue.Type.STRING
&& storedValue.getStringValue().length() > IndexWriter.MAX_STORED_STRING_LENGTH) {
throw new IllegalArgumentException(
"stored field \""
+ field.name()
+ "\" is too large ("
+ storedValue.getStringValue().length()
+ " characters) to store");
}
try {
storedFieldsConsumer.writeField(pf.fieldInfo, storedValue);
} catch (Throwable th) {
onAbortingException(th);
throw th;
}
}
// skip...
}
void writeField(FieldInfo info, StoredValue value) throws IOException {
switch (value.getType()) {
case INTEGER -> writer.writeField(info, value.getIntValue());
case LONG -> writer.writeField(info, value.getLongValue());
case FLOAT -> writer.writeField(info, value.getFloatValue());
case DOUBLE -> writer.writeField(info, value.getDoubleValue());
case BINARY -> writer.writeField(info, value.getBinaryValue());
case STRING -> writer.writeField(info, value.getStringValue());
default -> throw new AssertionError();
}
}We can see that when processing the forward index, we use writeField to process each field in the document.
Let’s see how Lucene handles fixed-length and variable-length fields.
@Override
public void writeField(FieldInfo info, double value) throws IOException {
++numStoredFieldsInDoc;
final long infoAndBits = (((long) info.number) << TYPE_BITS) | NUMERIC_DOUBLE;
bufferedDocs.writeVLong(infoAndBits);
writeZDouble(bufferedDocs, value);
}
@Override
public void writeField(FieldInfo info, BytesRef value) throws IOException {
++numStoredFieldsInDoc;
final long infoAndBits = (((long) info.number) << TYPE_BITS) | BYTE_ARR;
bufferedDocs.writeVLong(infoAndBits);
bufferedDocs.writeVInt(value.length);
bufferedDocs.writeBytes(value.bytes, value.offset, value.length);
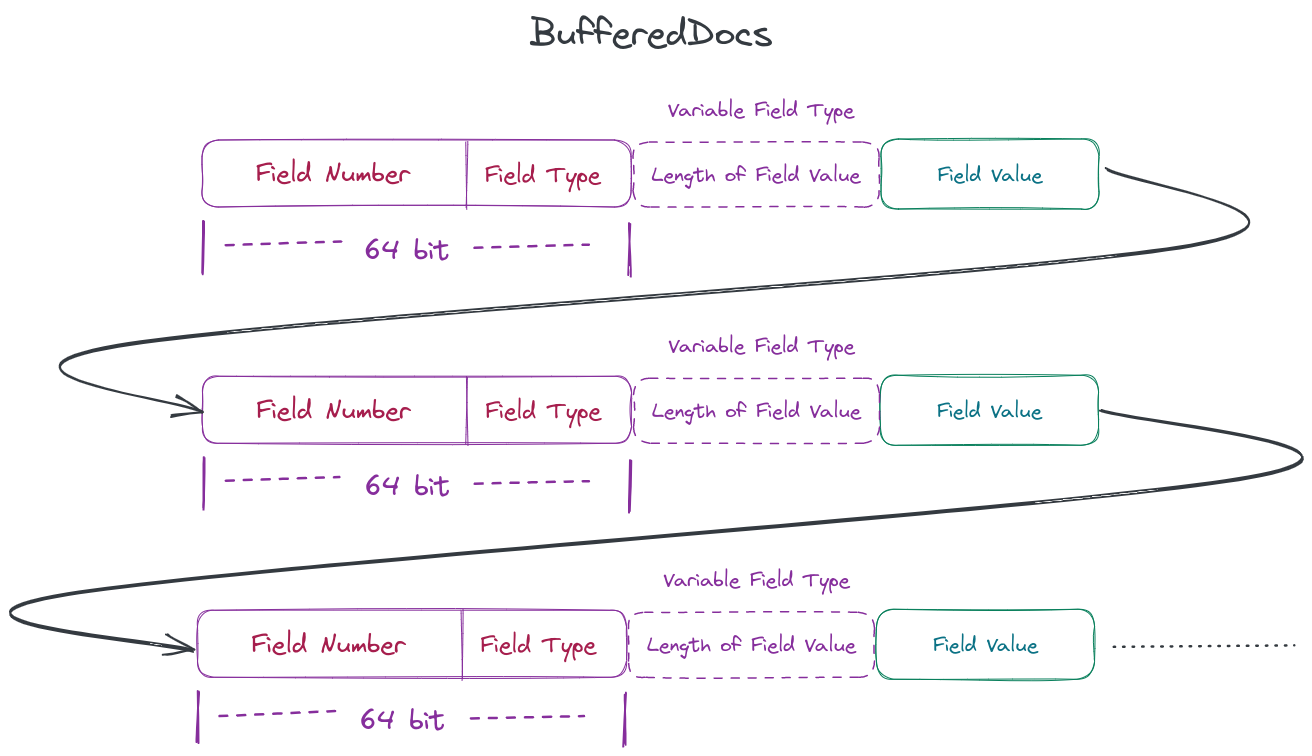
}The common point is that every time a field is written, numStoredFieldsInDoc++. This variable is easy to understand, recording how many fields are stored in this document. Then it adds the relevant information of this field to bufferedDocs (which can be considered as a memory array).
The relevant information of the field can be considered to have three types:
- Field number (each field has a unique number)
- Field data type
- Field data, that is, the value of the field.
Because the data type of the field is only a few limited types, Lucene will store it with the field number as a long type
final long infoAndBits = (((long) info.number) << TYPE_BITS) | NUMERIC_DOUBLE;When the field is of fixed length, we will directly write it into bufferedDocs. But when the field is variable length, we will first write the number of bytes occupied by this value into bufferedDocs, and then write this value into bufferedDocs.
After processing all the fields in each document, we can consider that we have buffered this document in memory, and then we need to finalize the forward index, that is, flush it to the disk. The function for finalizing the forward index of the document is finishDocument.
