Lucene如何存储正排索引
本文将介绍Lucene9.6如何存储它的正排索引,以帮助读者更好地理解其内部工作原理。
正排索引,也被称为前向索引,是信息检索系统中的一种基本数据结构。它按照文档的顺序存储每个文档的内容和属性,使得系统能够快速地获取到任何指定文档的详细信息。在Lucene中,正排数据的存储机制是其能够高效执行全文搜索的关键因素之一。
因为本文的主要关注点是正排索引在磁盘中的存储格式,因此对于文档的预处理以及docID是如何获得会进行忽略。
什么是正排索引
简单来说,正排索引就是可以通过docID 查询到对应的文档。我们可以将其类比为键值对(Key-Value),其中docID为Key,文档内容为Value。

因此,Lucene的正排索引在磁盘中的布局必须能够通过docID快速定位到文档的内容。
正排索引的构建
正排索引构建的入口函数IndexingChain#processDocument (Lucene中将正排索引称为StoredFields)
void processDocument(int docID, Iterable<? extends IndexableField> document) throws IOException {
startStoredFields(docID);
try {
// skip .....
docFieldIdx = 0;
for (IndexableField field : document) {
if (processField(docID, field, docFields[docFieldIdx])) {
fields[indexedFieldCount] = docFields[docFieldIdx];
indexedFieldCount++;
}
docFieldIdx++;
}
} finally {
if (hasHitAbortingException == false) {
// skip ...
// finish forward index
finishStoredFields();
// skip ...
}
}
}我们如果只关注正排索引的处理,会发现Lucene对于正排索引一共会做三件事
- 根据
docID进行初始化。 - 对文档中的每一个字段进行处理。
- 对这篇doc中的正排索引进行收尾操作。
如果只是关注索引是如何存储在磁盘中的话,我们只需要关注后两件事。
private boolean processField(int docID, IndexableField field, PerField pf) throws IOException {
// skip....
// Add stored fields
if (fieldType.stored()) {
StoredValue storedValue = field.storedValue();
if (storedValue == null) {
throw new IllegalArgumentException("Cannot store a null value");
} else if (storedValue.getType() == StoredValue.Type.STRING
&& storedValue.getStringValue().length() > IndexWriter.MAX_STORED_STRING_LENGTH) {
throw new IllegalArgumentException(
"stored field \""
+ field.name()
+ "\" is too large ("
+ storedValue.getStringValue().length()
+ " characters) to store");
}
try {
storedFieldsConsumer.writeField(pf.fieldInfo, storedValue);
