向量搜索和文本搜索一样,并不仅仅是在较低的延迟内找到准确的结果就够了——它们往往还需要在一定的限制条件下,也就是带着过滤,找到准确的答案。
而这对文本搜索来说并不是问题:倒排索引可以看作一个「哈希表 + 链表」的结构,我们只需要在遍历链表时,把不满足条件的文档顺手过滤掉即可。但向量搜索却很难妥善处理这种情况,下面我们会进一步展开。
注:我们这里说的向量搜索算法,专指类似 HNSW 这类基于图的算法。
为什么向量搜索很难过滤?
Post Filter
对于过滤,我们最直观的想法就是:先把结果算出来,再把其中不符合要求的直接丢弃。这的确是一个办法,但它和向量搜索有一个结构性的矛盾:向量搜索中并不存在「不符合要求」的向量,我们衡量的只是它们之间的相对距离, 所以对向量搜索来说,谈的都是 TopK(距离最近的前 K 个向量)。如果先算出 TopK 个向量,再按是否符合过滤条件对它们做过滤,最终返回的结果数就会变少,甚至变成空结果 (用户希望查到距离最近的 100 个向量,但返回的却只有 30 个、甚至 0 个;这并不是因为没有满足条件的向量,而是它们被过滤掉了)。
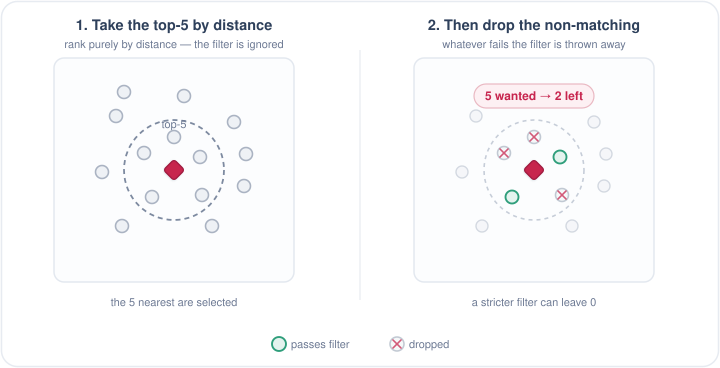
Post-filter ranks by distance first, then drops whatever fails the filter — the result can be far smaller than k, and a strict filter can leave nothing at all.
这个时候,我们又会很自然地想到:既然如此,那一开始就多搜一点——比如用户要 100 个,我们就先搜 1000 个,这样过滤之后,就能凑够 100 个返回给用户。 但这也会导致两个问题
- 扩召回会导致性能下降——搜索除了要召回正确的文档,还得保证在较低的延迟内完成
- 你无法保证扩召回后就一定有充足的结果返回给用户:如果过滤条件比较严格,哪怕把搜索量乘以 10,依然可能返回空结果
Pre Filter
既然搜索完再过滤会带来这么多问题,那我们可不可以反过来——先把符合过滤条件的向量全部找出来,再从中挑出距离最近的 TopK?
这个方法也能解决问题,但当我们把符合条件的向量全部挑出来后,就丢失了 HNSW 的图结构,只能对这些向量一个个计算距离。如果大多数点都符合过滤条件,这就无异于在整个数据集上做暴力搜索,延迟上是不可接受的。
不过 Pre Filter 也并非一无是处——它的代价高低,完全取决于过滤条件的命中率。 当条件很严格、只有少量向量符合时,候选集本身就很小,直接暴力计算反而最快;只有当命中率高、大部分向量都符合时,它才会退化成全库扫描。 换句话说,Post Filter 与 Pre Filter 各自只在一段命中率区间里好用——没有哪种做法能通吃所有场景。
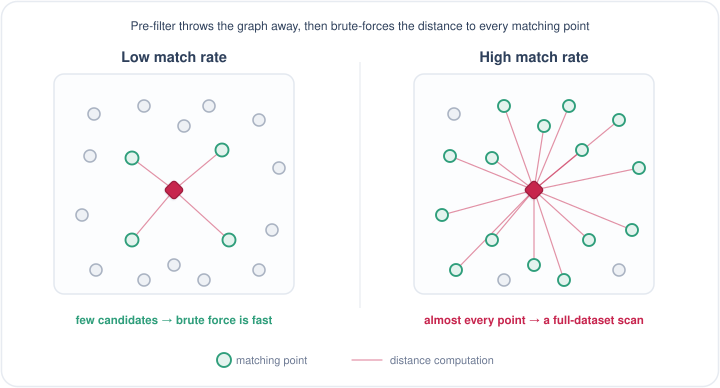
Pre-filter discards the graph and scans the matching points one by one: fast when few match, but it degrades into a near-full-dataset scan once most points pass.