@Override
public void finishDocument() throws IOException {
if (numBufferedDocs == this.numStoredFields.length) {
final int newLength = ArrayUtil.oversize(numBufferedDocs + 1, 4);
this.numStoredFields = ArrayUtil.growExact(this.numStoredFields, newLength);
endOffsets = ArrayUtil.growExact(endOffsets, newLength);
}
this.numStoredFields[numBufferedDocs] = numStoredFieldsInDoc;
numStoredFieldsInDoc = 0;
endOffsets[numBufferedDocs] = Math.toIntExact(bufferedDocs.size());
++numBufferedDocs;
if (triggerFlush()) {
flush(false);
}
}In this function, we will find that it does four things:
- Record the number of fields that need to be stored in each document and save it in the array
numStoredFields. - Record the write-in position of the last byte of this document and save it in the array
endOffsets. - Record the number of documents currently stored in memory, saved in the variable
numBufferedDocs. - Determine whether it is necessary to flush the documents in memory to the disk. If a flush is needed, it is performed.
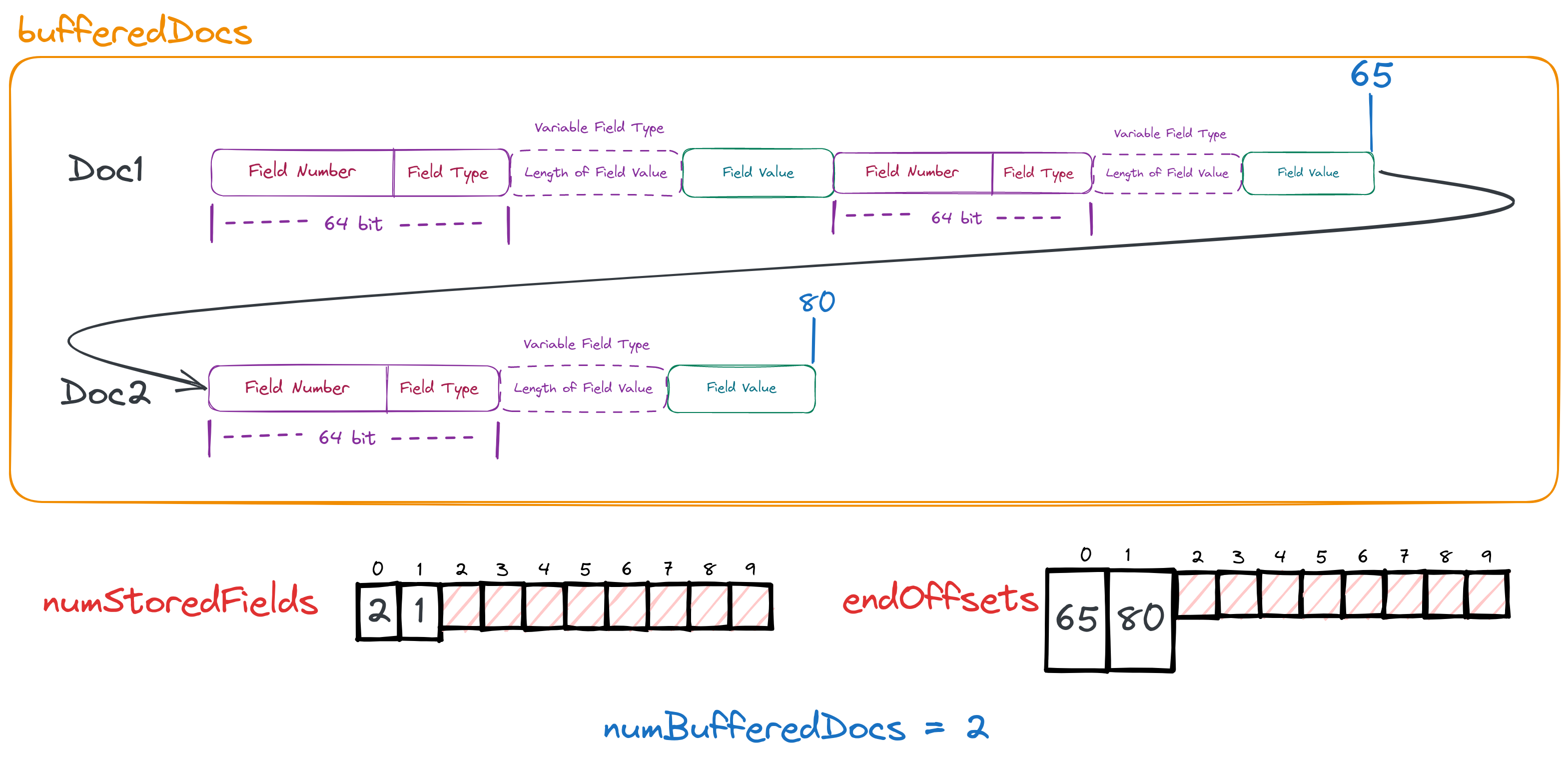
By the above diagram and code, we should have understood the first three points. Next, we will focus on the fourth point.
When to Flush to Disk
private boolean triggerFlush() {
return bufferedDocs.size() >= chunkSize
|| // chunks of at least chunkSize bytes
numBufferedDocs >= maxDocsPerChunk;
}
From the code, we can see that when the number of Docs cached in memory reaches a threshold or the Docs memory usage reaches a threshold, both will trigger the operation of flushing to disk.