} catch (Throwable th) {
onAbortingException(th);
throw th;
}
}
// skip...
}
void writeField(FieldInfo info, StoredValue value) throws IOException {
switch (value.getType()) {
case INTEGER -> writer.writeField(info, value.getIntValue());
case LONG -> writer.writeField(info, value.getLongValue());
case FLOAT -> writer.writeField(info, value.getFloatValue());
case DOUBLE -> writer.writeField(info, value.getDoubleValue());
case BINARY -> writer.writeField(info, value.getBinaryValue());
case STRING -> writer.writeField(info, value.getStringValue());
default -> throw new AssertionError();
}
}我们可以发现在处理正排索引时,我们使用writeField对文档中的每一个字段进行处理。
我们看一下对于定长以及变长的字段,Lucene分别是如何处理的。
@Override
public void writeField(FieldInfo info, double value) throws IOException {
++numStoredFieldsInDoc;
final long infoAndBits = (((long) info.number) << TYPE_BITS) | NUMERIC_DOUBLE;
bufferedDocs.writeVLong(infoAndBits);
writeZDouble(bufferedDocs, value);
}
@Override
public void writeField(FieldInfo info, BytesRef value) throws IOException {
++numStoredFieldsInDoc;
final long infoAndBits = (((long) info.number) << TYPE_BITS) | BYTE_ARR;
bufferedDocs.writeVLong(infoAndBits);
bufferedDocs.writeVInt(value.length);
bufferedDocs.writeBytes(value.bytes, value.offset, value.length);
}我们可以发现,无论字段是定长还是变长,每写入一个字段,都会使numStoredFieldsInDoc增加1。这个变量很好理解,它记录了这篇文档中存储了多少个字段。随后会向bufferedDocs(可以认为是一个内存数组)添加这个字段的相关信息。
字段的相关信息我们可以认为有三种
- 字段的编号(每个字段都有一个独一无二的编号)
- 字段的数据类型
- 字段的数据,即该字段的值。
因为字段的数据类型只有有限的几种,因此Lucene会将其与字段的编号一起存储为一个long类型
final long infoAndBits = (((long) info.number) << TYPE_BITS) | NUMERIC_DOUBLE;而当字段为定长时,我们会直接将其写入bufferedDocs。但是当字段为变长时,我们会先将该值所占的bytes数写入bufferedDocs后,再将该值写入bufferedDocs。因此我们可以认为bufferedDocs的数据格式为