目前主流的过滤算法
既然这两个朴素想法都不能很好地解决问题,下面就来看看目前在 HNSW 上主流的几种过滤算法。
注:下面会直接讲具体的过滤算法,默认你对 HNSW 本身的搜索流程已经有一定了解。
result-gate filtering
result-gate filtering 没有正式的名字,是 hnswlib 默认使用的做法。要讲清楚它,得先回顾一下 HNSW 在某一层里是怎么搜索的。
先看普通的 HNSW 搜索。 它会维护两个集合:
- candidate-set(候选集
C):还需要继续探索的点,决定「接下来往图的哪个方向走」; - result-set(结果集
W):当前找到的最近的若干个点,最终要返回给用户。
搜索就是不断从 C 里弹出离 query 最近的点 c,逐个看它的邻居 e:只要 e 比 W 里最远的点更近(或者 W 还没凑满 ef 个),就把 e 同时塞进 C 和 W。
SEARCH-LAYER(q, ep, ef):
C ← {ep} # candidate set, ordered by distance to q (nearest first)
W ← {ep} # result set, keeps the ef nearest found so far
visited ← {ep}
while C is not empty:
c ← extract nearest point to q from C
if dist(c, q) > dist(furthest in W, q):
break # cannot improve anymore, stop
for e in neighbors(c):
if e in visited: continue
visited.add(e)
if dist(e, q) < dist(furthest in W, q) or |W| < ef:
C.add(e) # admit to candidate set
W.add(e) # admit to result set
if |W| > ef: remove furthest from W
return W最初的HNSW算法, 我们判断一个点能不能进 C、能不能进 W,其实用的是同一个条件:它和 query 的距离够不够近。
那 result-gate filtering 要做的,其实就是判断一个点能不能进 C、能不能进 W 需要拆成两个不同的条件
进 candidate-set 的条件我们不进行改动,所以搜索的路由路径不变, 还是照原来的路走. 图的连通性也和没过滤的时候一样,不会因为过滤导致路由路径的质量恶化。
我们只在进 result-set 的时候多加了一个判断条件:除了距离要满足路径要求,还得满足过滤条件才行。代码上也就多一行:
for e in neighbors(c):
if e in visited: continue
visited.add(e)
if dist(e, q) < dist(furthest in W, q) or |W| < ef:
C.add(e) # admit to candidate set: unchanged
if filter(e): # ★ the only change
W.add(e) # admit to result set only if filter passes
if |W| > ef: remove furthest from W那这个过滤算法到底起了什么作用?首先,它的确仍然是在图上游走,而且游走的路径和无过滤情况下的搜索路径保持一致,这意味着它仍然在快速逼近 TopK 的结果,速度上有了保障。
而对于结果个数,因为 HNSW 只要 W 没凑够 ef 个就会接着往下搜,于是搜索就自己一直往外探,一直探到真的找够 ef 个满足条件的点、或者整张图都搜完为止。所以我们不会出现 Post Filter 那样的空结果情况。
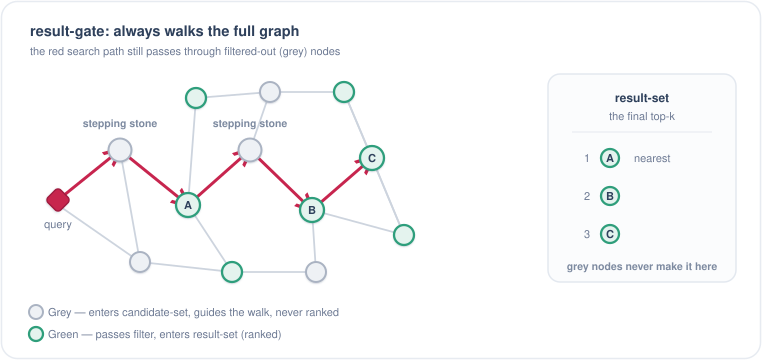
The search path still walks through the grey nodes — they enter the candidate-set and guide the walk — but only matching green nodes make it into the result-set. Guides the walk, never ranked.