Flushing to Disk
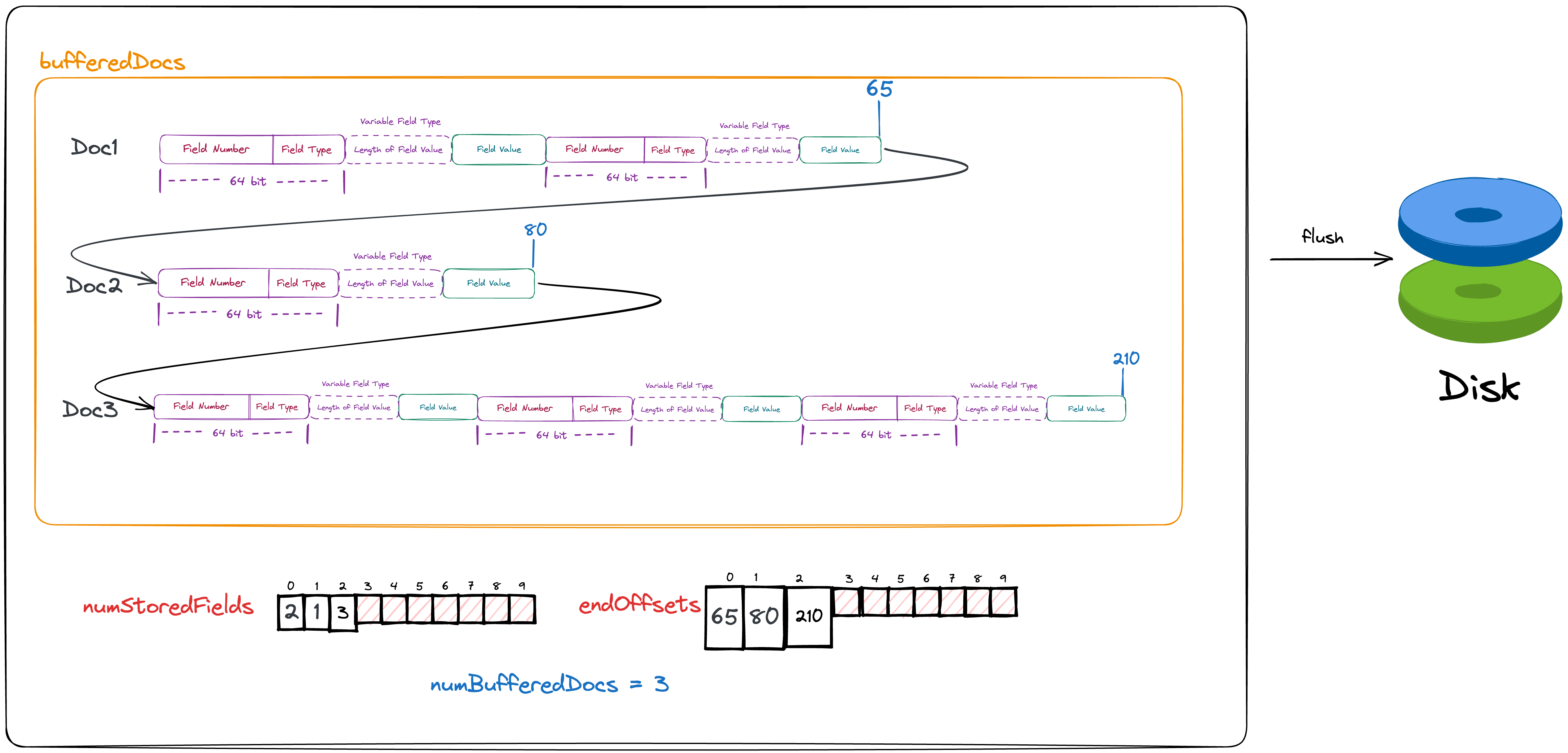
From here, we start to really understand how Lucene saves its forward data on the disk. Let’s assume that we have cached three documents in memory.
private void flush(boolean force) throws IOException {
// skip...
numChunks++;
// skip...
// transform end offsets into lengths
final int[] lengths = endOffsets;
for (int i = numBufferedDocs - 1; i > 0; --i) {
lengths[i] = endOffsets[i] - endOffsets[i - 1];
assert lengths[i] >= 0;
}
final boolean sliced = bufferedDocs.size() >= 2L * chunkSize;
final boolean dirtyChunk = force;
// skip...
}From the code, we can see that before actually writing to the disk, we still need to do some calculations in memory:
- Increment the number of chunks written to the disk.
- Convert the previously saved position of the last byte of each document (endOffsets) into the length of each document.
- Determine whether to slice, sliced.
- Determine whether it is a dirtyChunk.
The last two points can be ignored for now, just understand the first two.
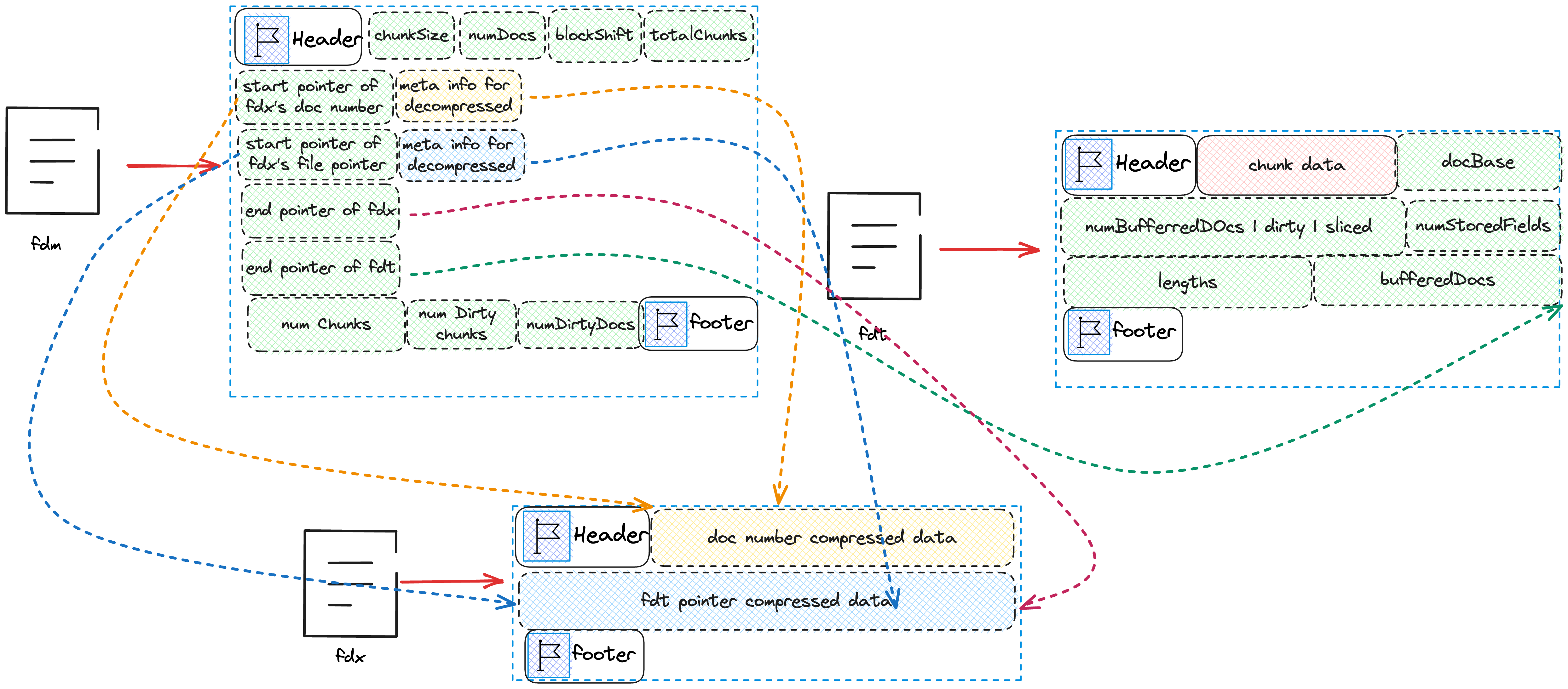
The files we need to write to the disk are five in total:
- fdt
- fdm
- fdx
- seg-xx-doc_ids
- seg-xx-file_pointers
Among them, 4 and 5 are temporary files and will not appear in the final index file. They only serve the task of temporarily storing data. The specific values of each variable in memory and the disk files that need to be written can be seen in the following figure.