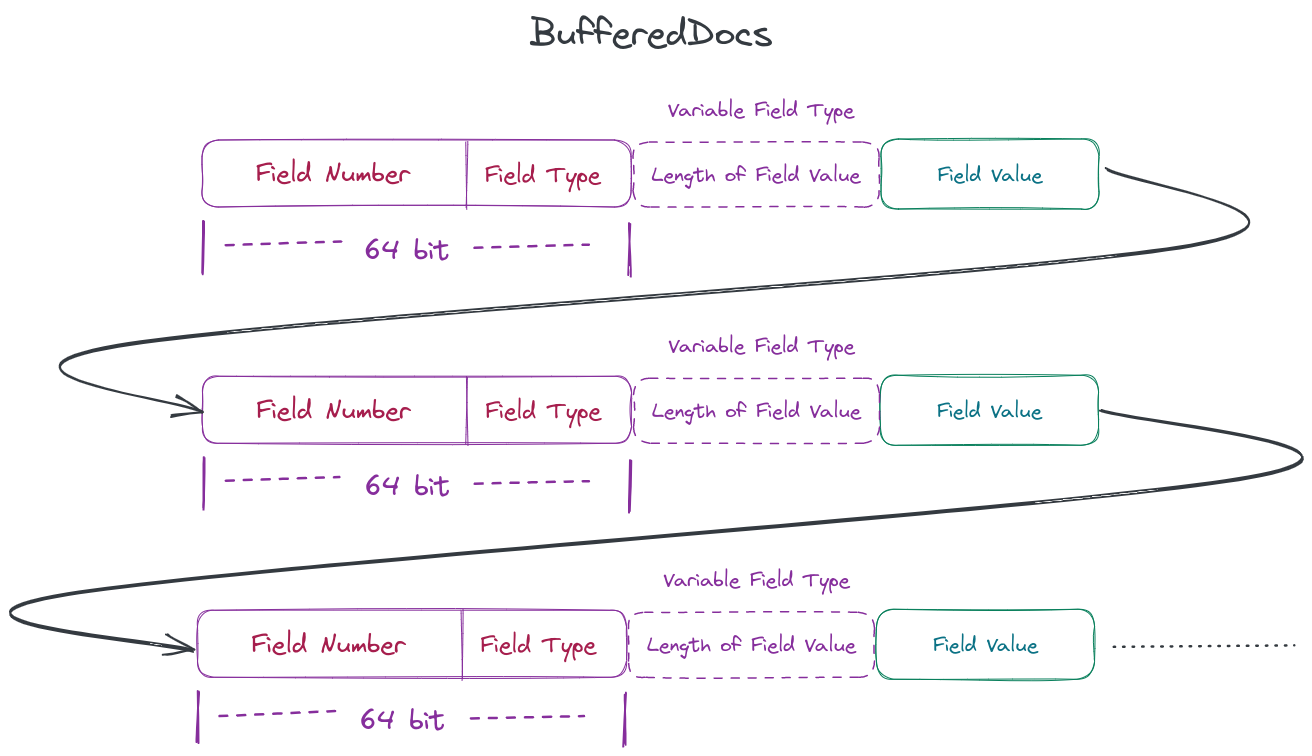
当处理完每篇文档的字段后,我们可以认为我们已经将这篇文档缓存在了内存中,而后我们需要做的就是对正排索引进行收尾工作,即将其flush到磁盘中。
对文档的正排索引进行收尾工作的函数为finishDocument
@Override
public void finishDocument() throws IOException {
if (numBufferedDocs == this.numStoredFields.length) {
final int newLength = ArrayUtil.oversize(numBufferedDocs + 1, 4);
this.numStoredFields = ArrayUtil.growExact(this.numStoredFields, newLength);
endOffsets = ArrayUtil.growExact(endOffsets, newLength);
}
this.numStoredFields[numBufferedDocs] = numStoredFieldsInDoc;
numStoredFieldsInDoc = 0;
endOffsets[numBufferedDocs] = Math.toIntExact(bufferedDocs.size());
++numBufferedDocs;
if (triggerFlush()) {
flush(false);
}
}在这个函数中我们会发现它一共做了四件事
- 将每一篇文档中需要进行存储的字段数量记录下来,保存在数组
numStoredFields中 - 记录下这篇文档最后一个byte的写入位置,保存在数组
endOffsets中 - 记录下目前已经在内存中存储的文档数,保存在变量
numBufferedDocs。 - 判断是否需要将内存中的文档刷到磁盘中, 如果需要进行flush。
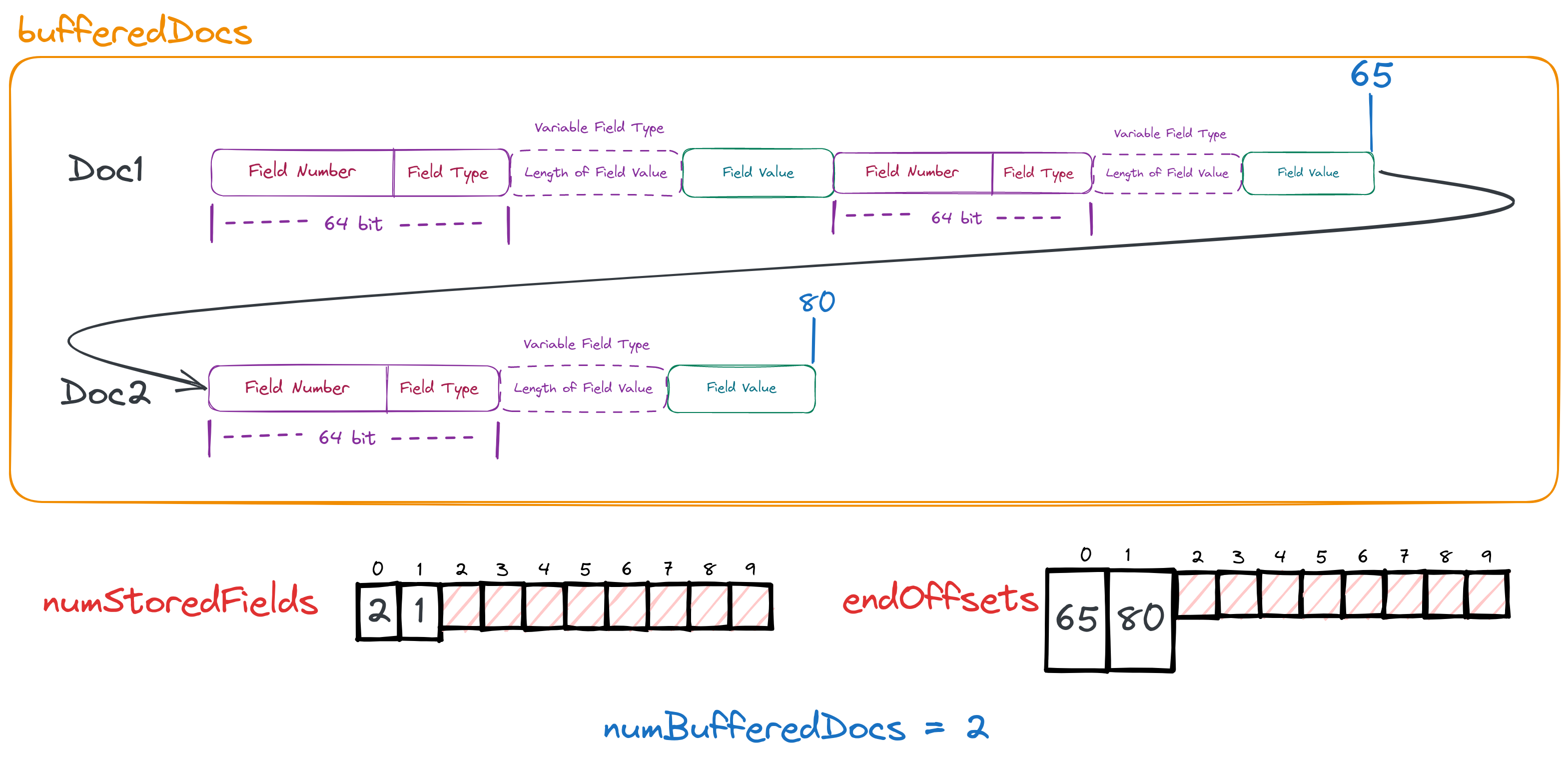
通过上面的图和代码,我们应该已经明白了前三件事,后续我们重点关注第四件事。
刷到磁盘的时机
private boolean triggerFlush() {
return bufferedDocs.size() >= chunkSize
|| // chunks of at least chunkSize bytes
numBufferedDocs >= maxDocsPerChunk;
}
从代码中我们可以看到,当内存中缓存的Doc数量达到阈值或者缓存的Doc所占用的内存达到阈值时,都会触发落盘这一操作。
刷新到磁盘
从这里开始,我们开始真正了解,Lucene是如何将他的正排数据保存在磁盘中。我们假设我们内存中一共缓存了三篇文档。
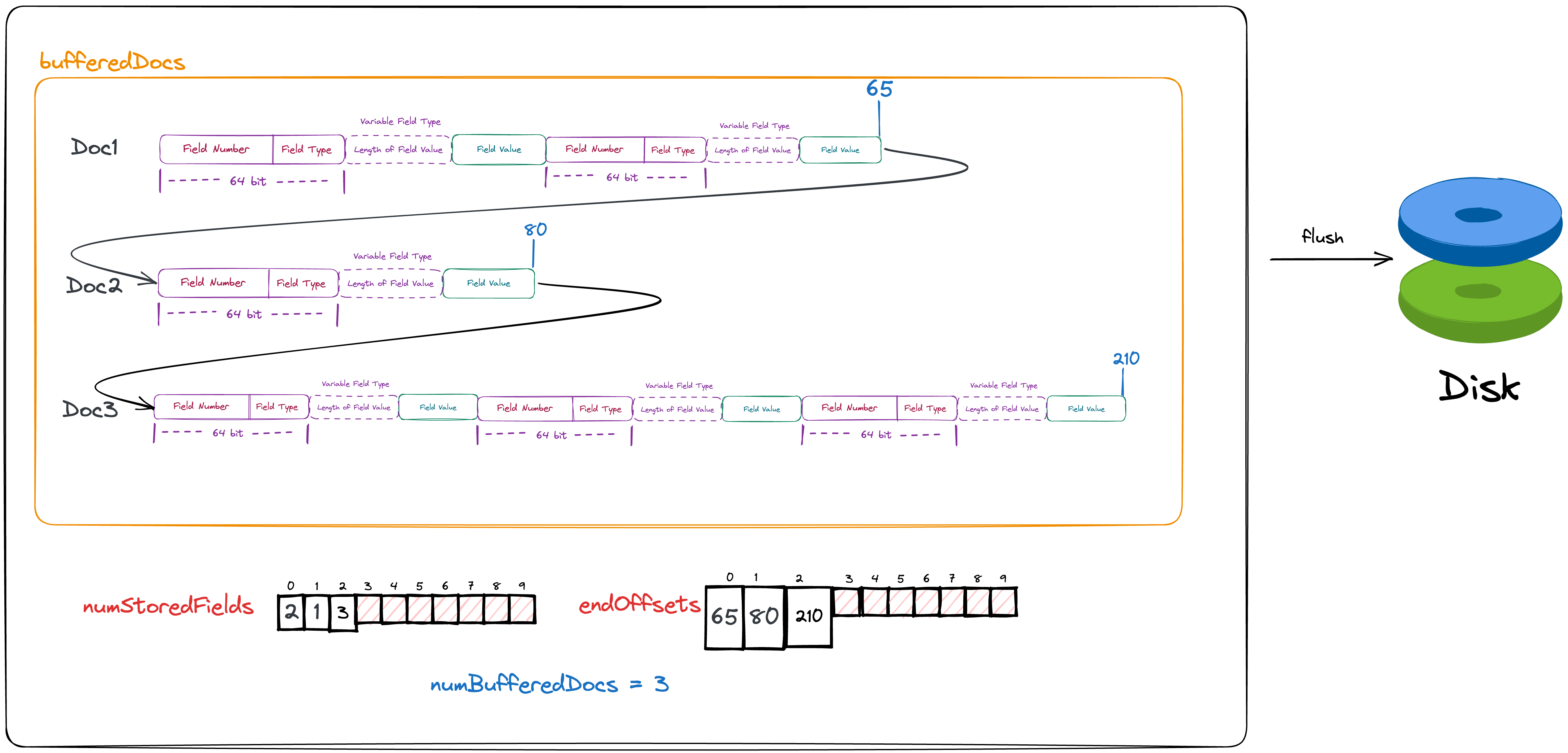
private void flush(boolean force) throws IOException {
// skip...
numChunks++;
// skip...
// transform end offsets into lengths
final int[] lengths = endOffsets;
for (int i = numBufferedDocs - 1; i > 0; --i) {
lengths[i] = endOffsets[i] - endOffsets[i - 1];
assert lengths[i] >= 0;
}
final boolean sliced = bufferedDocs.size() >= 2L * chunkSize;
final boolean dirtyChunk = force;
// skip...