ACORN
ACORN 来自这篇论文,文中提出了两种算法:ACORN-γ 和 ACORN-1。这里我们只讲 ACORN-1——因为 ACORN-γ 构图成本高、还得重建索引,现实中基本没有人使用;而 ACORN-1 可以直接跑在现成的 HNSW 索引上,实现成本很低。
ACORN-1 的思路其实很简单。我们要找的既然是满足过滤条件的 TopK,那干脆在搜索时就只把满足条件的点放进 candidate-set、只对这些点算距离,不满足条件的点直接不要。这和上一节的 result-gate 正好相反—- result-gate 不满足条件的点也会进 candidate-set 参与计算。这样做的好处是省下了大量的距离计算。
但这么做有个副作用:要是过滤条件很严、满足条件的点很稀疏,图的连通性就保不住了。HNSW 这张图原本每一个点都是连通的,现在把不满足条件的点全删掉,图就会被分割为一个个子图——很可能两个满足条件的点本来就靠一个不满足条件的点连接,这一删连接就断了。结果就是我们可能只在图的一小块里打转,怎么也走不出去。
为了解决这个问题,ACORN 使用了 Neighbor Expansion 来修复连通性。当我们走到一个点、去检查它的邻居时:邻居如果满足过滤条件,就照常算距离、放进 candidate-set;可如果这个邻居不满足条件,我们不直接把它扔掉,而是顺着它再往下看一跳,把它的邻居也拿出来检查。也就是说,不满足条件的点被我们当成一座「桥」,顺着它过去,看看是否还可以有别的符合条件的点。