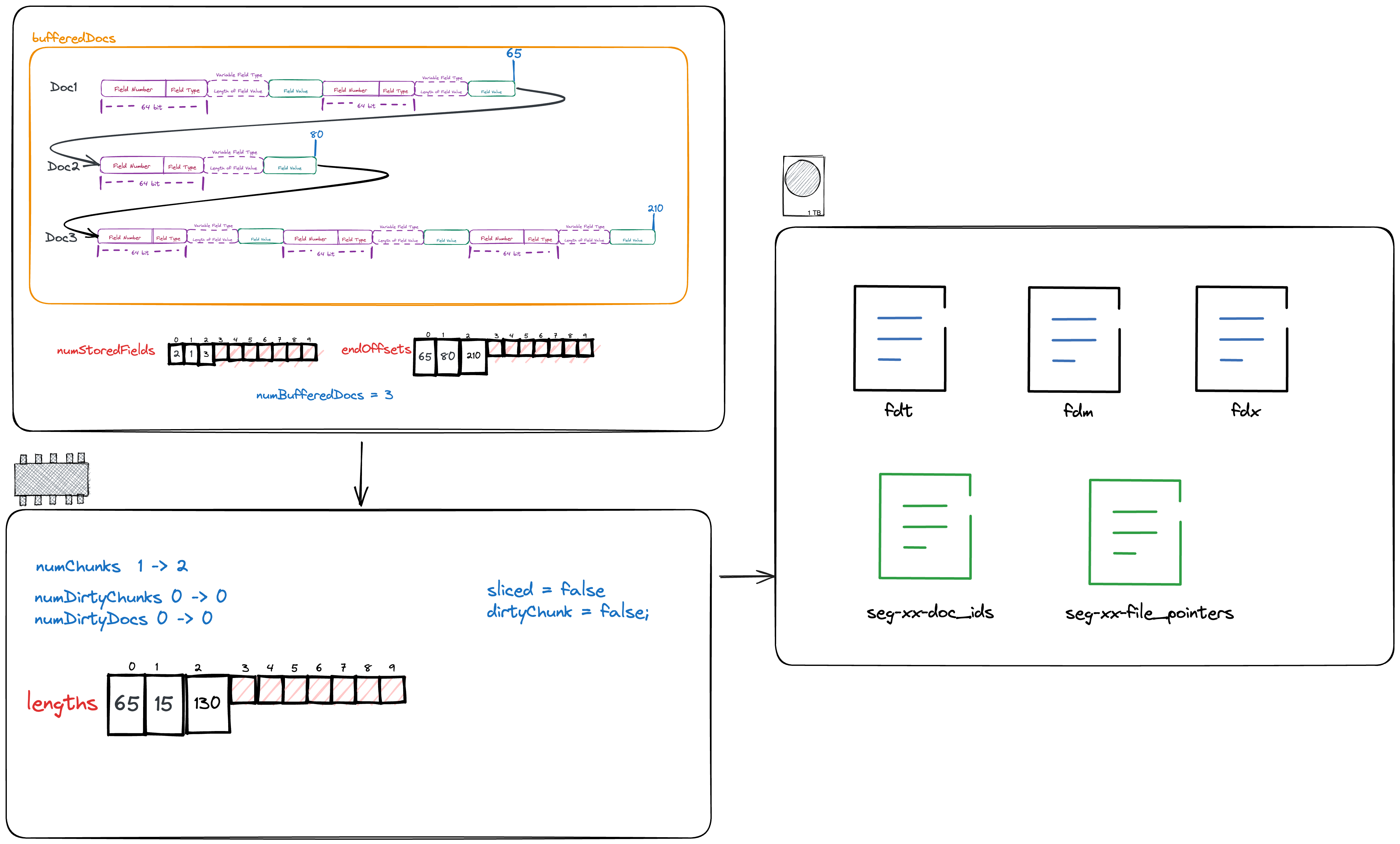
First, we will write the number of documents saved in this chunk and the starting position of this chunk in the fdt file to the files seg-xx-doc_ids and seg-xx-file_pointers.
private void flush(boolean force) throws IOException {
// skip...
indexWriter.writeIndex(numBufferedDocs, fieldsStream.getFilePointer());
//skip...
}
void writeIndex(int numDocs, long startPointer) throws IOException {
assert startPointer >= previousFP;
docsOut.writeVInt(numDocs);
filePointersOut.writeVLong(startPointer - previousFP);
previousFP = startPointer;
totalDocs += numDocs;
totalChunks++;
}We notice that when writing filePointers, we store not the actual value but the difference. This is because filePointers is definitely a continuously increasing array. In this case, storing the difference can make the elements actually stored smaller than the original value, which is conducive to compression. Imagine that the number of bits required to store 100000 is much greater than the number of bits required to store 3.
The state after writing the files seg-xx-doc_ids and seg-xx-file_pointers is as shown in the following figure.