}从代码中我们可以看到在实际写到磁盘前,我们仍然需要在内存中做一些计算
- 递增写到磁盘的chunk数
- 将之前保存的每篇文档最后一byte所处的位置(endOffsets)转化为每篇文档的长度。
- 判断是否需要分片, sliced
- 判断是否为dirtyChunk
后两个目前不需要了解,只需要理解前两个即可。 我们需要向磁盘中写入的文件一共有5个
- fdt
- fdm
- fdx
- seg-xx-doc_ids
- seg-xx-file_pointers
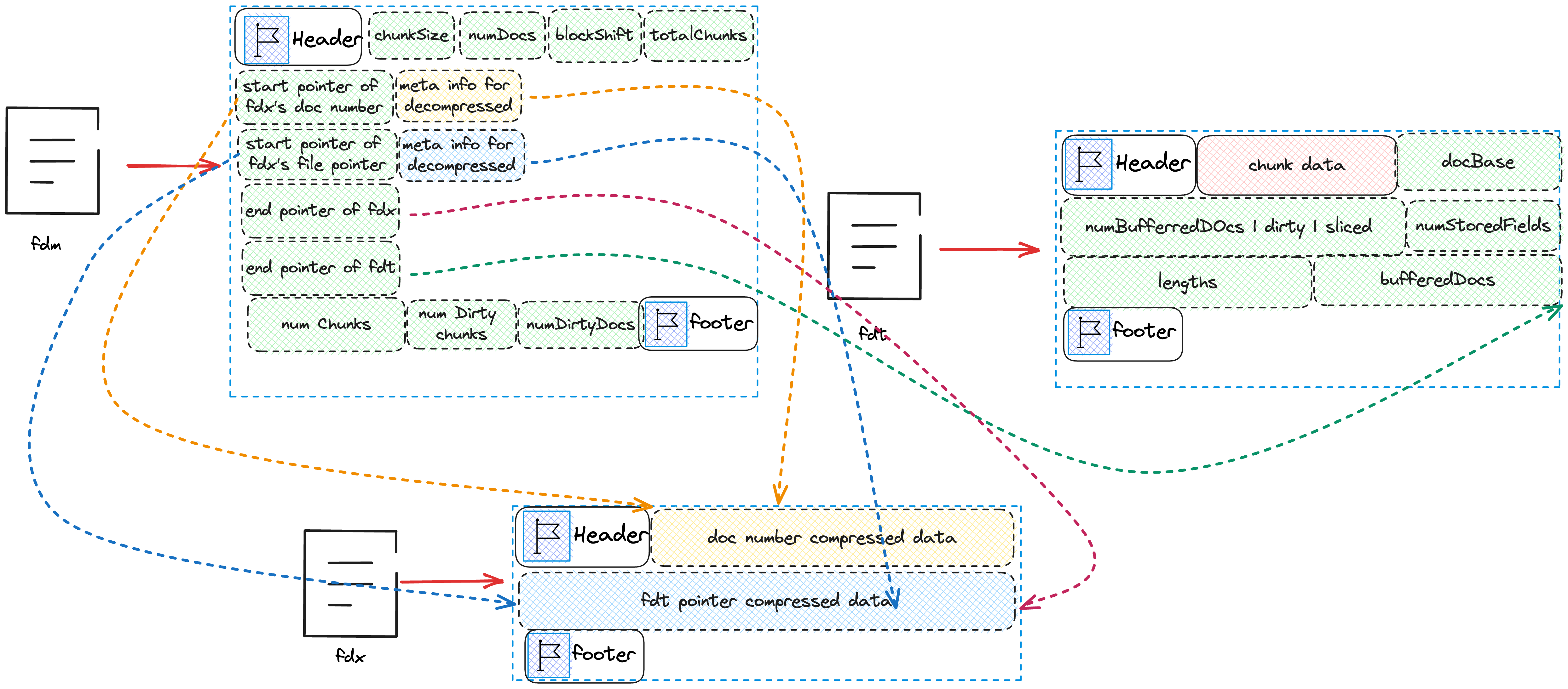
其中4,5为临时文件,并不会出现在最后的索引文件中,仅仅起到暂时存储数据的任务。具体内存中各变量的值,以及需要写的磁盘文件可见下图。
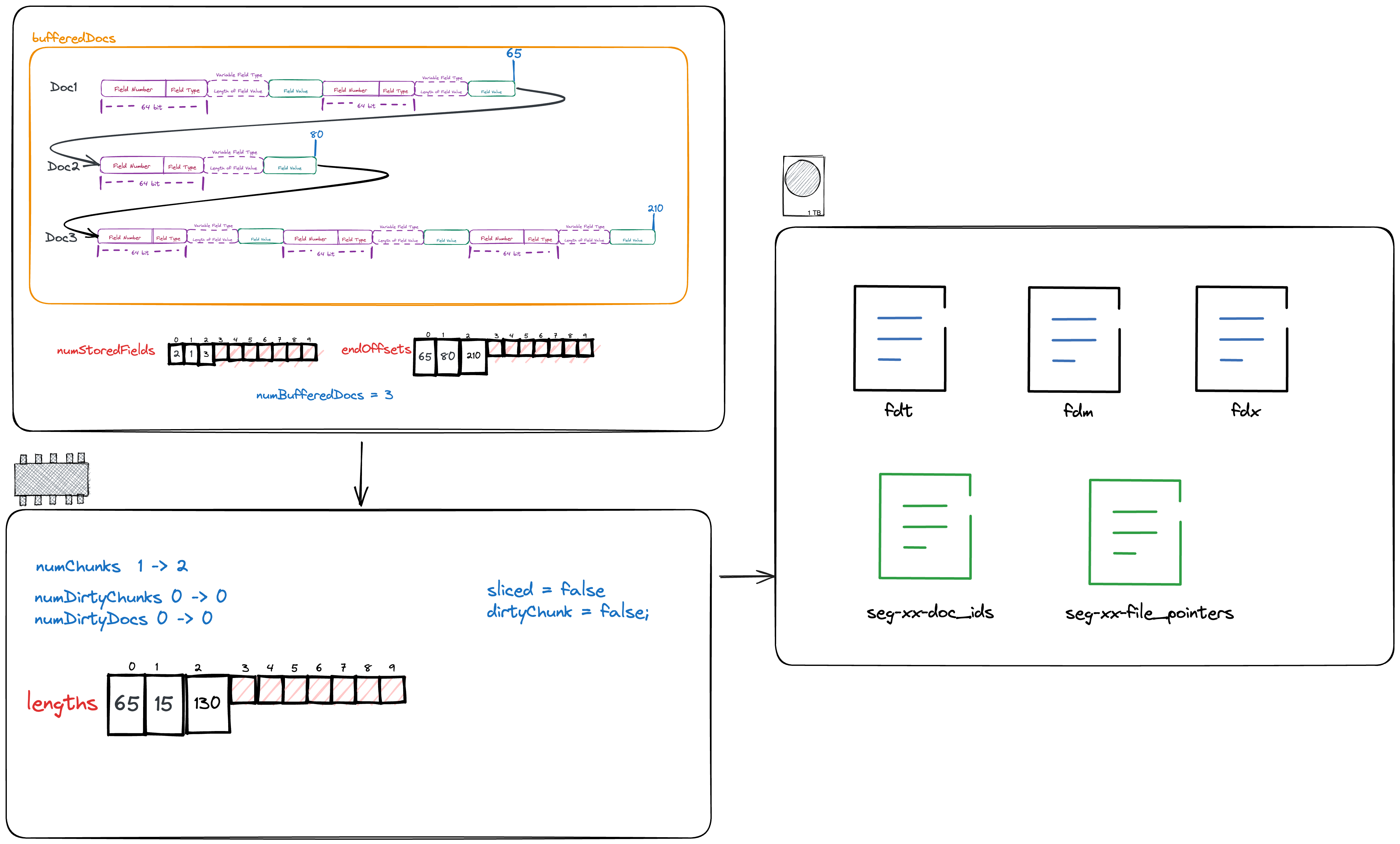
首先我们会将该chunk所保存的文档数以及该chunk在fdt文件中的起始位置写到文件seg-xx-doc_ids,seg-xx-file_pointers中。
private void flush(boolean force) throws IOException {
// skip...
indexWriter.writeIndex(numBufferedDocs, fieldsStream.getFilePointer());
//skip...