这就是「两跳」的由来——第一跳走到不满足条件的邻居,第二跳到它背后满足条件的点,因为过滤条件无法连通的两个点就这样又连接上了。
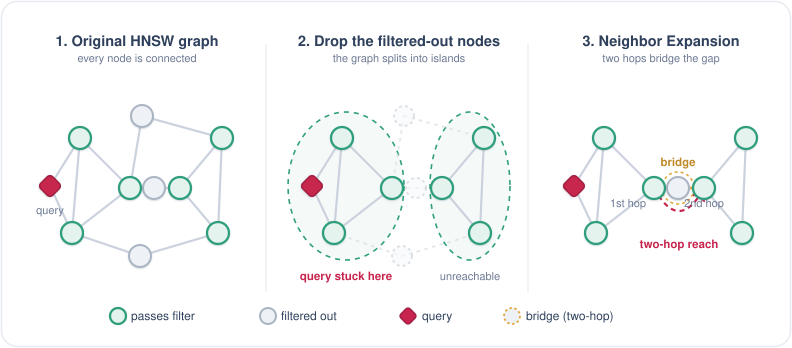
① the full graph is connected → ② keeping only the matching nodes shatters it into islands and traps the query → ③ Neighbor Expansion bridges the grey nodes in two hops to reconnect the far side.
所以 ACORN-1 一边靠「只算满足条件的点」省下大量距离计算,一边靠两跳的 Neighbor Expansion 把连通性补回来,以此希望达到可以快速的完成过滤搜索
尽管 ACORN 的思路很吸引人,但要真正在生产环境里落地,还得做一些工程化改造,最典型的就是 Lucene 的实现。Lucene 在 ACORN 的基础上主要做了三点改造:
- 按需扩展(lazy expansion):原始 ACORN 是无条件做两跳的——不管满足条件的邻居够不够用,它都会去对不满足条件的邻居做扩展。Lucene 认为这其实没必要,而是改成按需扩展:先对满足条件的邻居算距离,如果这一跳里合格的邻居已经够多,就无需再扩展;只有当合格的邻居不够时,才对不满足条件的邻居做二跳。这样既保住了连通性,又省下大量没必要的扩展。