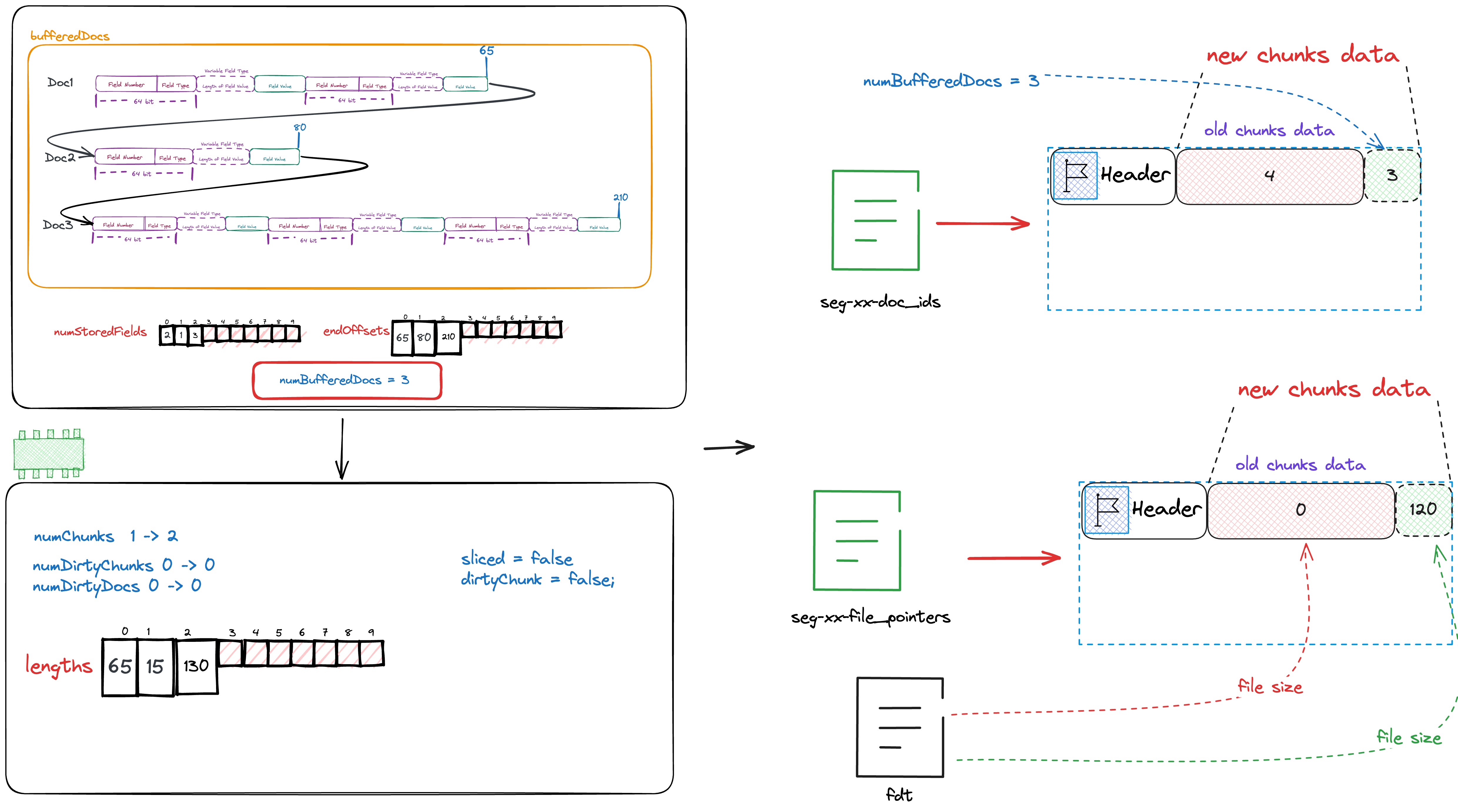
After writing the files seg-xx-doc_ids and seg-xx-file_pointers, we need to write the cached document content into the fdt file.
private void flush(boolean force) throws IOException {
// skip...
writeHeader(docBase, numBufferedDocs, numStoredFields, lengths, sliced, dirtyChunk);
//skip...
if (sliced) {
// big chunk, slice it, using ByteBuffersDataInput ignore memory copy
final int capacity = (int) bytebuffers.size();
for (int compressed = 0; compressed < capacity; compressed += chunkSize) {
int l = Math.min(chunkSize, capacity - compressed);
ByteBuffersDataInput bbdi = bytebuffers.slice(compressed, l);
compressor.compress(bbdi, fieldsStream);
}
} else {
compressor.compress(bytebuffers, fieldsStream);
}
}
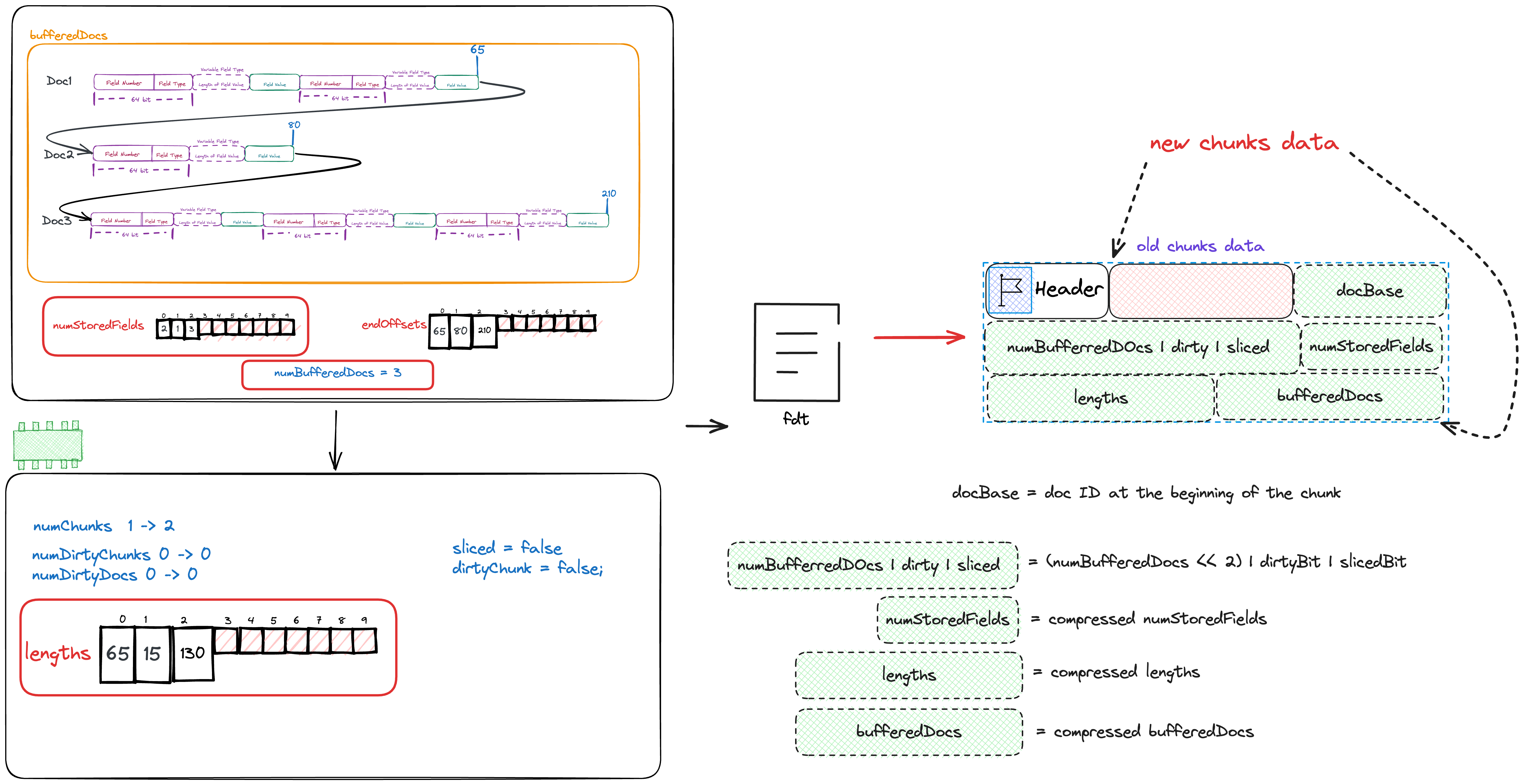
private void writeHeader(
int docBase,
int numBufferedDocs,
int[] numStoredFields,
int[] lengths,
boolean sliced,
boolean dirtyChunk)
throws IOException {
final int slicedBit = sliced ? 1 : 0;
final int dirtyBit = dirtyChunk ? 2 : 0;
// save docBase and numBufferedDocs
fieldsStream.writeVInt(docBase);
fieldsStream.writeVInt((numBufferedDocs << 2) | dirtyBit | slicedBit);
// save numStoredFields
saveInts(numStoredFields, numBufferedDocs, fieldsStream);
// save lengths
saveInts(lengths, numBufferedDocs, fieldsStream);
}
We can see that we will write docBase, numBufferedDocs, dirtyBit, slicedBit, numStoredFields, lengths, and bufferedDocs into fdt.
docBaseis the firstDocIDof this chunk.numBufferedDocsis the total number of Docs cached in this chunk.dirtyBit,slicedBitcan be ignored for now.- The array
numStoredFieldsis the number of fields to be stored for each Doc. - The array
lengthsis the length of each Doc. - The array
bufferedDocsis the actual stored data of all Docs.
The state after writing fdt is as shown in the following figure.