}
void writeIndex(int numDocs, long startPointer) throws IOException {
assert startPointer >= previousFP;
docsOut.writeVInt(numDocs);
filePointersOut.writeVLong(startPointer - previousFP);
previousFP = startPointer;
totalDocs += numDocs;
totalChunks++;
}我们注意到当写filePointers时,我们存的并不是实际的值而是差值,这是因为filePointers一定是连续递增的数组,对于这种情况 存储差值可以使得实际存储的元素相较于原值更小,从而有利于压缩。想象一下,存储100000所需要的bit数是远大于3所需要的bit数。 写完文件seg-xx-doc_ids,seg-xx-file_pointers后的状态可参考下图。
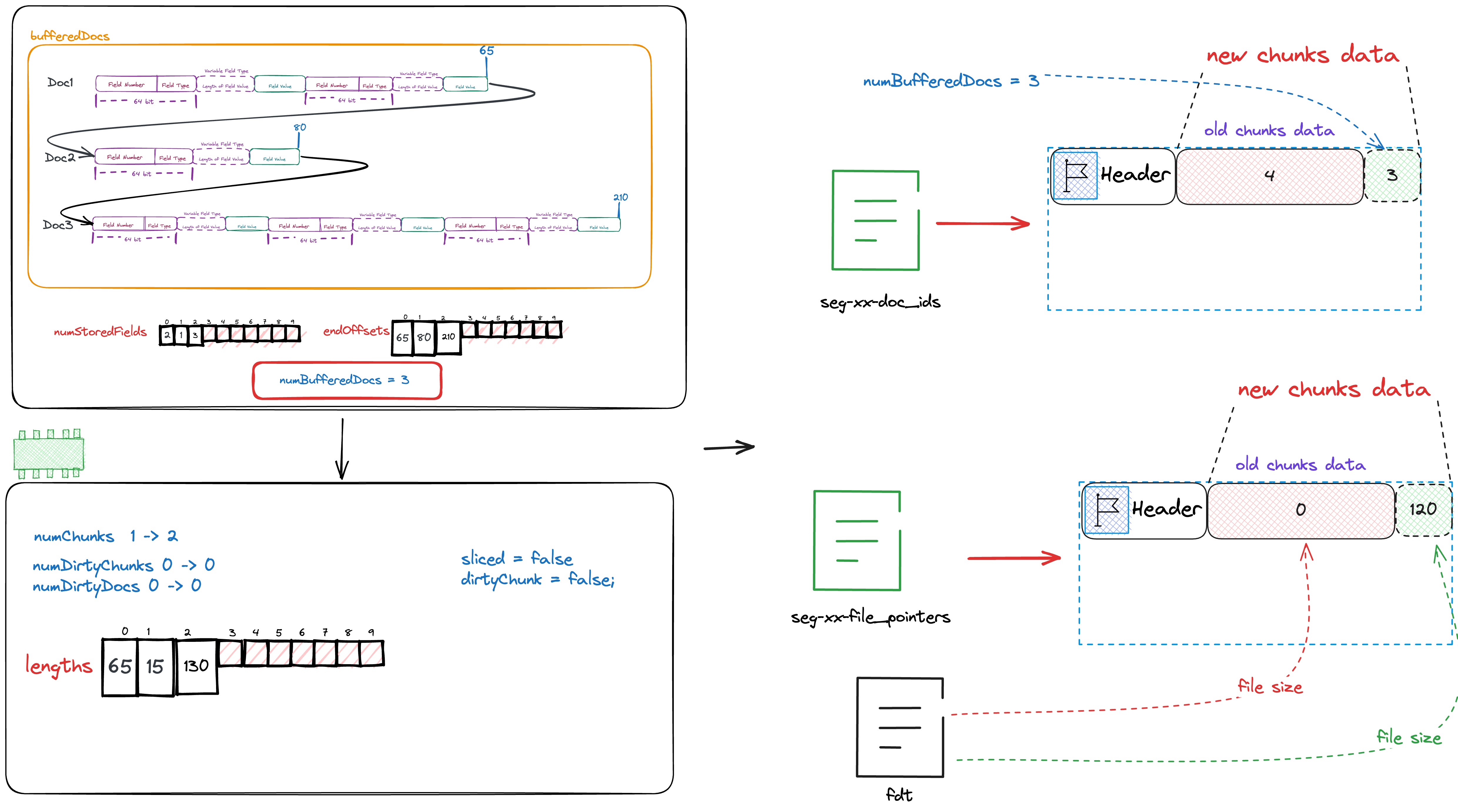
在写完文件seg-xx-doc_ids,seg-xx-file_pointers后,我们需要将缓存的文档内容写入文件fdt中。
private void flush(boolean force) throws IOException {
// skip...
writeHeader(docBase, numBufferedDocs, numStoredFields, lengths, sliced, dirtyChunk);
//skip...
if (sliced) {
// big chunk, slice it, using ByteBuffersDataInput ignore memory copy
final int capacity = (int) bytebuffers.size();
for (int compressed = 0; compressed < capacity; compressed += chunkSize) {
int l = Math.min(chunkSize, capacity - compressed);
ByteBuffersDataInput bbdi = bytebuffers.slice(compressed, l);
compressor.compress(bbdi, fieldsStream);
}
} else {
compressor.compress(bytebuffers, fieldsStream);
}
}
private void writeHeader(
int docBase,
int numBufferedDocs,
int[] numStoredFields,
int[] lengths,
boolean sliced,
boolean dirtyChunk)
throws IOException {
final int slicedBit = sliced ? 1 : 0;
final int dirtyBit = dirtyChunk ? 2 : 0;
// save docBase and numBufferedDocs
fieldsStream.writeVInt(docBase);
fieldsStream.writeVInt((numBufferedDocs << 2) | dirtyBit | slicedBit);
// save numStoredFields
saveInts(numStoredFields, numBufferedDocs, fieldsStream);
// save lengths
saveInts(lengths, numBufferedDocs, fieldsStream);
}
可以看到我们会向fdt中写入docBase,numBufferedDocs,dirtyBit,slicedBit,numStoredFields,lengths以及bufferedDocs.