- 多跳:如果发现图的连通性特别差,光二跳还不够,它会继续三跳、四跳,直到凑够足够的合格点。
- explore budget(探索预算):给探索量设一个上限,并根据
selectivity动态调整,避免在极端情况下无止境地探索下去。
在我自己的实验里,前两点相比原始 ACORN 都有小幅提升,但第三点 explore budget 反而更差。我认为原因是设了上限之后,检索延迟的确更可预期了,极端情况下不会出现 tail latency 爆炸;但代价是路由质量变差了——budget 虽然限制了每一步的探索量,却让搜索更容易走偏,为了凑到同样的 recall,整张图反而要多访问很多点,平均延迟也就上去了。
下面这张图把三条 qps-recall 曲线放在一起对比:带 explore budget 的 ACORN、不带的,以及原始论文版。可以看到,不带的那版反而最好。所以下一节做过滤算法比较时,我们用的就是这版不带 explore budget 的 ACORN,拿它和 result-gate 对比。
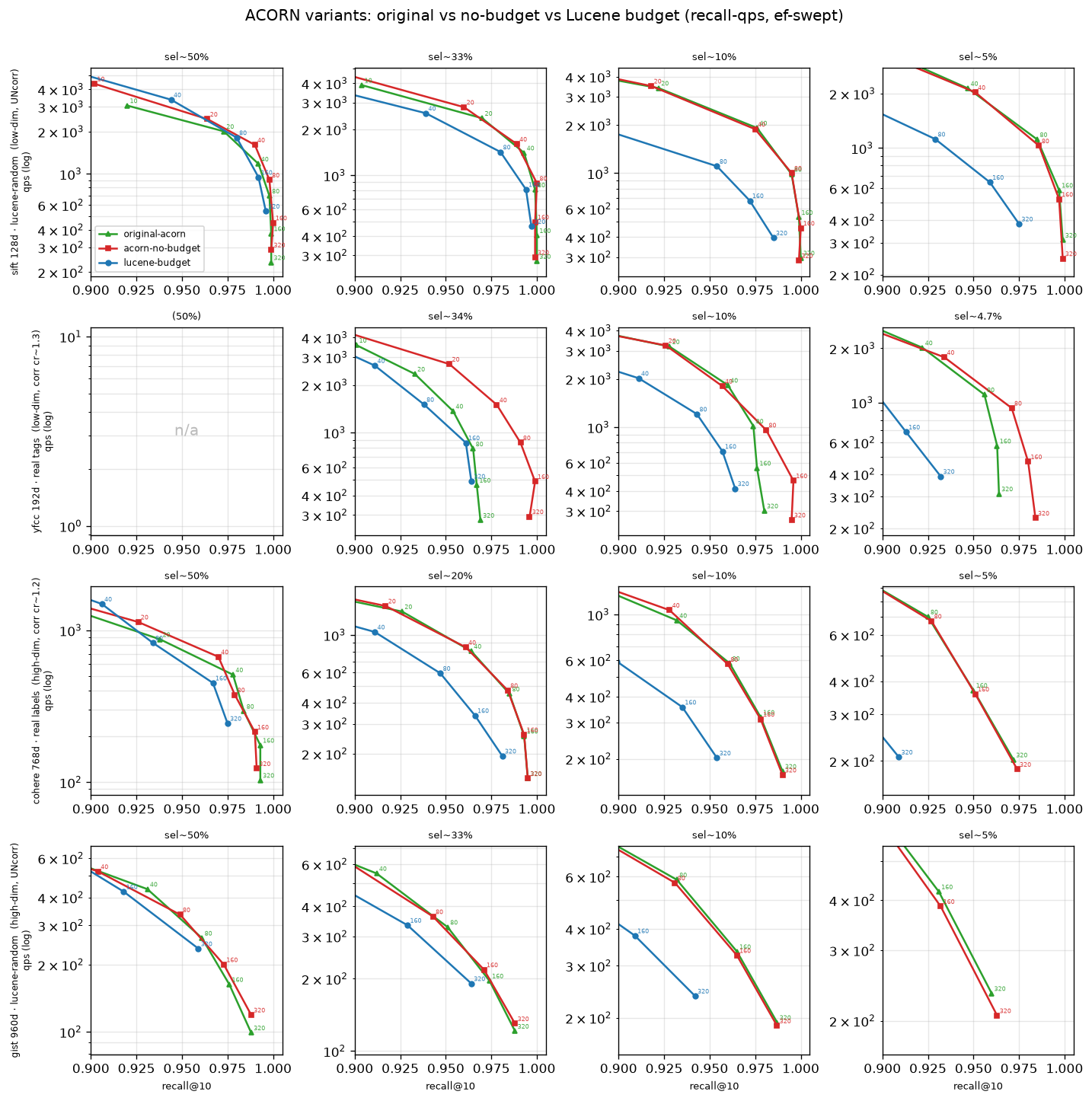
过滤算法的比较
在正式比较之前,先说一下用到的数据集和它们的过滤条件:
- SIFT1M / GIST1M:被过滤的点是我们随机挑的(随机 filter);
- YFCC1M:用数据集自带的真实 image tag 当 filter;