The function flush has been fully introduced. This is how Lucene processes one Doc after another, first caching them in memory, and then flushing them to the disk when a certain number is cached.
Generating the Final Index File
When Lucene has processed all the documents, it will call finish to generate the final index file.
@Override
public void finish(int numDocs) throws IOException {
if (numBufferedDocs > 0) {
flush(true);
} else {
assert bufferedDocs.size() == 0;
}
if (docBase != numDocs) {
throw new RuntimeException(
"Wrote " + docBase + " docs, finish called with numDocs=" + numDocs);
}
indexWriter.finish(numDocs, fieldsStream.getFilePointer(), metaStream);
metaStream.writeVLong(numChunks);
metaStream.writeVLong(numDirtyChunks);
metaStream.writeVLong(numDirtyDocs);
CodecUtil.writeFooter(metaStream);
CodecUtil.writeFooter(fieldsStream);
assert bufferedDocs.size() == 0;
}We can now understand what dirty means in flush. When
the Docs cached in memory have not reached the flush condition, but the documents have been fully processed, we need to forcibly flush them to the disk. In this case, we will set dirty to true. As for sliced, it is because if the length of bufferedDocs is very large, in order to ensure the effect of compression, we will slice it, compress the slices, and write them to the fdt file.
After flushing all the cached Docs to the disk, we start generating the fdx and fdm files.
We first focus on indexWriter.finish(numDocs, fieldsStream.getFilePointer(), metaStream);
void finish(int numDocs, long maxPointer, IndexOutput metaOut) throws IOException {
if (numDocs != totalDocs) {
throw new IllegalStateException("Expected " + numDocs + " docs, but got " + totalDocs);
}
CodecUtil.writeFooter(docsOut);
CodecUtil.writeFooter(filePointersOut);
IOUtils.close(docsOut, filePointersOut);
// skip...
}Lucene will first write a Footer to the files seg-xx-doc_ids and seg-xx-file_pointers to mark the completion of writing. Also, the Footer can protect the integrity of the file.