docBase为这个chunk的第一个DocID。numBufferedDocs为这个chunk总共缓存的Doc数dirtyBit,slicedBit目前可以忽略- 数组
numStoredFields为每篇Doc需要存储的字段数量 - 数组
lengths为每篇Doc的长度 - 数组
numBufferedDocs为全部Doc实际存储的数据。
写完fdt后的状态如下图所示
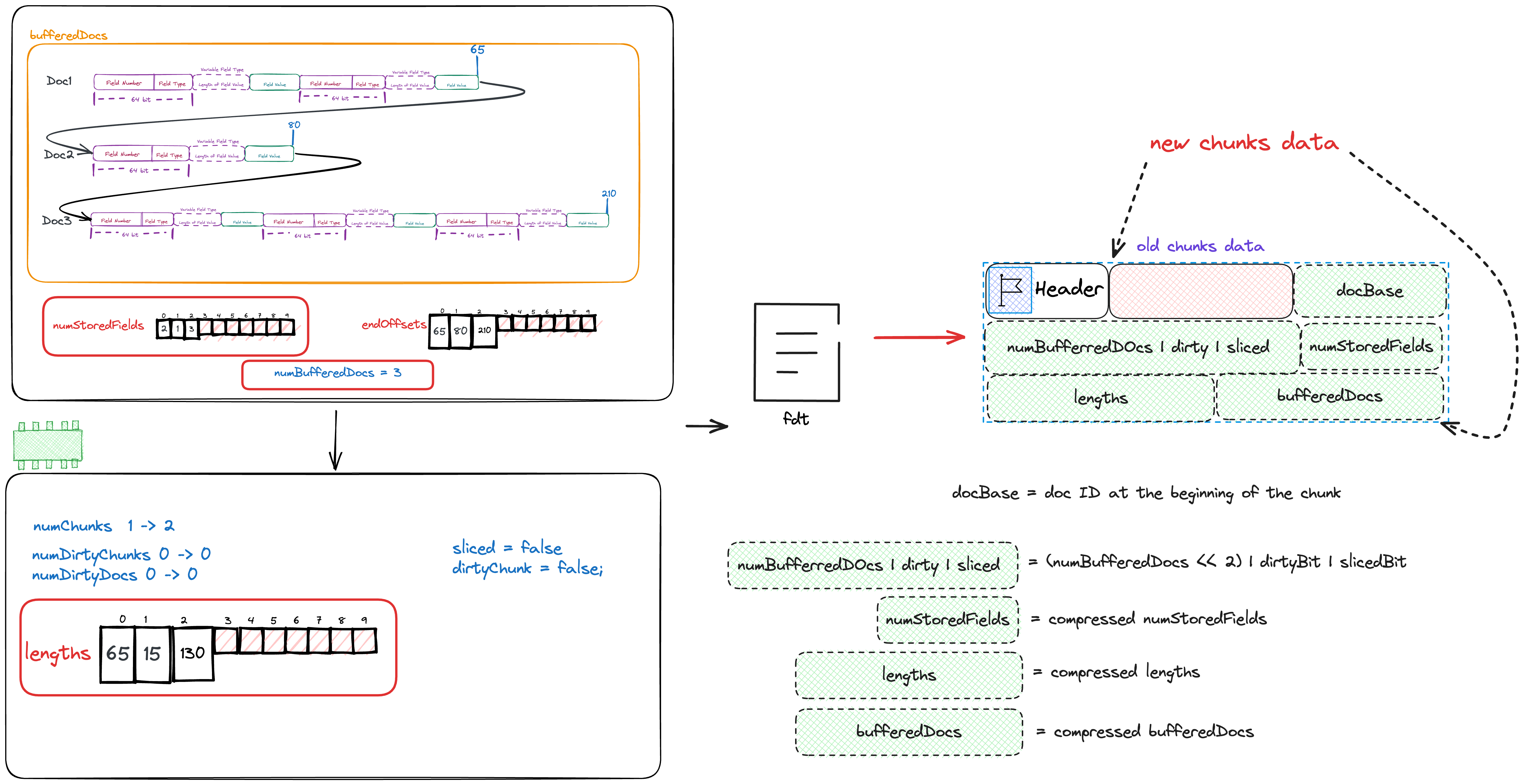
函数flush目前全部介绍完毕,Lucene就是这样处理一篇一篇的Doc,先缓存在内存中,当缓存一定数量后再flush到磁盘中。
生成最后的索引文件
当Lucene处理完全部的文档后,会调用finish生成最后的索引文件。
@Override
public void finish(int numDocs) throws IOException {
if (numBufferedDocs > 0) {
flush(true);
} else {
assert bufferedDocs.size() == 0;
}
if (docBase != numDocs) {
throw new RuntimeException(
"Wrote " + docBase + " docs, finish called with numDocs=" + numDocs);
}
indexWriter.finish(numDocs, fieldsStream.getFilePointer(), metaStream);
metaStream.writeVLong(numChunks);
metaStream.writeVLong(numDirtyChunks);
metaStream.writeVLong(numDirtyDocs);
CodecUtil.writeFooter(metaStream);
CodecUtil.writeFooter(fieldsStream);
assert bufferedDocs.size() == 0;
}通过这个函数我们现在可以知道flush中的dirty是什么意思,当我们内存缓存的Doc并未达到flush的条件,但是文档已经处理完了,我们需要将其强制
flush到磁盘中,对于这种情况,我们会将dirty设置为true。至于sliced则是因为如果bufferedDocs的长度很大,为了保证压缩的效果,我们会对其
进行分片,分片压缩并写入到文件fdt中。
在将缓存的Doc全部flush到磁盘后,我们开始生成文件fdx,fdm。
我们先关注indexWriter.finish(numDocs, fieldsStream.getFilePointer(), metaStream);
void finish(int numDocs, long maxPointer, IndexOutput metaOut) throws IOException {
if (numDocs != totalDocs) {
throw new IllegalStateException("Expected " + numDocs + " docs, but got " + totalDocs);
}
CodecUtil.writeFooter(docsOut);
CodecUtil.writeFooter(filePointersOut);
IOUtils.close(docsOut, filePointersOut);
// skip...