- Cohere1M:用数据集自带的真实 scalar label 当 filter。
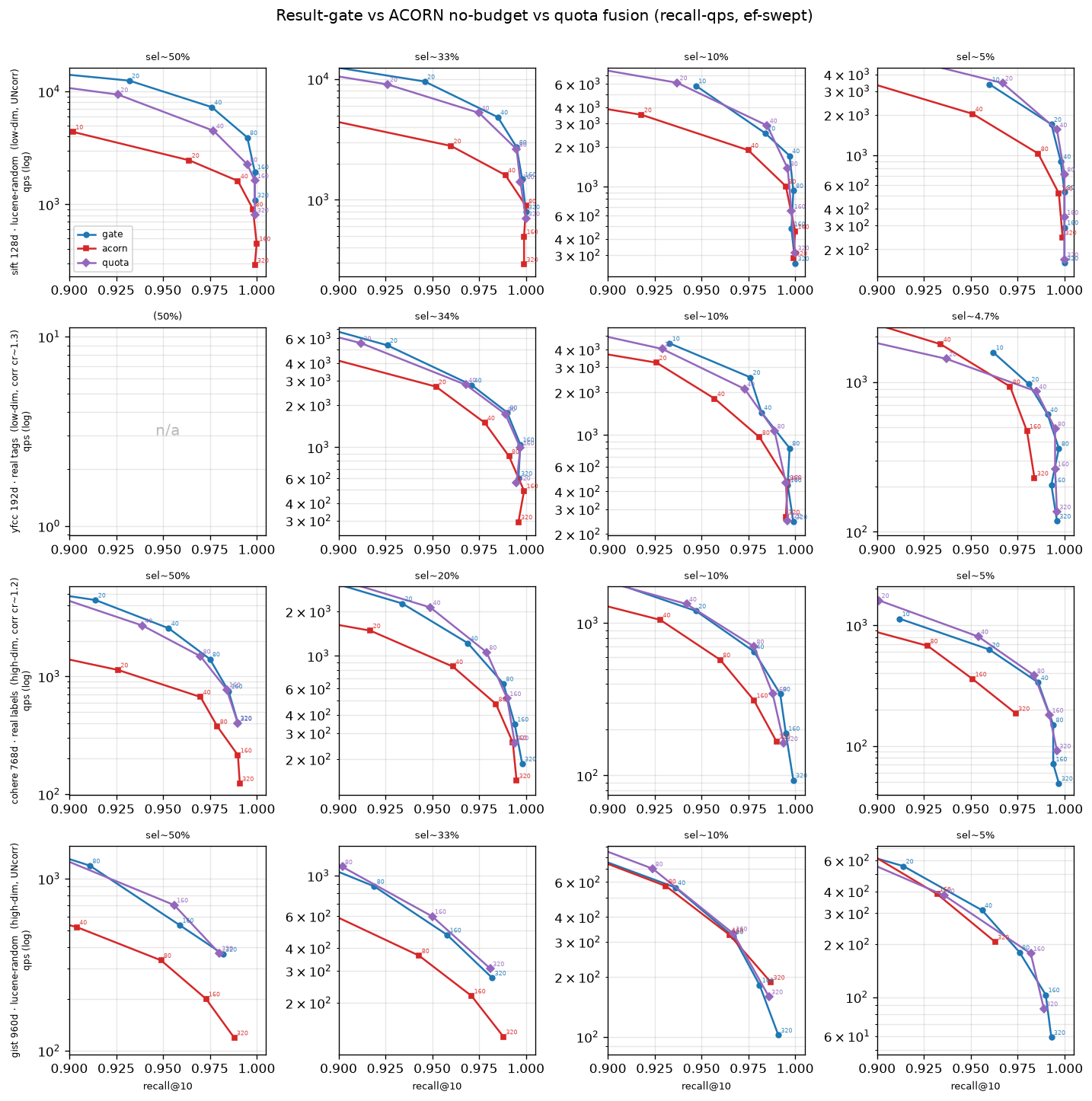
我们先看 ACORN 和 result-gate 在这四个数据集上的对比:
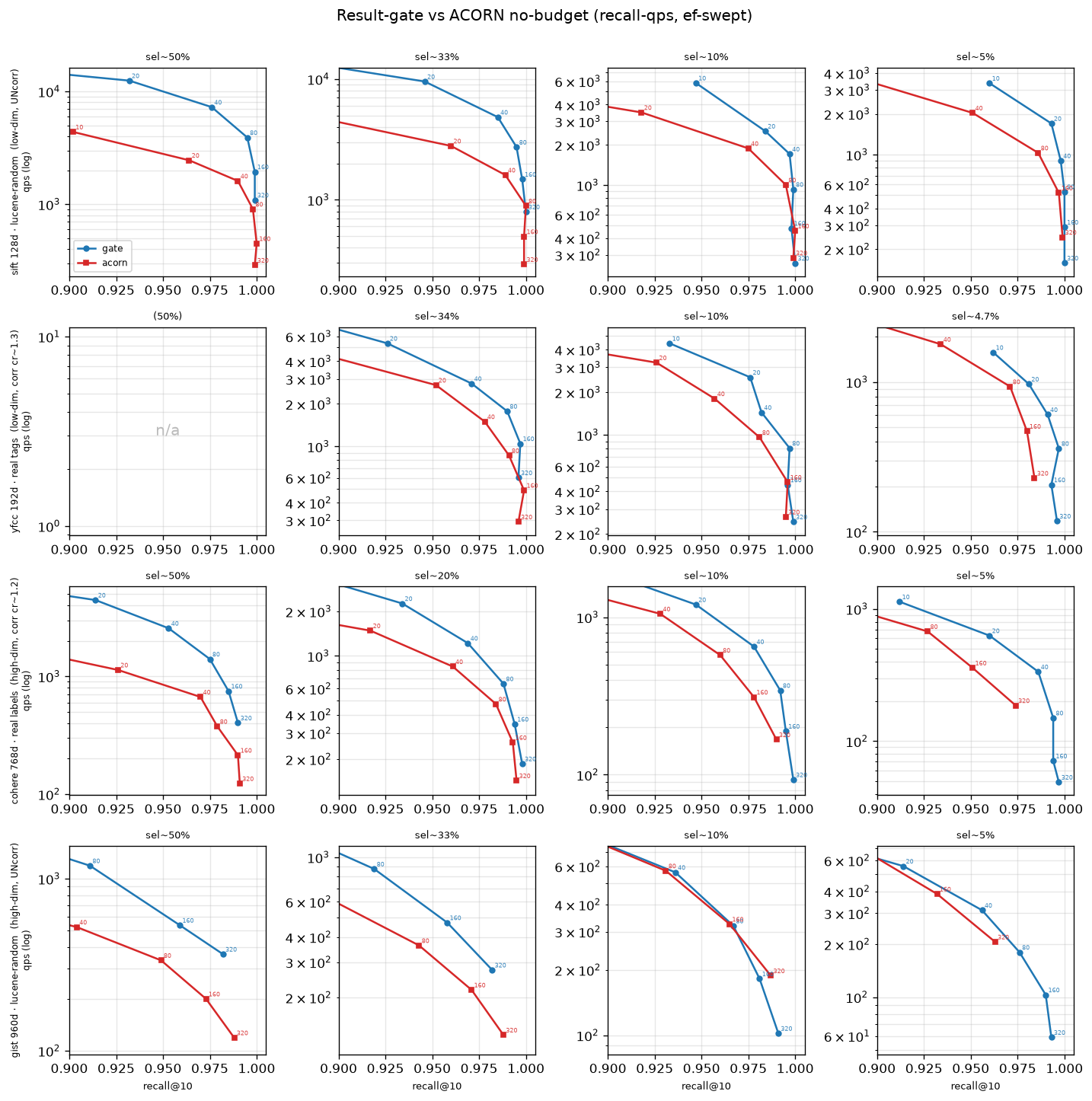
从图里能看到,在相同召回率下,大多数情况 ACORN 都打不过 result-gate。那这是为什么呢?明明ACORN大费周章就是为了少算几个距离,为什么性能还是比不过result-gate呢? 原因有两个。
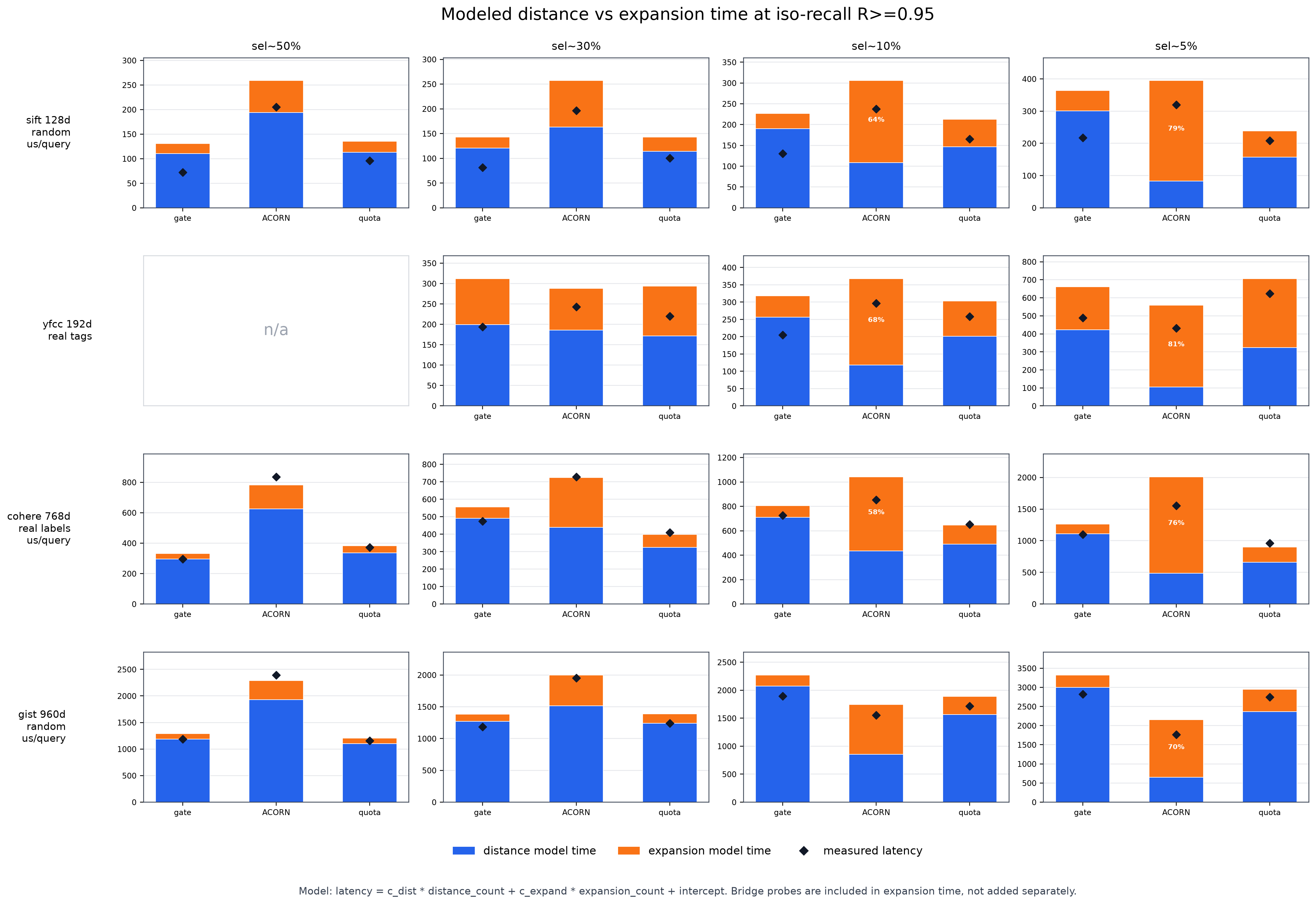
根因一:HNSW 的瓶颈在访存,而不在距离计算。
我们如果去看 HNSW 搜索时的热点函数,会发现绝大部分耗时都落在距离计算上。但这并不代表时间真的花在了 CPU 算距离上——实际上它大部分时间还是花在了访存上(把向量从内存里取出来)。 对 SIFT、YFCC 这种维度比较低的数据集,如果使用 SIMD + prefetch,一次距离计算要碰的内存很少。所以 ACORN 少算几次距离省下的那点收益抵不过它做节点扩展(多访存、多跳指针)的开销。 从下图就能看出来:距离计算的时间确实大幅下降了,但扩展的时间涨得更多。
根因二:ACORN 省了距离计算,但路由质量也跟着变差了。
低维数据上距离便宜、ACORN 占不到便宜,这能理解。可为什么到了高维数据上,ACORN 还是赢不了 result-gate?