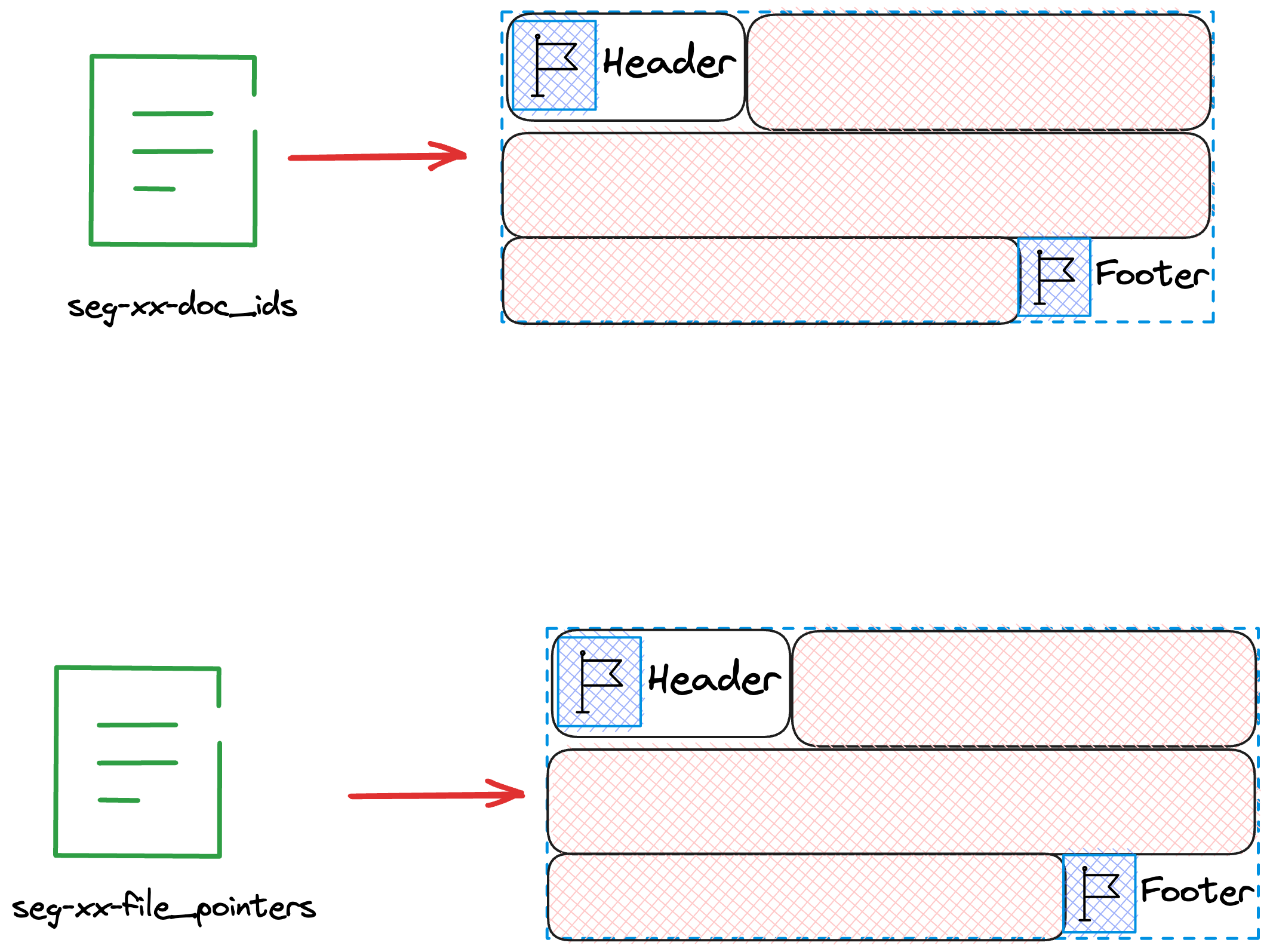
Then we will write into fdx and fdm.
void finish(int numDocs, long maxPointer, IndexOutput metaOut) throws IOException {
//skip...
try (IndexOutput dataOut =
dir.createOutput(IndexFileNames.segmentFileName(name, suffix, extension), ioContext)) {
CodecUtil.writeIndexHeader(dataOut, codecName + "Idx", VERSION_CURRENT, id, suffix);
metaOut.writeInt(numDocs);
metaOut.writeInt(blockShift);
metaOut.writeInt(totalChunks + 1);
metaOut.writeLong(dataOut.getFilePointer());
try (ChecksumIndexInput docsIn = dir.openChecksumInput(docsOut.getName())) {
CodecUtil.checkHeader(docsIn, codecName + "Docs", VERSION_CURRENT, VERSION_CURRENT);
Throwable priorE = null;
try {
final DirectMonotonicWriter docs =
DirectMonotonicWriter.getInstance(metaOut, dataOut, totalChunks + 1, blockShift);
long doc = 0;
docs.add(doc);
for (int i = 0; i < totalChunks; ++i) {
doc += docsIn.readVInt();
docs.add(doc);
}
docs.finish();
if (doc != totalDocs) {
throw new CorruptIndexException("Docs don't add up", docsIn);
}
} catch (Throwable e) {
priorE = e;
} finally {
CodecUtil.checkFooter(docsIn, priorE);
}
}
dir.deleteFile(docsOut.getName());
docsOut = null;
metaOut.writeLong(dataOut.getFilePointer());
try (ChecksumIndexInput filePointersIn = dir.openChecksumInput(filePointersOut.getName())) {
CodecUtil.checkHeader(
filePointersIn, codecName + "FilePointers", VERSION_CURRENT, VERSION_CURRENT);
Throwable priorE = null;
try {
final DirectMonotonicWriter filePointers =
DirectMonotonicWriter.getInstance(metaOut, dataOut, totalChunks + 1, blockShift);
long fp = 0;
for (int i = 0; i < totalChunks; ++i) {
fp += filePointersIn.readVLong();
filePointers.add(fp);
}
if (maxPointer < fp) {
throw new CorruptIndexException("File pointers don't add up", filePointersIn);
}
filePointers.add(maxPointer);
filePointers.finish();
} catch (Throwable e) {
priorE = e;
} finally {
CodecUtil.checkFooter(filePointersIn, priorE);
}
}
dir.deleteFile(filePointersOut.getName());
filePointersOut = null;
metaOut.writeLong(dataOut.getFilePointer());
metaOut.writeLong(maxPointer);
CodecUtil.writeFooter(dataOut);
}
}We will first write numDocs, blockShift, totalChunks+1, dataOut.getFilePointer() into fdm:
numDocsis the total number of docs.blockShiftis the meta information used for decompression and compression.totalChunks+1is the total number of chunks plus one.dataOut.getFilePointer()is the next position to be written in the fdx file.
Then we compress the content saved in the file seg-xx-doc_ids and write it into the fdx file, and write the meta information needed for decompression into fdm, and finally write the next position to be written in fdm into fdm. The same way, compress the content saved in the file seg-xx-file_pointers and write it into the fdx file, and write the meta information needed for decompression into fdm, and finally write the next position to be written in fdm and fdt into fdm. The final state is as shown in the following figure.