}Lucene首先会给文件seg-xx-doc_ids,seg-xx-file_pointers写上Footer标记写入完成。同时Footer也可以保护文件的完整性。
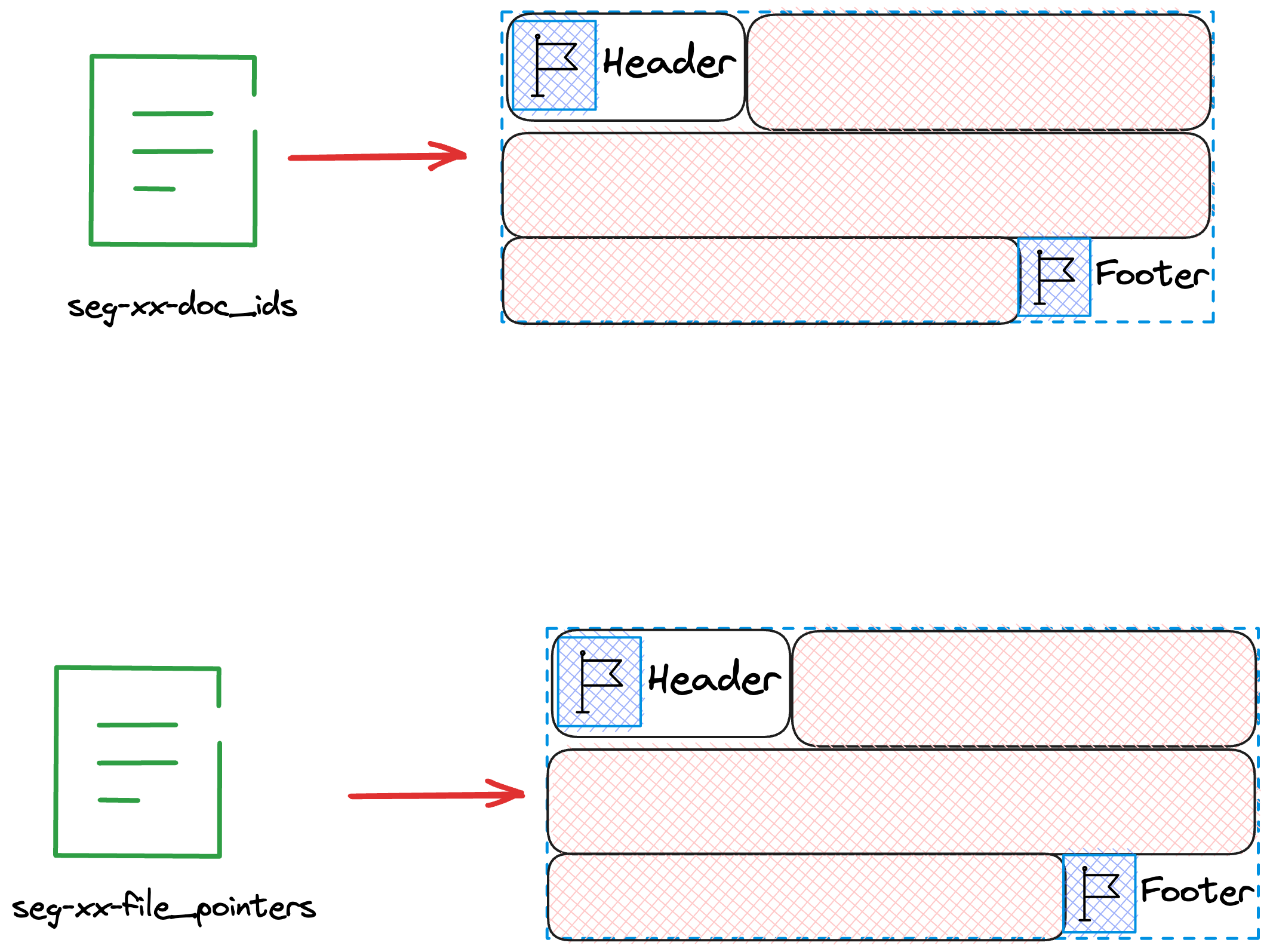
随后我们会像fdx以及fdm中写入
void finish(int numDocs, long maxPointer, IndexOutput metaOut) throws IOException {
//skip...
try (IndexOutput dataOut =
dir.createOutput(IndexFileNames.segmentFileName(name, suffix, extension), ioContext)) {
CodecUtil.writeIndexHeader(dataOut, codecName + "Idx", VERSION_CURRENT, id, suffix);
metaOut.writeInt(numDocs);
metaOut.writeInt(blockShift);
metaOut.writeInt(totalChunks + 1);
metaOut.writeLong(dataOut.getFilePointer());
try (ChecksumIndexInput docsIn = dir.openChecksumInput(docsOut.getName())) {
CodecUtil.checkHeader(docsIn, codecName + "Docs", VERSION_CURRENT, VERSION_CURRENT);
Throwable priorE = null;
try {
final DirectMonotonicWriter docs =
DirectMonotonicWriter.getInstance(metaOut, dataOut, totalChunks + 1, blockShift);
long doc = 0;
docs.add(doc);
for (int i = 0; i < totalChunks; ++i) {
doc += docsIn.readVInt();
docs.add(doc);
}
docs.finish();
if (doc != totalDocs) {
throw new CorruptIndexException("Docs don't add up", docsIn);
}
} catch (Throwable e) {
priorE = e;
} finally {
CodecUtil.checkFooter(docsIn, priorE);
}
}
dir.deleteFile(docsOut.getName());
docsOut = null;
metaOut.writeLong(dataOut.getFilePointer());
try (ChecksumIndexInput filePointersIn = dir.openChecksumInput(filePointersOut.getName())) {
CodecUtil.checkHeader(
filePointersIn, codecName + "FilePointers", VERSION_CURRENT, VERSION_CURRENT);
Throwable priorE = null;
try {