问题出在路由上。ACORN 只在「满足过滤条件的点」里游走,相当于在一张被掏空、再用两跳勉强补起来的稀疏图上导航;
而 result-gate 始终走在原本那张完整的图上(不满足条件的点还能帮忙带路)。所以 ACORN 的路由质量天生就比 result-gate 差,想达到同样的召回,就得把 ef 调得更大——而 ef 一大,延迟自然就上去了。
下图能看出搜索过程中两者的差别。
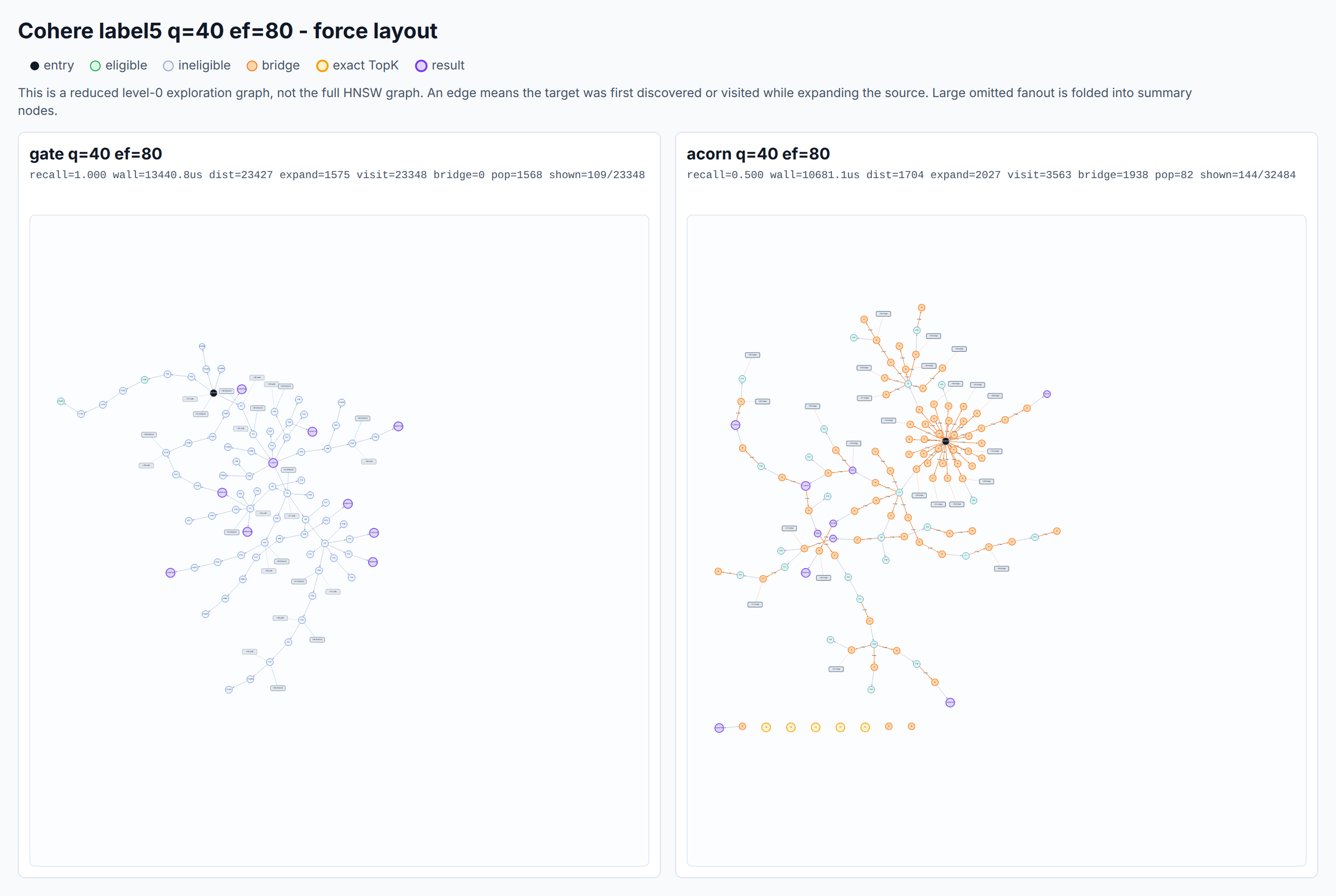
所以总结一下,ACORN 想赢过 result-gate,需要同时满足几个条件:
- 向量维度够高
- 过滤条件够严(命中率低、只有少量点能通过)
- 过滤条件要和向量分布相关——也就是满足过滤条件的点,彼此在向量空间里也得离得近。
前两点好理解,第三点稍微解释一下。举个例子:你的向量是按音乐 embedding 算的,那过滤条件最好也跟音乐相关。因为 ACORN 这套算法能成立,本身就隐含了一个前提——满足过滤条件的点,自己也是抱团聚集的。 要是过滤条件和向量完全无关,满足条件的点散落在图的各个角落,ACORN 的两跳很难把它们串起来,效果自然好不了。
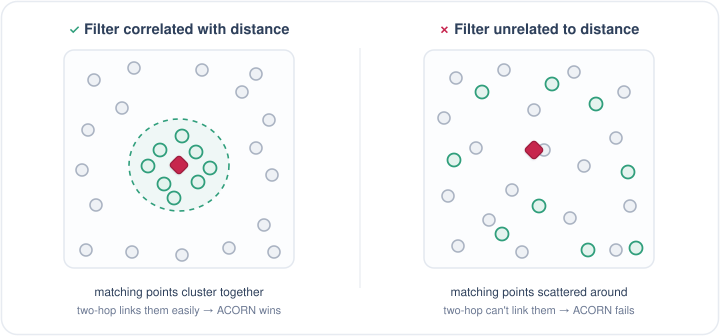
Left: the matching points cluster, so two-hop links them and ACORN wins. Right: the matching points are scattered, two-hop can’t reach them, and ACORN fails.
One More Thing
计算机里有个很重要的思想叫「融合」——把两个方法融合到一起,变成一个更好的。顺着这个思路,我们可以思考一个把 result-gate 和 ACORN 结合起来的算法(尽管实测它也没能稳赢这两者)
它的想法是这样的:ACORN 路由差,原因在于它只把满足过滤条件的点放进 candidate-set。那我们可以折中一下——遍历一个点的邻居时,先只算满足条件的点;