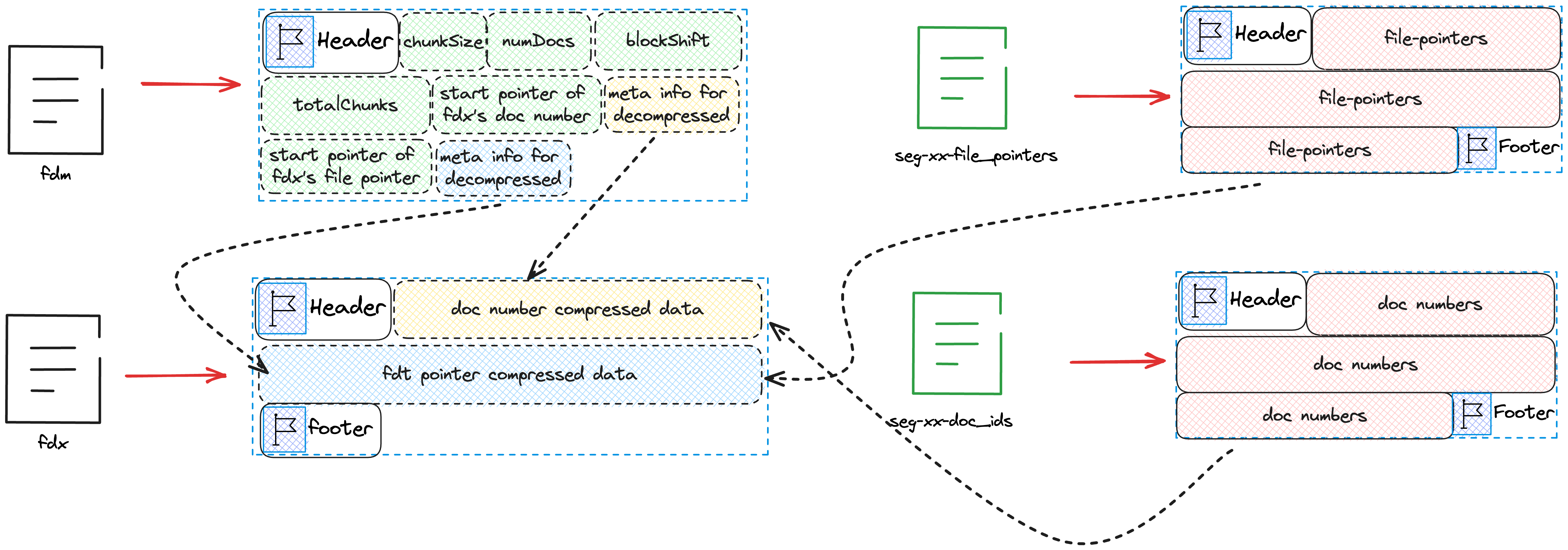
From the diagram, we notice that the chunkSize after the Header of fdm is not reflected in the above code. This is because this variable is written when fdm is created.
After completing the above steps, we only need to write numChunks, numDirtyChunks, numDirtyDocs into fdm.
@Override
public void finish(int numDocs) throws IOException {
//skip...
metaStream.writeVLong(numChunks);
metaStream.writeVLong(numDirtyChunks);
metaStream.writeVLong(numDirtyDocs);
CodecUtil.writeFooter(metaStream);
CodecUtil.writeFooter(fieldsStream);
assert bufferedDocs.size() == 0;
}Finally, the complete index file is as shown in the following figure.
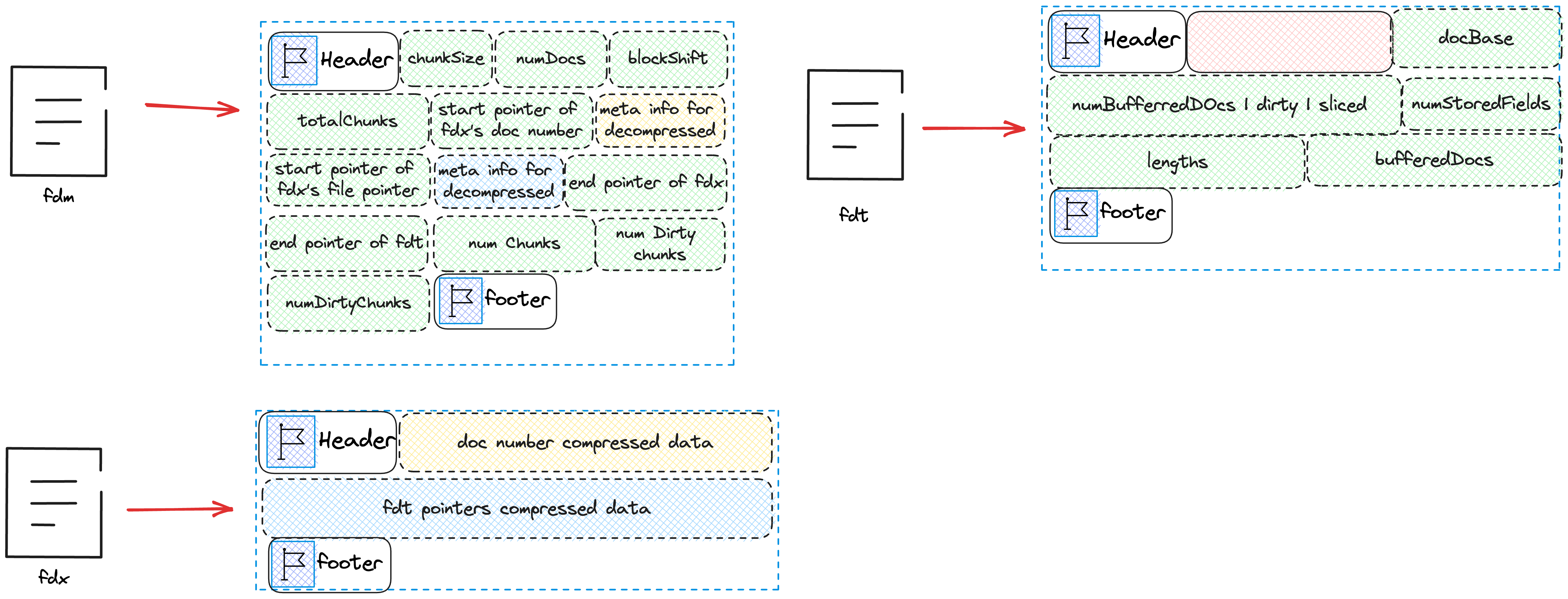
Overview
Finally, here is a schematic diagram of the index file and its relationships.