final DirectMonotonicWriter filePointers =
DirectMonotonicWriter.getInstance(metaOut, dataOut, totalChunks + 1, blockShift);
long fp = 0;
for (int i = 0; i < totalChunks; ++i) {
fp += filePointersIn.readVLong();
filePointers.add(fp);
}
if (maxPointer < fp) {
throw new CorruptIndexException("File pointers don't add up", filePointersIn);
}
filePointers.add(maxPointer);
filePointers.finish();
} catch (Throwable e) {
priorE = e;
} finally {
CodecUtil.checkFooter(filePointersIn, priorE);
}
}
dir.deleteFile(filePointersOut.getName());
filePointersOut = null;
metaOut.writeLong(dataOut.getFilePointer());
metaOut.writeLong(maxPointer);
CodecUtil.writeFooter(dataOut);
}
}我们首先会向fdm中写入numDocs,blockShift,totalChunks+1,dataOut.getFilePointer()
numDocs全量的doc数blockShift用于解压以及压缩的元信息totalChunks+1全部的chunk数+1dataOut.getFilePointer()文件fdx下一个待写入的位置。
随后将文件seg-xx-doc_ids中保存的内容压缩后写入fdx中, 并将解压所需要的元信息写入fdm,最后将fdx下一个待写入的位置写入fdm。 同样的方式将seg-xx-file_pointers中保存的内容压缩后写入fdx中, 并将解压所需要的元信息写入fdm,并将fdx以及fdt下一个待写入的位置写入fdm。 最终的状态如下图所示
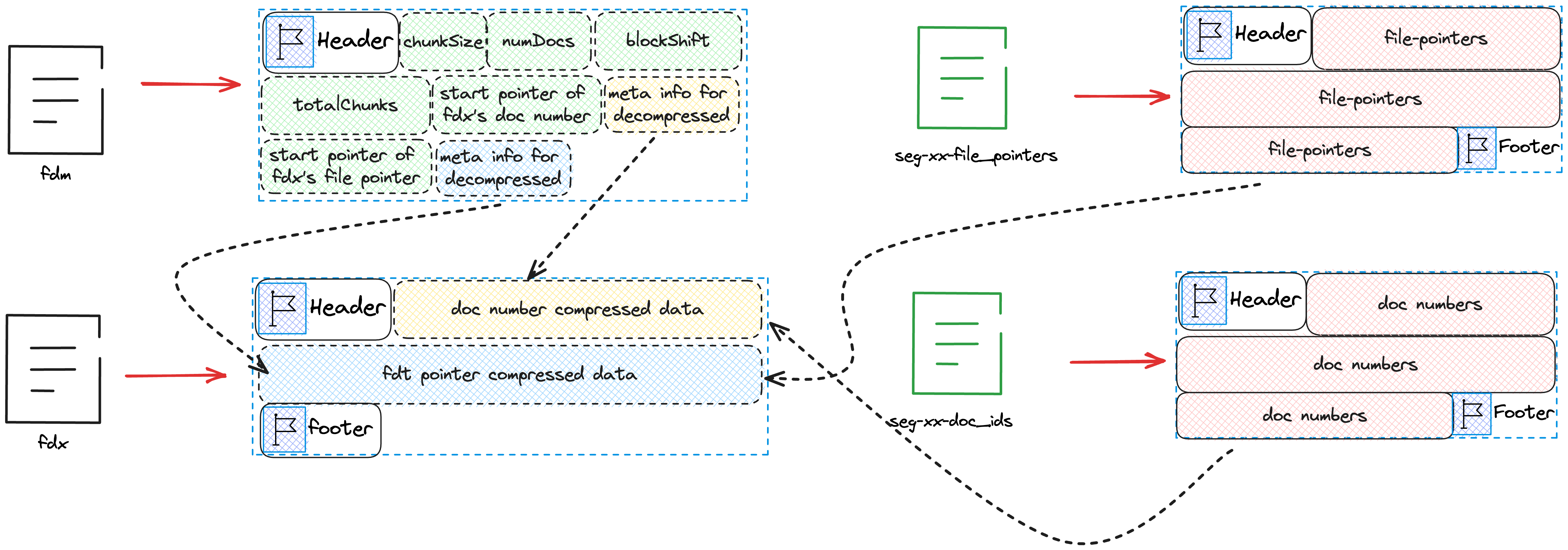
从图中,我们注意到fdm的Header后的chunkSize并没有在上述代码中体现,这是因为这个变量是在创建fdm时就写入的。
完成上述步骤后,我们只需要往fdm中写入numChunks,numDirtyChunks,numDirtyDocs
@Override
public void finish(int numDocs) throws IOException {
//skip...
metaStream.writeVLong(numChunks);
metaStream.writeVLong(numDirtyChunks);
metaStream.writeVLong(numDirtyDocs);
CodecUtil.writeFooter(metaStream);
CodecUtil.writeFooter(fieldsStream);
assert bufferedDocs.size() == 0;
}最后完整的的索引文件如下图所示
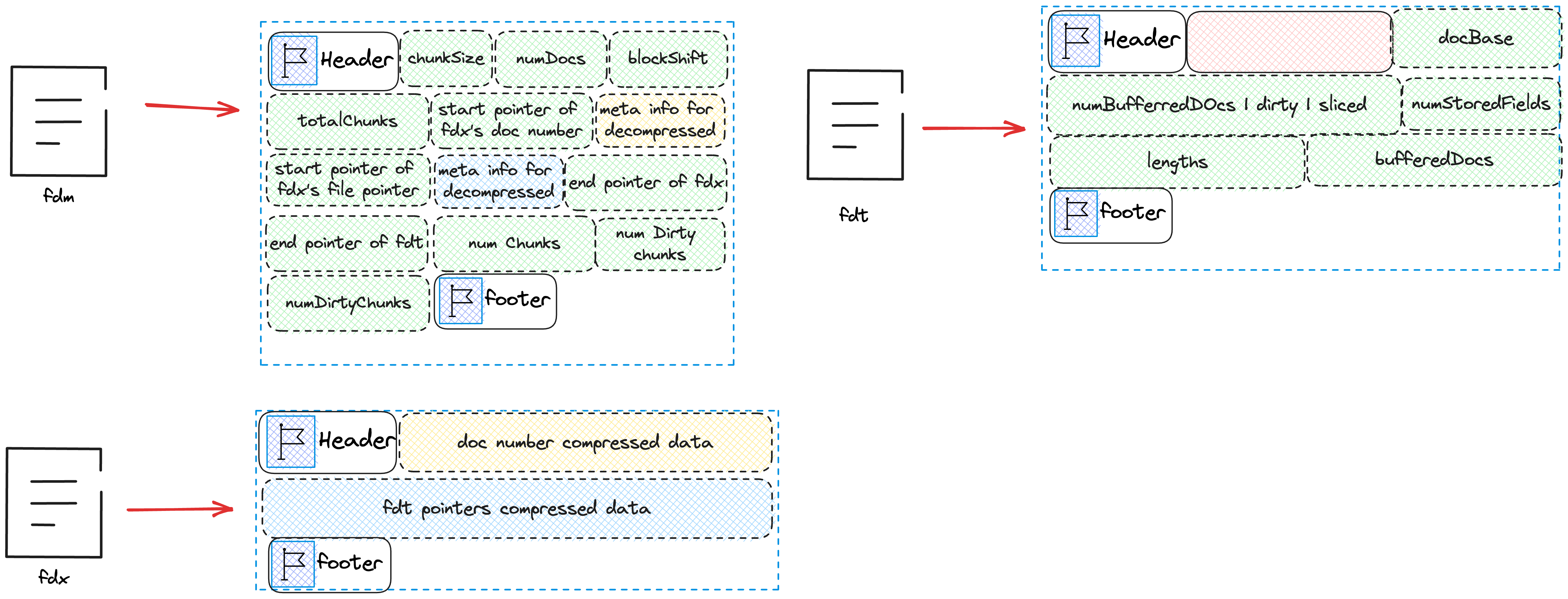
Overview
最后给出一张索引文件的概略以及相互的关系图