如果够多,就照 ACORN 的方式走下去;如果不够,就退回 result-gate 的做法,直接去访问那些不满足条件的点,借它们把路由质量补回来。
这样就只剩一个问题:到底要凑够多少个满足条件的点,才算「够多」、可以不去碰不满足条件的点?
这里可以用一点概率论来估这个阈值。直觉是:只要一跳邻居里能提供方向的点足够多,就有很高概率已经覆盖到了前 p% 的近邻,这时就不必再去碰不满足条件的点了。完整的推导我放在了文末的附录里,这里直接给结论——我们用一个随命中率 自适应的经验阈值:过滤条件越宽松,满足条件的邻居本来就越多;过滤条件越严格,它就自动补上越多 result-gate 式的路由能力。
三个算法的对比如下。
结论
说了这么多,结论其实就四个字:没有银弹。没有哪个算法能在所有场景下稳赢,唯一能做的就是按照自己的 workload,挑一个最合适的
如果你压根不清楚自己的 workload 长什么样,那就无脑选 result-gate:实现最简单,效果还很好。
附录:融合算法的阈值推导
假设 level-0 每个点最多有 个邻居,过滤条件的命中率是 。那么一个点的一跳邻居里,期望会有 个点满足过滤条件。它们本来就会被 ACORN 算距离;如果我们希望每一步至少拿到 个可以提供路由方向的邻居,那就只需要从不满足过滤条件的邻居里额外补:
个点。
接下来要估的是:补 个点,能不能大概率碰到一个“足够好的路由方向”。如果我们把当前邻居里距离 query 最近的前 比例看作好方向,那么从 个邻居里抽 个,至少命中一个好方向的概率是:
反过来,如果希望命中概率至少是 ,那么:
比如取 、,在 时,大约补 9 到 11 个邻居就能有很高概率碰到前 25% 的近邻方向。
不过最后我们没有直接把这个理论值硬套进去,因为它偏保守。实测下来,更好的经验阈值是:
也就是说:先把期望中的满足条件邻居算进去,再额外补一个和 无关的小常数项,作为路由方向的“保底样本”。当过滤条件很宽松时,满足条件的邻居本来就够多;当过滤条件很严格时,这个额外项会补上一点 result-gate 式的路由能力。